深度神经网络可以按层被拆分为许多基本操作,而这些基本操作通过不同的组合方式也就构建多种多样的DNN。例如最常见的[INPUT - CONV - RELU - POOL - FC]组合。
简单记录一下卷积神经网络中的基本操作,为深度学习加速器设计做铺垫。
本文大量内容摘自两个学校的教程
http://cs231n.github.io/convolutional-networks/
http://www.rle.mit.edu/eems/wp-content/uploads/2017/06/Tutorial-on-DNN-1-of-9-Background-of-DNNs.pdf
0. feature map
参与计算的数据(feature map) 为三维结构,(W,H,C)分别标识width,height,channel维度尺寸,例如224*224*3的图片。
1.卷积Convolutional
平面内形象的卷积计算动图可以看https://github.com/vdumoulin/conv_arithmetic,实际计算中增加了channel维度,也需要加起来。
下图为一个input fmap和多个filter的计算示意图。因为channel维度要相加,input fmap和filter在C维度上相等,而输出fmap的C维度尺寸就是filter的个数。
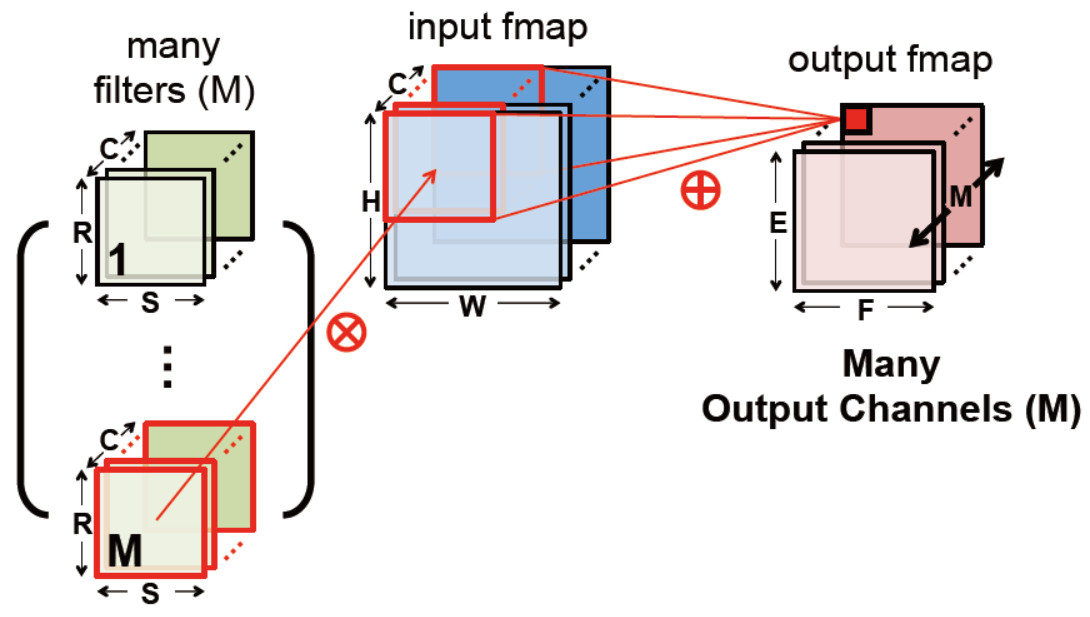
输入输出对应关系如下:
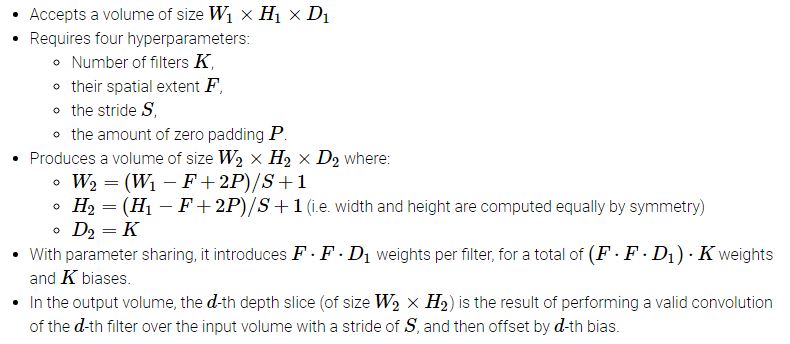

伪代码如下:
/* * img: (src_w,src_h,chi) * weights: cho * (ker_w, ker_h, chi) * output feature map: * dst_w = (src_w +2*pad - ker_w)/stride + 1 * dst_h = (src_h +2*pad - ker_h)/stride + 1 * dst_c = cho */ for(auto oc = 0; oc < cho; oc++){//cho kernels
dw = 0; for(auto iw = 0; iw+ker_w <= src_w; iw+= stride){
dh = 0; for(auto ih = 0; ih + ker_h <= src_h; ih += stride){
int tmp = 0;
for(auto wc = 0; wc < chi; wc++){
for(auto ww = 0; ww < ker_w; ww ++){
for(auto wh = 0; wh < ker_h; wh++){
tmp += img[wc][iw][ih] * weight[wc][ww][wh];
}
}
}
result[oc][dw][dh] = act(tmp + bias[oc]);
dh++;
}
dw++ } }
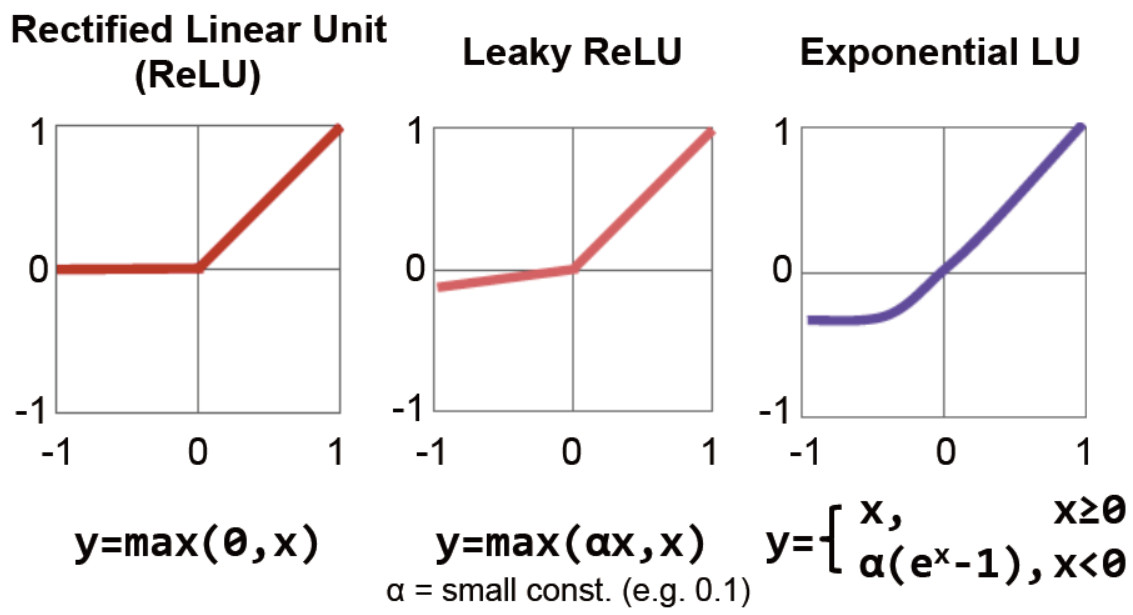
6层循环计算出的中间结果需要加上偏移量,经激活函数处理的到新的fmap数据。传统的激活函数有sigmoid和tanh。现在主流的都用运算量小,结果好的Relu系列
从卷积伪代码分析,一个卷积操作涉及的乘累加操作很多,单核单线程执行效率低下。而其中的6层循环,没个循环内部都有潜在的并行度值得去开发。
2.池化Pooling
也叫下采样(downsampling),典型的有max和average两种。卷积提取feature map的特征后,池化操作将特征区域内的代表数据保留,这样不仅抗噪声还能减少数据量。如下图:
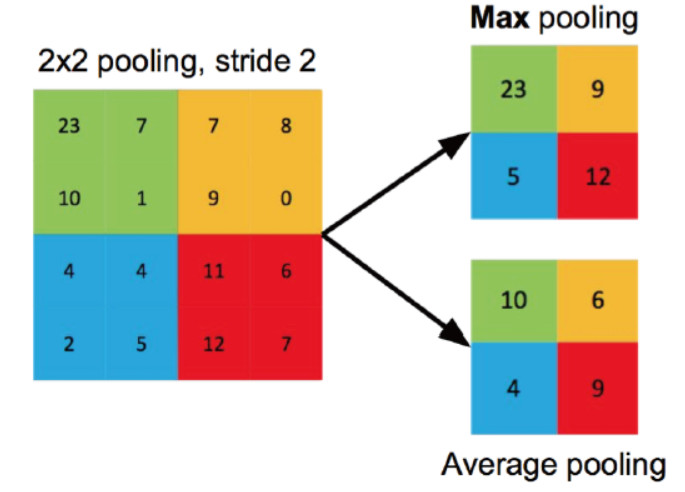
对应的输入输出关系

以下为max pool的伪代码
/* * img: (src_w,src_h,chi) * filter size: (ker_w,ker_h) * output feature map: * dst_w = (src_w - ker_w)/stride + 1 * dst_h = (src_h - ker_h)/stride + 1 * dst_c = chi */
for(auto oc = 0; oc < cho; oc++){//cho kernels
dw = 0;
for(auto iw = 0; iw+ker_w <= src_w; iw+= stride){
dh = 0;
for(auto ih = 0; ih + ker_h <= src_h; ih += stride){
for(auto wc = 0; wc < chi; wc++){
max = -Inf;
for(auto ww = 0; ww < ker_w; ww ++){
for(auto wh = 0; wh < ker_h; wh++){
if(img[wc][iw][ih] > max){
max = img[wc][iw][ih];
}
}
}
result[oc][dw][dh] = max;
}
dh++;
}
dw++;
}
}
3. 全连接fc
全连接没有conv的权值共享,每一个像素点都需要和输出神经元连接,消耗大量的权值存储。
全连接可以用卷积操作来分解。
例如input fmap为7*7*512,用4096个7*7*512的卷积核计算,stride=1,pad=0,结果是1*1*4096
如果还想缩减尺寸,用1000个1*1*4096的卷积核计算,stride=1,pad=0,结果是1*1*1000