config.py
"""
文件名: config.py
功能: 配置文件
"""
import os
# 指定数据集路径
dataset_path = './data'
# 结果保存路径
output_path = './output'
if not os.path.exists(output_path):
os.makedirs(output_path)
# 使用的特征列
feat_cols = ['battery_power', 'blue', 'clock_speed', 'dual_sim', 'fc', 'four_g', 'int_memory', 'm_dep',
'mobile_wt', 'n_cores', 'pc', 'px_height', 'px_width', 'ram', 'sc_h', 'sc_w', 'talk_time',
'three_g', 'touch_screen', 'wifi']
# print(len(feat_cols))
# 标签列
label_col = 'price_range'
=========================================================================
main.py
"""
文件名: main.py
功能: 主程序
案例:手机价格预测
任务:使用scikit-learn建立不同的机器学习模型进行手机价格等级预测
数据集来源: https://www.kaggle.com/vikramb/mobile-price-eda-prediction
"""
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
import seaborn as sns
import time
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
import config
# 解决matplotlib显示中文问题
# 仅适用于Mac
def get_chinese_font():
"""
获取系统中文字体
"""
return FontProperties(fname='/System/Library/Fonts/PingFang.ttc')
def inspect_dataset(train_data, test_data):
"""
查看数据集
"""
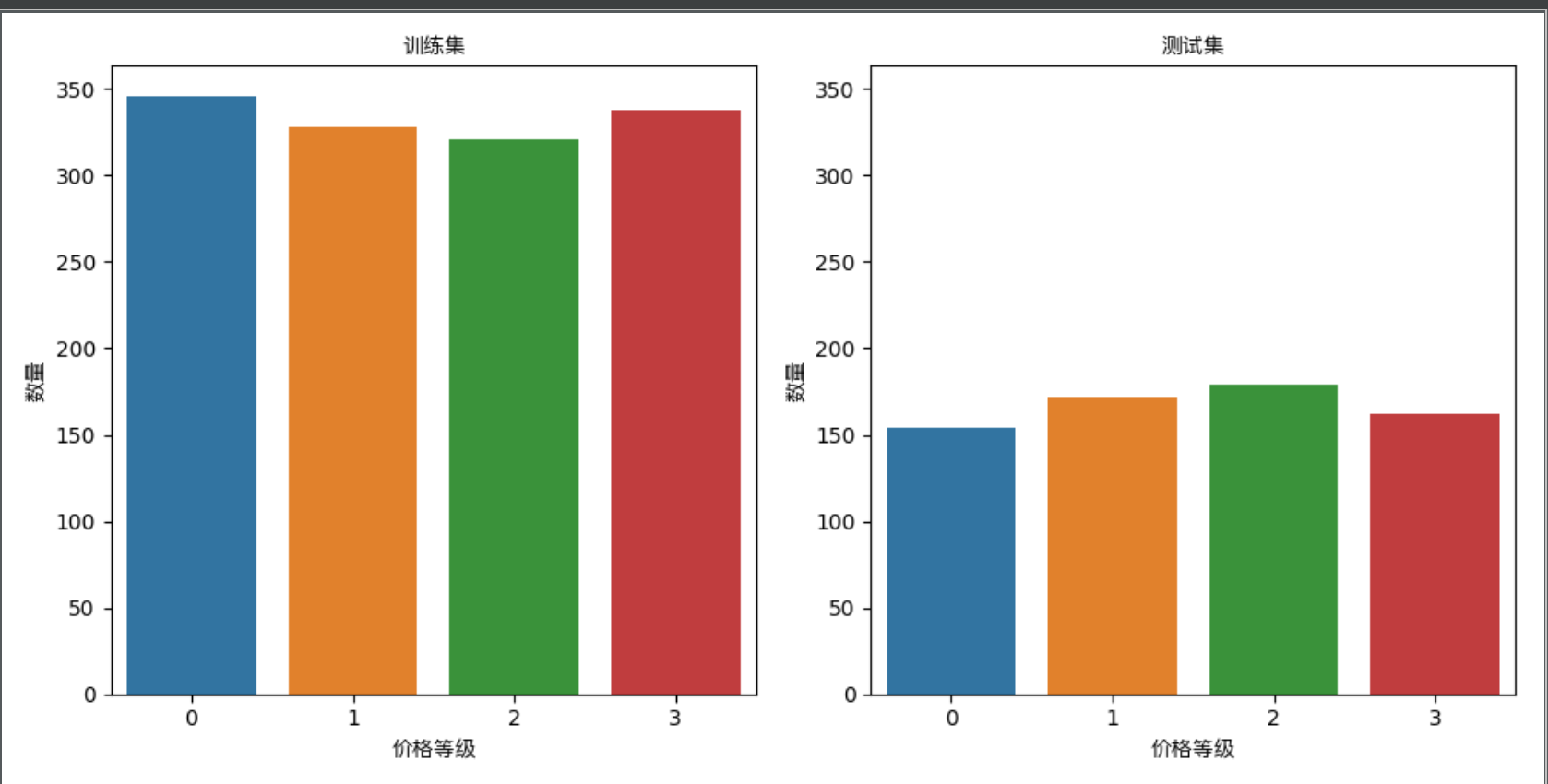
print('\n===================== 数据查看 =====================')
print('训练数据集有{}条记录'.format(len(train_data)))
print('测试数据集有{}条记录'.format(len(test_data)))
# 可视化各类别的数量统计图
plt.figure(figsize=(10, 5))
# 训练集
ax1=plt.subplot(1,2,1)
# 工作原理就是对输入的数据分类,条形图显示各个分类的数量
sns.countplot(x='price_range', data=train_data)
plt.title('训练集',fontproperties=get_chinese_font())
# plt.xticks(rotation='vertical')
plt.xlabel('价格等级',fontproperties=get_chinese_font())
plt.ylabel('数量',fontproperties=get_chinese_font())
#测试集
plt.subplot(1,2,2,sharey=ax1)
sns.countplot(x='price_range',data=test_data)
plt.title('测试集',fontproperties=get_chinese_font())
plt.xlabel('价格等级',fontproperties=get_chinese_font())
plt.ylabel('数量',fontproperties=get_chinese_font())
plt.tight_layout()
plt.savefig('./inspect_dataset.png')
plt.show()
def train_model(X_train,y_train,X_test,y_test,param_range, model_name='SVM'):
"""
model_name: 默认为svm
knn, kNN模型,对应参数为 n_neighbors
lr, 逻辑回归模型,对应参数为 C
svm, SVM模型,对应参数为 C
dt, 决策树模型,对应参数为 max_dpeth
根据给定的参数训练模型,并返回
1. 最优模型
2. 平均训练耗时
3. 准确率
"""
models = []
scores = []
durations = []
for param in param_range:
if model_name=='KNN':
print('训练KNN(k={})...'.format(param),end='')
model=KNeighborsClassifier(n_neighbors=param)
elif model_name=='LR':
print('训练Logistic Regression(C={})...'.format(param), end='')
model=LogisticRegression(C=param)
elif model_name=='SVM':
print('训练SVM(C={})...'.format(param), end='')
model=SVC(kernel='linear',C=param)
elif model_name=='DT':
print('训练决策树(max_depth={})...'.format(param), end='')
model=DecisionTreeClassifier(max_depth=param)
start=time.time()
# 训练模型
model.fit(X_train,y_train)
# 计时
end=time.time()
duration=end-start
print('耗时{:.4f}s'.format(duration), end=', ')
# 验证模型
score=model.score(X_test,y_test)
print('准确率:{:.3f}'.format(score))
models.append(model)
durations.append(duration)
scores.append(score)
mean_duration=np.mean(durations)
print('训练模型平均耗时{:.4f}s'.format(mean_duration))
print()
# 记录最优模型
best_idx=np.argmax(scores)
best_acc=scores[best_idx]
best_model=models[best_idx]
return best_model,best_acc,mean_duration
def main():
"""
主函数
"""
# 加载数据
all_data=pd.read_csv(os.path.join(config.dataset_path,'data.csv'))
train_data,test_data=train_test_split(all_data,test_size=1/3,random_state=10)
# 数据查看
inspect_dataset(train_data, test_data)
# 构建训练测试数据
# 特征处理
feat_names=config.feat_cols
X_train=train_data[feat_names].values#多维数组
print('共有{}维特征。'.format(X_train.shape[1]))
X_test=test_data[feat_names].values
# 标签处理
y_train=train_data[config.label_col].values
y_test=test_data[config.label_col].values
# 数据建模及验证
print('\n===================== 数据建模及验证 =====================')
model_name_param_dict={
'KNN':[5,10,15],
'LR':[0.01,1,100],
'SVM':[0.01,1,100],
'DT':[50,100,150]
}
# 比较结果的DataFrame
results_df=pd.DataFrame(columns=['Accuracy(%)','Time(s)'],index=list(model_name_param_dict.keys()))
results_df.index.name='Model'
for model_name,param_range in model_name_param_dict.items():
base_model, best_acc, mean_duration = train_model(X_train, y_train, X_test, y_test,
param_range, model_name)
results_df.loc[model_name, 'Accuracy(%)']=best_acc*100
results_df.loc[model_name, 'Time(s)']=mean_duration
results_df.to_csv(os.path.join(config.output_path,'model_coparison.csv'))
# 模型及结果比较
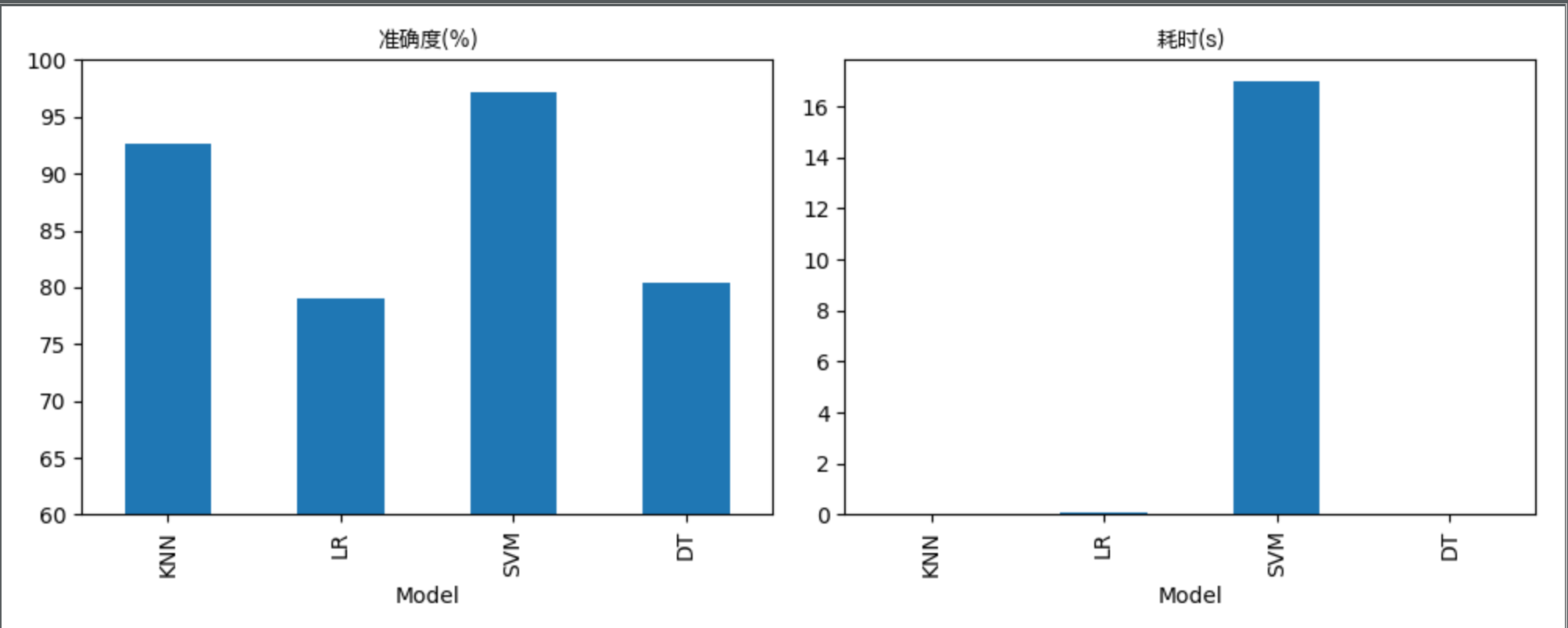
print('\n===================== 模型及结果比较 =====================')
plt.figure(figsize=(10,4))
ax1=plt.subplot(1,2,1)
# results_df.plot(y=['Accuracy (%)'],title='Accuracy(%)',kind='bar',ylim=[60,100],ax=ax1,legend=False)
results_df.plot(y=['Accuracy(%)'],kind='bar',ylim=[60,100],ax=ax1,legend=False)
plt.title('准确度(%)',fontproperties=get_chinese_font())
ax2=plt.subplot(1,2,2)
# results_df.plot(y=['Time (s)'],title='consum_time(s)',kind='bar',ax=ax2,legend=False)
results_df.plot(y=['Time(s)'],kind='bar',ax=ax2,legend=False)
plt.title('耗时(s)',fontproperties=get_chinese_font())
plt.tight_layout()
plt.savefig('./pred_results.png')
plt.show()
if __name__ == '__main__':
main()
=========================================================================/usr/local/bin/python3.6 /Users/apple/PycharmProjects/xxlec04_pro/main.py
===================== 数据查看 =====================
训练数据集有1333条记录
测试数据集有667条记录
共有20维特征。
===================== 数据建模及验证 =====================
训练KNN(k=5)...耗时0.0026s, 准确率:0.922
训练KNN(k=10)...耗时0.0009s, 准确率:0.910
训练KNN(k=15)...耗时0.0010s, 准确率:0.927
训练模型平均耗时0.0015s
训练Logistic Regression(C=0.01)...耗时0.0599s, 准确率:0.664
训练Logistic Regression(C=1)...耗时0.1010s, 准确率:0.735
训练Logistic Regression(C=100)...耗时0.1212s, 准确率:0.790
训练模型平均耗时0.0940s
训练SVM(C=0.01)...耗时0.3104s, 准确率:0.972
训练SVM(C=1)...耗时13.7091s, 准确率:0.966
训练SVM(C=100)...耗时36.8891s, 准确率:0.969
训练模型平均耗时16.9695s
训练决策树(max_depth=50)...耗时0.0122s, 准确率:0.798
训练决策树(max_depth=100)...耗时0.0077s, 准确率:0.796
训练决策树(max_depth=150)...耗时0.0076s, 准确率:0.804
训练模型平均耗时0.0092s
===================== 模型及结果比较 =====================
Process finished with exit code 0