一、主从复制的概念
redis为了高可用,会把数据复制到多个副本,部署到其他节点上。通过复制,实现redis的高可用性,实现对数据的冗余备份保证数据和服务的可靠性。
数据的复制是单向的,只能由master节点到slave节点。下图描述了一个简单的主从复制架构。
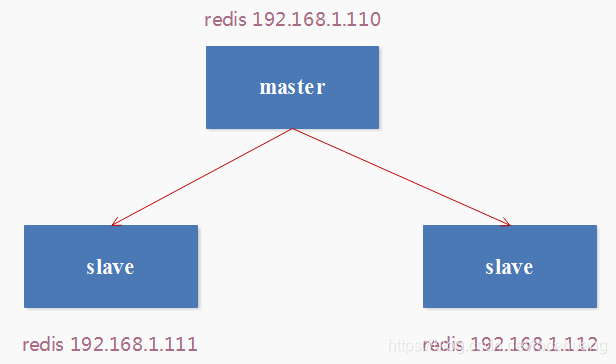
主从复制的作用
1)数据冗余
主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
2)故障恢复
当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
3)负载均衡
在主从复制的基础上,配合读写分离,可以由主节点提供写服务,从节点提供读服务(即写在Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
4)读写分离
可以用于读写分离,主库写、从库读,读写分离不仅可以提高服务器的负载能力,同时可根据需求的变化,改变从库的数量。
5)高可用基石
除了上述4点作用外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
二、主从复制机制
Redis的主从复制功能除了支持一个Master节点对应多个Slave节点的同时进行复制外,还支持Slave节点向其它多个Slave节点进行复制。这样就使得架构师能够灵活组织业务缓存数据的传播,例如使用多个Slave作为数据读取服务的同时,专门使用一个Slave节点为流式分析工具服务。
Redis的主从复制功能分为两种数据同步模式进行:全量数据同步和增量数据同步。
1、全量数据同步
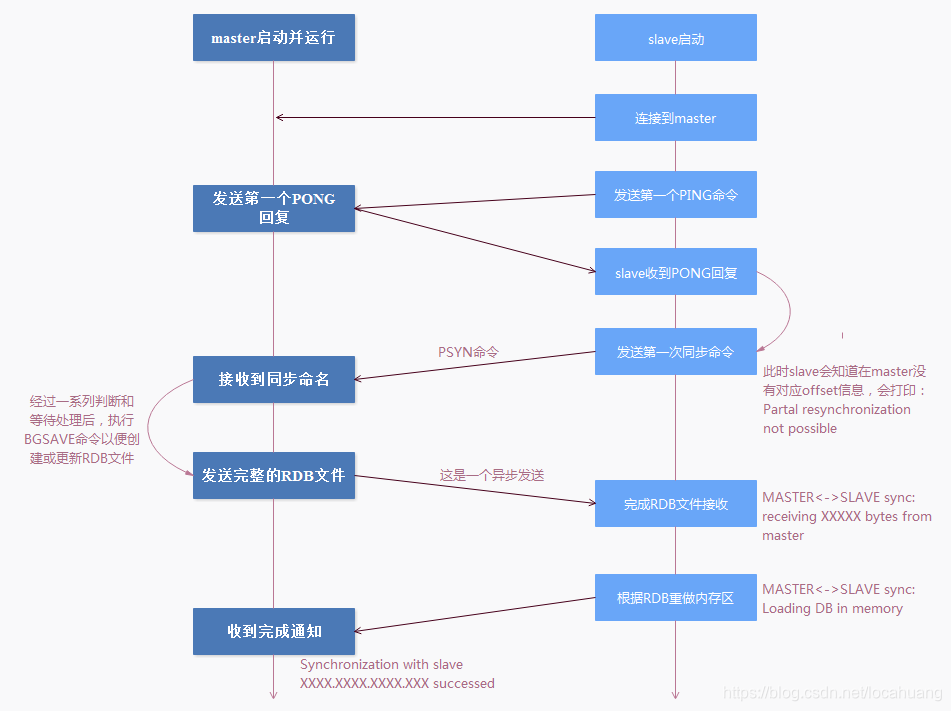
上图简要说明了Redis中Master节点到Slave节点的全量数据同步过程。
什么时候进行全量同步?
1)当Slave节点给定的replication id和Master的replication id不一致时;
2)或者Slave给定的上一次增量同步的offset的位置在Master的环形内存中(replication backlog)无法定位时。
Master就会对Slave发起全量同步操作。
全量同步的时候,无论是否在Master打开了RDB快照功能,它和Slave节点的每一次全量同步操作过程都会更新/创建Master上的RDB文件。
在Slave连接到Master,并完成第一次全量数据同步后,接下来Master到Slave的数据同步过程一般就是增量同步形式了(也称为部分同步)。增量同步过程不再主要依赖RDB文件,Master会将新产生的数据变化操作存放在replication backlog这个内存缓存区,这个内存区域是一个环形缓冲区,也就是说是一个FIFO的队列。
特点:
- 主节点通过BGSAVE命令fork子进程进行RDB持久化,该过程是非常消耗CPU、内存(页表复制)、硬盘IO。
- 主节点通过网络将RDB文件发送给从节点,对主节点的带宽都会带来很大的消耗。
- 从节点清空数据、载入新RDB文件的过程是阻塞的,无法响应客户端的命令;如果从节点执行bgrewriteaof,也会带来额外的消耗。
2、增量数据同步
Redis2.8开始提供部分复制,用于处理网络中断时的数据同步。
进行增量同步 — master作为一个普通的client连入slave,将所有写操作转发给slave,没有特殊的同步协议。具体过程如下:
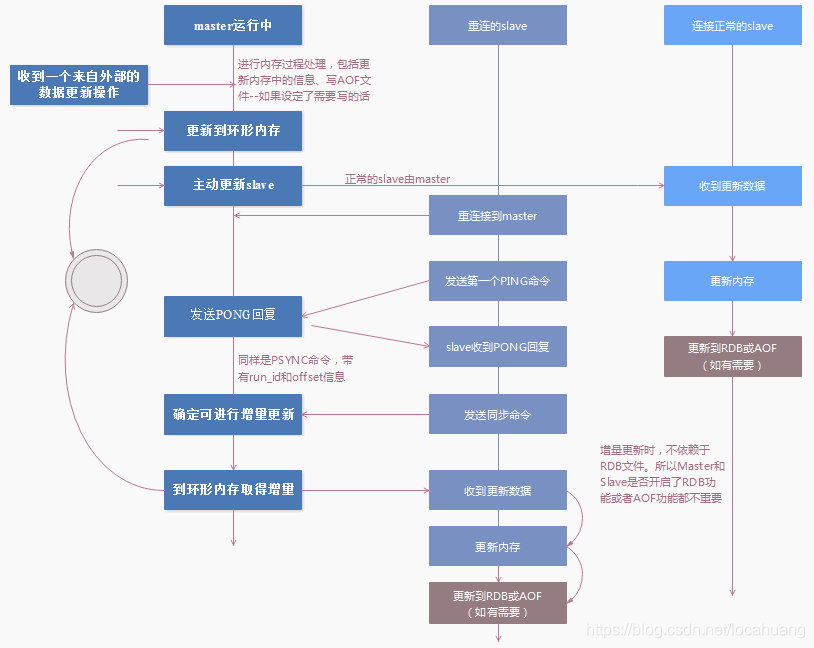
问:为什么在Master上新增的数据除了根据Master节点上RDB或者AOF的设置进行日志文件更新外,还会同
时将数据变化写入一个环形内存结构(replication backlog),并以后者为依据进行Slave节点的增量更新呢?主要原因有以下几个:
1)由于网络的不稳定,网络抖动/延迟都可能造成slave和master暂时断开连接,这种情况远多于新的slave连接到master的情况。如果以上所有情况都使用全量更新,就会大大增加master的负载压力–写RDB文件是有大量I/O过程的,虽然Linux Page Cache特性会减少性能消耗。
2)另外在数据量达到一定规模的情况下,使⽤全量更新进行和Slave的第一次同步是一个不得已的选择–因为要尽快减少Slave节点和Master节点的数据差异。所以只能占用Master节点的资源和网络带宽资源。
3)使用内存记录数据增量操作,可以有效减少Master节点在这方面付出的I/O代价。而做成环形内存的原因,是为了保证在满⾜数据记录需求的情况下尽可能减少内存的占用量。这个环形内存的大小,可以通过repl-backlog-size参数进行设置
Slave重连后会向Master发送之前接收到的Master replication id信息和上一次完成部分同步的offset的位置信息。如果Master能够确定这个replication id和自己的replication id(有两个)一致且能够在环形内存中找到这个offset的位置,Master就会发送从offset的位置开始向Slave发送增量数据。
问:连接正常的各个Slave节点如何接受新数据呢?
连接正常的Slave节点将会在Master节点将数据写入环形内存后,主动接收到来自Master的数据复制信息。
问:Replication backlog的size设置多大合适呢?
redis为Replication backlog设置的默认大小为1M,这个值可以调整。如果主服务需要执行大量的写命令,又或者主服务之间断线后重连的时间比较长,那么这个大小也许不合适。如果replication backlog的大小设置不恰当,那么PSYNC命令的复制同步模式就不能正常发
挥作用,因此,正确估算和设置replication backlog的size非常重要。
计算参考公式:size = reconnect_time_second * write_size_per_second*2
例如如果网络中断的平均时间是60s,而主节点平均每秒产生的写命令(特定协议格式)所占的字节数为100KB,则复制积压缓冲区的平均需求为6MB,保险起见,可以设置为12MB,来保证绝大多数断线情况都可以使用部分复制。
三、主从复制实现
1、主从复制的开启,完全是从节点发起的,不需要在主节点上做任何事情。
开启主从复制有3种方式:
1)方式1–修改配置文件
配置文件修改的是从节点的redis.conf文件,在配置文件中加入:slaveof <masterip> <masterport>
2)方式2–使用启动命令
启动从节点时,redis-server启动命令后加入 --slaveof <masterip> <masterport>

3)方式3–使用客户端命令
从节点Redis服务器启动后,直接通过客户端执行命令:slaveof <masterip> <masterport>,则该Redis实例成为从节点。

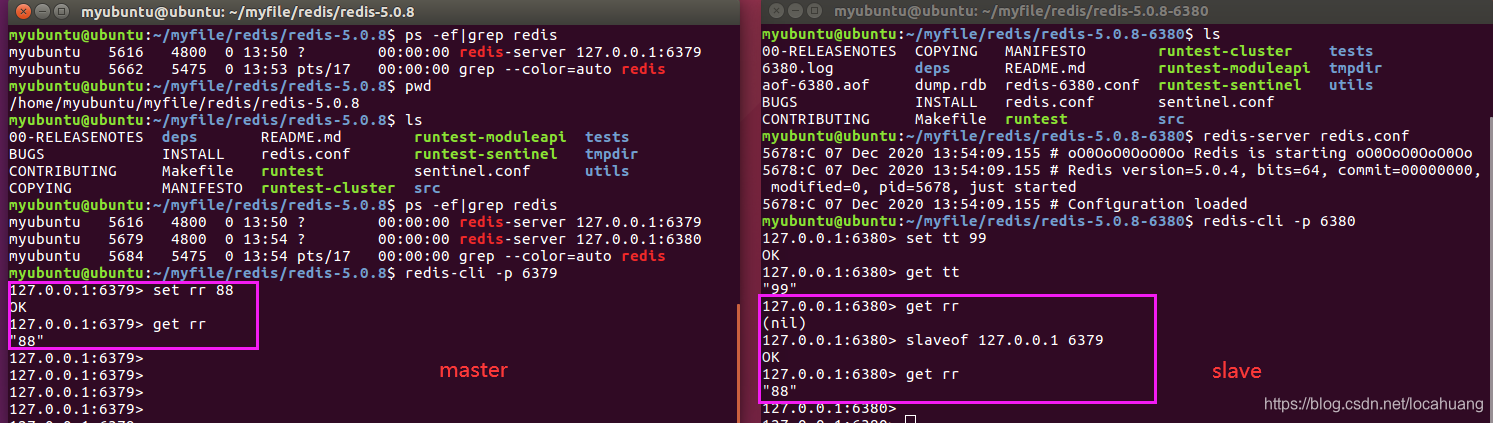
2、主从复制效果展示:
1)使用info replication指令分别查看master和slave的redis信息,如下图。
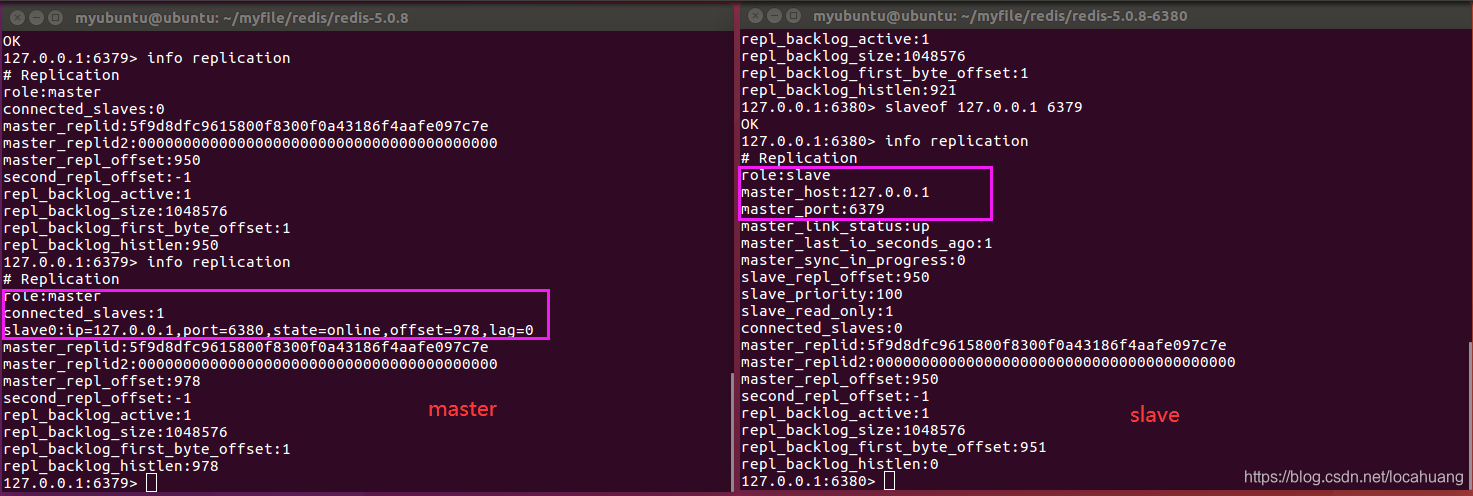
2)实现主从复制后,在master端写入数据,在slave也可以读到对应的数据。
3、Slaveof命令操作内容
- 判断当前环境是否在集群模式下,因为集群模式下不执行该命令。
- 是否执行的是SLAVEOF NO ONE命令,该命令会断开主从的关系,设置当前节点为主节点服务器。
- 设置从节点所属主节点的IP和port。调用了replicationSetMaster()函数。
redis-5.0.8 Slaveof命令实现源码阅读:

void replicaofCommand(client *c) {
/* SLAVEOF is not allowed in cluster mode as replication is automatically
* configured using the current address of the master node. */
if (server.cluster_enabled) {
//如果是集群模式 ,则退出,不执行
addReplyError(c,"REPLICAOF not allowed in cluster mode.");
return;
}
/* The special host/port combination "NO" "ONE" turns the instance
* into a master. Otherwise the new master address is set. */
if (!strcasecmp(c->argv[1]->ptr,"no") &&
!strcasecmp(c->argv[2]->ptr,"one")) {
if (server.masterhost) {
replicationUnsetMaster(); //取消原来的复制操作
sds client = catClientInfoString(sdsempty(),c);
serverLog(LL_NOTICE,"MASTER MODE enabled (user request from '%s')",
client);
sdsfree(client);
}
} else {
long port;
if (c->flags & CLIENT_SLAVE)
{
/* If a client is already a replica they cannot run this command,
* because it involves flushing all replicas (including this
* client) */
addReplyError(c, "Command is not valid when client is a replica.");
return;
}
if ((getLongFromObjectOrReply(c, c->argv[2], &port, NULL) != C_OK))
return;
/* Check if we are already attached to the specified slave */
if (server.masterhost && !strcasecmp(server.masterhost,c->argv[1]->ptr)
&& server.masterport == port) {
serverLog(LL_NOTICE,"REPLICAOF would result into synchronization with the master we are already connected with. No operation performed.");
addReplySds(c,sdsnew("+OK Already connected to specified master\r\n"));
return;
}
/* There was no previous master or the user specified a different one,
* we can continue. */
replicationSetMaster(c->argv[1]->ptr, port); //设置服务器复制操作的主节点IP和端⼝
sds client = catClientInfoString(sdsempty(),c);
serverLog(LL_NOTICE,"REPLICAOF %s:%d enabled (user request from '%s')",
server.masterhost, server.masterport, client);
sdsfree(client);
}
addReply(c,shared.ok);
}
//replicationSetMaster函数
/* Set replication to the specified master address and port. */
void replicationSetMaster(char *ip, int port) {
int was_master = server.masterhost == NULL;
//清除原来的主节点
sdsfree(server.masterhost);
//设置新的IP和端口
server.masterhost = sdsnew(ip);
server.masterport = port;
//释放其他主节点
if (server.master) {
freeClient(server.master);
}
//解除所有客户端的阻塞状态
disconnectAllBlockedClients(); /* Clients blocked in master, now slave. */
/* Force our slaves to resync with us as well. They may hopefully be able
* to partially resync with us, but we can notify the replid change. */
//关闭所有从节点服务器的连接,强制从节点服务器进行重新同步操作
disconnectSlaves();
//取消执行复制操作
cancelReplicationHandshake();
/* Before destroying our master state, create a cached master using
* our own parameters, to later PSYNC with the new master. */
if (was_master) {
replicationDiscardCachedMaster(); //释放主节点结构的缓存,不会执行部分重同步PSYNC
replicationCacheMasterUsingMyself();
}
server.repl_state = REPL_STATE_CONNECT; //设置复制必须重新连接主节点的状态
}
slaveof命令是一个异步命令,执行命令的时候,从节点保存主节点的信息,确立主从关系后会立即返回,后续的复制流程在节点内部异步执行。那么如何触发复制的执行呢?
周期性执行的函数:replicationCron()函数,该函数被服务器的时间事件的回调函数serverCron()所调用,而serverCron()函数在Redis服务器初始化时,被设置为时间事件的处理函数。
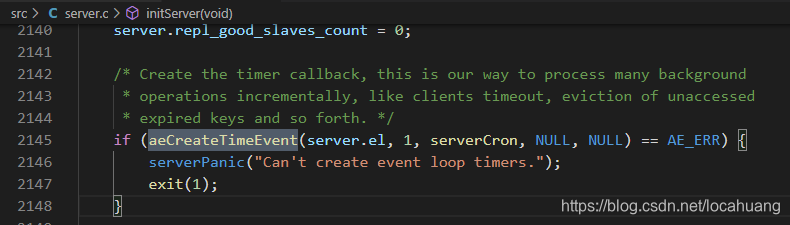
replicationCron这个函数每秒执行一次。

replicationCron()函数处理这以情况的代码如下:
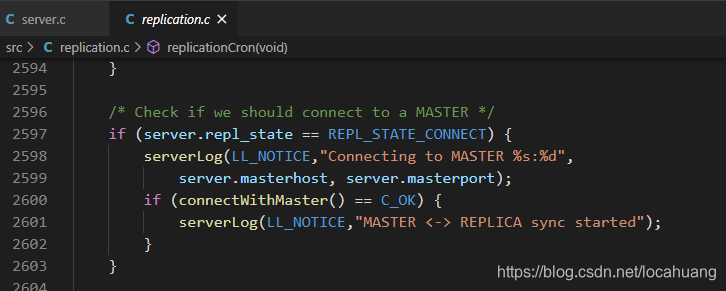
replicationCron()函数根据从节点的状态,调用connectWithMaster()非阻塞连接主节点。代码如下:
//以非阻塞的方式连接主节点
int connectWithMaster(void) {
int fd;
//连接主节点
fd = anetTcpNonBlockBestEffortBindConnect(NULL,
server.masterhost,server.masterport,NET_FIRST_BIND_ADDR);
if (fd == -1) {
serverLog(LL_WARNING,"Unable to connect to MASTER: %s",
strerror(errno));
return C_ERR;
}
//监听主节点fd的可读和可写事件的发生,并设置其处理程序为syncWithMaster
if (aeCreateFileEvent(server.el,fd,AE_READABLE|AE_WRITABLE,syncWithMaster,NULL) ==
AE_ERR)
{
close(fd);
serverLog(LL_WARNING,"Can't create readable event for SYNC");
return C_ERR;
}
//最近一次读到RDB文件内容的时间
server.repl_transfer_lastio = server.unixtime;
//从节点和主节点的同步套接字
server.repl_transfer_s = fd;
//处于和主节点正在连接的状态
server.repl_state = REPL_STATE_CONNECTING;
return C_OK;
}
4、主从复制的相关参数配置
1)主节点相关配置
-
repl-timeout 60:与各个阶段主从节点连接超时判断有关。 -
repl-diskless-sync no:作用于全量复制阶段,控制主节点是否使用diskless复制(无盘复制)。diskless复制,是指在全量复制时,主节点不再先把数据写入RDB文件,而是直接写入slave的socket中,整个过程中不涉及硬盘;diskless复制在磁盘IO很慢而网速很快时更有优势。需要注意的是,截至Redis3.0,diskless复制处于实验阶段,默认是关闭的。 -
repl-diskless-sync-delay 5:该配置作用于全量复制阶段,当主节点使用diskless复制时,该配置决定主节点向从节点发送之前停顿的时间,单位是秒;只有当diskless复制打开时有效,默认5s。之所以设置停顿时间,是基于以下两个考虑:(1)向slave的socket的传输一旦开始,新连接的slave只能等待当前数据传输结束,才能开始新的数据传输 (2)多个从节点有较大的概率在短时间内建立主从复制。 -
client-output-buffer-limit slave 256MB 64MB 60:与全量复制阶段主节点的缓冲区大小有关。 -
repl-disable-tcp-nodelay no:与命令传播阶段的延迟有关。 -
masterauth <master-password>:与连接建立阶段的身份验证有关。 -
repl-ping-slave-period 10:与命令传播阶段主从节点的超时判断有关。 -
repl-backlog-size 1MB:复制积压缓冲区的大小。 -
repl-backlog-ttl 3600:当主节点没有从节点时,复制积压缓冲区保留的时间,这样当断开的从节点重新连进来时,可以进行部分复制;默认3600s。如果设置为0,则永远不会释放复制积压缓冲区。 -
min-slaves-to-write 3与min-slaves-max-lag 10:规定了主节点的最小从节点数目,及对应的最大延迟。
2)从节点相关配置
slaveof <masterip> <masterport>:Redis启动时起作用;作用是建立复制关系,开启了该配置的Redis服务器在启动后成为从节点。该注释默认注释掉,即Redis服务器默认都是主节点。repl-timeout 60:与各个阶段主从节点连接超时判断有关。slave-serve-stale-data yes:与从节点数据陈旧时是否响应客户端命令有关。slave-read-only yes:从节点是否只读;默认是只读的。由于从节点开启写操作容易导致主从节点的数据不一致,因此该配置尽量不要修改。
四、主从复制需要注意的问题
1、持久化问题
确保master激活了持久化,或者确保它不会在当掉后自动重启。
因为slave是master的完整备份,因此如果master通过一个空数据集重启,slave也会被清掉。
2、密码问题
在配置redis复制功能的时候如果主数据库设置了密码,需要在从数据的配置文件中通过masterauth参数设置主数据库的密码,这样从数据库在连接主数据库时就会自动使用auth命令认证了。相当于做了一个免密码登录。
3、读写分离问题
1)延迟与不一致问题
主从复制是异步的,延迟与数据不一致不可避免。可优化措施:
1)优化主从之间的网络。
2)监控主从节点延迟(通过offset判断),如果从节点延迟过大,通知应用不再通过该从节点读取数据。
3)使用集群同时扩展写负载和读负载等。
2)数据过期问题
单机redis采用的删除策略:惰性删除、定期删除。
惰性删除:服务器不主动删除数据,只有当客户端查询某个数据时,服务器判断数据是否过期来决定是否删除。
定期删除:执行定时任务删除过期数据,对内存和CPU有影响,删除频率和执行时间有限制。
主从复制:为了主从数据一致性,由主节点控制从节点中过期数据的删除。由于主节点的惰性删除和定期删除都不能保证及时对过期数据执行删除操作,因此当客户端通过redis从节点读取数据的时候,很容易读到已经过期的数据。
3)故障切换
没有使用哨兵的读写分离场景下,应用针对读和写分别连接不同的redis节点;当主节点或从节点出现问题而发生改变时,需要及时修改应用程序读写redis的连接;连接的切换可以手动进行,或者自己写监控程序进行切换。
4、复制超时问题
设置超时意义
- 主节点释放从连接,释放资源。避免无效连接占用输出缓冲区、带宽、连接等。
- 从节点超时, 重新建立连接,避免与主节点数据不一致。
引出的问题
1)数据同步阶段
问题描述:如果RDB文件过大,主节点在fork子进程+保存RDB文件时耗时过多,可能会导致从节点长时间收不到数据而触发超时;此时从节点会重连主节点,然后再次全量复制,再次超时,再次重连……形成恶性循环。
解决方案:redis单机数据量不要过大,同时适当增大repl-timeout值。
2)命令传播阶段
网络抖动导致个别PING命令丢失,造成的超时误判。
3)慢查询导致的阻塞
主节点或从节点执行一些慢查询(如key* 或 对大数据的hgetall等),导致服务器阻塞;阻塞期间无法响应复制连接中对方节点的请求,可能导致复制超时。
5、复制中断问题
复制中断有很多情况可以导致,主从节点超时是冲断的原因之一,最主要的原因是复制缓冲区溢出。
问题描述:
全量复制阶段,主节点会将执行的写命令放到复制缓冲区中,该缓冲区存放的数据包括以下几个时间段内主节点执行的写命令:
BGSAVE生成RDB文件 -> RDB文件由主节点发往从节点 -> 从节点清空老数据并载入RDB文件中的数据。
当主节点数据量较大,或者主动节点网络延迟较大时,可能导致该缓冲区的大小超过了限制,此时主节点会断开与从节点的连接,这种情况下可能会引起全量复制 -> 复制缓冲区溢出导致连接中断->重连->全量复制->复制缓冲区溢出导致连接中断…循环不断…
解决方法:
复制缓冲区的大小由client-output-buffer-limit slave {hard limit} {soft limit} {soft seconds}配置,默认值为:256MB 64MB 60
含义:如果buffer大于256MB,或者连续60s大于64MB,则主节点会断开与该从节点的连接。
参数可以通过config set命令动态配置(不重启redis也可以生效)。
需要注意的是,父子缓冲区是客户端输出缓冲区的一种,主节点会为每一个从节点分配复制缓冲区;而复制积压缓冲区则是一个主节点只有一个,无论它有多少个从节点。
6、主节点重启
主节点重启分两种情况:故障导致宕机、有计划的重启。
1)故障导致宕机
主节点宕机后,runid会发生变化,因此不能进行部分复制,只能进行全量复制。
在主节点宕机的情况下,应该进行故障转移处理,将其中的一个节点升级为主节点,其他从节点从新的主节点进行复制;同时故障转移应该自动化(哨兵模式)。
2)安全重启debug reload–有计划的重启
主节点内存碎片率过高,或者希望调整一些只能在启动时调整的参数,这时候就需要进行安全重启了。
如果使用普通的手段重启主节点,会使得runid发生变化,可能导致不必要的全量复制。
为了解决这个问题,Redis提供了debug reload的重启方式:重启后,主节点的runid和offset都不受影响,避免了全量复制。
同时需要注意的是,debug reload会清空当前内存中的数据,重新从RDB文件中加载,这过程会导致直接点的阻塞,因此需谨慎使用。
7、从节点重启
从节点宕机重启后,其保存的主节点的runid会丢失,因此即使再次执行slaveof,也无法进行部分复制。
8、网络中断
1)第一种情况
网络问题极为短暂,只造成了短暂的丢包,主从节点都没有判定超时(未触发repl-timeout);此时只需要通过REPLCONF ACK来补充丢失的数据即可。
2)第二种情况
网络问题时间很长,主从节点判断超时(触发了repl-timeout),且丢失的数据过多,超过了复制积压缓冲区所能存储的范围;此时主从节点无法进行部分复制,只能进行全量复制。
为了尽可能避免这种情况的发生,应该根据实际情况适当调整复制积压缓冲区的大小;此外及时发现并修复网络中断,也可以减少全量复制。
3)第三种情况
介于前述两种情况之间,主从节点判断超时,且丢失的数据仍然都在复制积压缓冲区中;此时主从节点可以进行部分复制。