【原文链接】http://chenqx.github.io/2014/11/09/Scrapy-Tutorial-for-BBSSpider/
Scrapy Tutorial
接下来以爬取饮水思源BBS数据为例来讲述爬取过程,详见 bbsdmoz代码。
本篇教程中将带您完成下列任务:
1. 创建一个Scrapy项目
2. 定义提取的Item
3. 编写爬取网站的 spider 并提取 Item
4. 编写 Item Pipeline 来存储提取到的Item(即数据)
Creating a project
在开始爬取之前,您必须创建一个新的Scrapy项目。进入您打算存储代码的目录中,运行下列命令:
scrapy startproject bbsdmoz该命令将会创建包含下列内容的 bbsDmoz 目录,这些文件分别是:
scrapy.cfg: 项目的配置文件bbsDmoz/: 该项目的python模块。之后您将在此加入代码。bbsDmoz/items.py: 项目中的item文件.bbsDmoz/pipelines.py: 项目中的pipelines文件.bbsDmoz/settings.py: 项目的设置文件.bbsDmoz/spiders/: 放置spider代码的目录.
Defining our Item
Item 是保存爬取到的数据的容器;其使用方法和python字典类似,并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
类似在ORM (Object Relational Mapping, 对象关系映射) 中做的一样,您可以通过创建一个 scrapy.Item 类,并且定义类型为 scrapy.Field 的类属性来定义一个Item。(如果不了解ORM,不用担心,您会发现这个步骤非常简单)
首先根据需要从bbs网站获取到的数据对item进行建模。 我们需要从中获取url,发帖板块,发帖人,以及帖子的内容。 对此,在item中定义相应的字段。编辑 bbsDmoz 目录中的 items.py 文件:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
from scrapy.item import Item, Field
class BbsItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = Field()
forum = Field()
poster = Field()
content = Field()一开始这看起来可能有点复杂,但是通过定义item, 您可以很方便的使用Scrapy的其他方法。而这些方法需要知道您的item的定义。
Our first Spider
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
创建一个Spider
Selectors选择器
我们使用XPath来从页面的HTML源码中选择需要提取的数据。这里给出XPath表达式的例子及对应的含义:
/html/head/title: 选择HTML文档中<head>标签内的<title>元素/html/head/title/text(): 选择上面提到的<title>元素的文字//td: 选择所有的<td>元素//div[@class="mine"]: 选择所有具有class="mine"属性的div元素
以饮水思源BBS一页面为例:https://bbs.sjtu.edu.cn/bbstcon?board=PhD&reid=1406973178&file=M.1406973178.A
观察HTML页面源码并创建我们需要的数据(种子名字,描述和大小)的XPath表达式。
通过观察,我们可以发现poster是包含在 pre/a 标签中的,这里是userid=jasperstream:
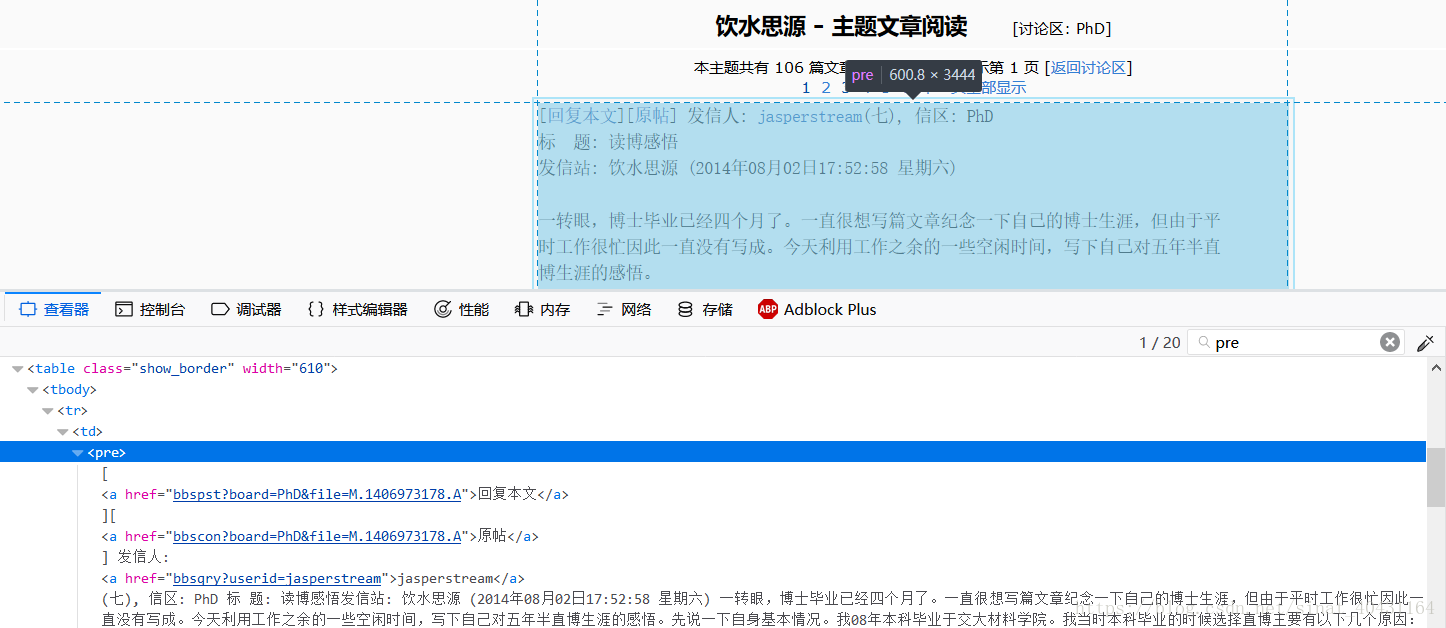
因此可以提取jasperstream的 XPath 表达式为:'//pre/a/text()'
为了配合XPath,Scrapy除了提供了 Selector 之外,还提供了方法来避免每次从response中提取数据时生成selector的麻烦。Selector有四个基本的方法:
xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表 。css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表.extract(): 序列化该节点为unicode字符串并返回list。re(): 根据传入的正则表达式对数据进行提取,返回unicode字符串list列表。
如提取上述的poster的数据:
sel.xpath('//pre/a/text()').extract()使用Item
Item 对象是自定义的python字典。您可以使用标准的字典语法来获取到其每个字段的值(字段即是我们之前用Field赋值的属性)。一般来说,Spider将会将爬取到的数据以 Item 对象返回。
Spider代码
以下为我们的第一个Spider代码,保存在 bbsDmoz/spiders 目录下的 forumSpider.py 文件中:
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 20 13:18:58 2018
@author: Administrator
"""
from scrapy.selector import Selector
from scrapy.http import Request
from scrapy.contrib.spiders import CrawlSpider
from scrapy.contrib.loader import ItemLoader
#SGMLParser based link extractors are unmantained and its usage is discouraged. It is recommended to migrate to LxmlLinkExtractor
#from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.contrib.linkextractors.lxmlhtml import LxmlLinkExtractor
from bbsdmoz.items import BbsItem
class forumSpider(CrawlSpider):
# name of spiders
name = 'bbsSpider'
allow_domain = ['bbs.sjtu.edu.cn']
start_urls = [ 'https://bbs.sjtu.edu.cn/bbsall' ]
link_extractor = {
'page': LxmlLinkExtractor(allow = '/bbsdoc,board,\w+\.html$'),
'page_down': LxmlLinkExtractor(allow = '/bbsdoc,board,\w+,page,\d+\.html$'),
'content': LxmlLinkExtractor(allow = '/bbscon,board,\w+,file,M\.\d+\.A\.html$'),
}
_x_query = {
'page_content': '//pre/text()[2]',
'poster' : '//pre/a/text()',
'forum' : '//center/text()[2]',
}
def parse(self, response):
for link in self.link_extractor['page'].extract_links(response):
yield Request(url = link.url, callback=self.parse_page)
def parse_page(self, response):
for link in self.link_extractor['page_down'].extract_links(response):
yield Request(url = link.url, callback=self.parse_page)
for link in self.link_extractor['content'].extract_links(response):
yield Request(url = link.url, callback=self.parse_content)
def parse_content(self, response):
bbsItem_loader = ItemLoader(item=BbsItem(), response = response)
url = str(response.url)
bbsItem_loader.add_value('url', url)
bbsItem_loader.add_xpath('forum', self._x_query['forum'])
bbsItem_loader.add_xpath('poster', self._x_query['poster'])
bbsItem_loader.add_xpath('content', self._x_query['page_content'])
return bbsItem_loader.load_item()Define Item Pipeline
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
以下是item pipeline的一些典型应用:
- 清理HTML数据
- 验证爬取的数据(检查item包含某些字段)
- 查重(并丢弃)
- 将爬取结果保存,如保存到数据库、XML、JSON等文件中
编写 Item Pipeline
编写你自己的item pipeline很简单,每个item pipeline组件是一个独立的Python类,同时必须实现以下方法:
process_item(item, spider)
每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象,或是抛出 DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。
参数:item (Item object) – 由 parse 方法返回的 Item 对象
spider (Spider object) – 抓取到这个 Item 对象对应的爬虫对象此外,他们也可以实现以下方法:
open_spider(spider)
当spider被开启时,这个方法被调用。
参数: spider (Spider object) – 被开启的spider
close_spider(spider)
当spider被关闭时,这个方法被调用,可以再爬虫关闭后进行相应的数据处理。
参数: spider (Spider object) – 被关闭的spider 本文爬虫的item pipeline如下,保存为XML文件:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy import signals
from scrapy import log
from bbsdmoz.items import BbsItem
from twisted.enterprise import adbapi
from scrapy.contrib.exporter import XmlItemExporter
from dataProcess import dataProcess
class BbsdmozPipeline(object):
def __init__(self):
pass
@classmethod
def from_crawler(cls, crawler):
pipeline = cls()
crawler.signals.connect(pipeline.spider_opened, signals.spider_opened)
crawler.signals.connect(pipeline.spider_closed, signals.spider_closed)
return pipeline
def spider_opened(self, spider):
self.file = open('bbsData.xml', 'wb')
self.expoter = XmlItemExporter(self.file)
self.expoter.start_exporting()
def spider_closed(self, spider):
self.expoter.finish_exporting()
self.file.close()
# process the crawled data, define and call dataProcess function
# dataProcess('bbsData.xml', 'text.txt')
def process_item(self, item, spider):
self.expoter.export_item(item)
return item编写dataProcess.py小工具:
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 20 14:45:01 2018
@author: Administrator
"""
from lxml import etree
# In Python 3, ConfigParser has been renamed to configparser
from configparser import ConfigParser
class dataProcess:
def __init__(self, source_filename, target_filename):
# load stop words into the memory.
fin = open(source_filename, 'r')
read = fin.read()
output = open(target_filename, 'w')
output.write(read)
fin.close()
output.close()Settings (settings.py)
Scrapy设定(settings)提供了定制Scrapy组件的方法。您可以控制包括核心(core),插件(extension),pipeline及spider组件。
设定为代码提供了提取以key-value映射的配置值的的全局命名空间(namespace)。 设定可以通过下面介绍的多种机制进行设置。
设定(settings)同时也是选择当前激活的Scrapy项目的方法(如果您有多个的话)。
在setting配置文件中,你可一定以抓取的速率、是否在桌面显示抓取过程信息等。详细请参考内置设定列表请参考 。
为了启用一个Item Pipeline组件,你必须将它的类添加到 ITEM_PIPELINES. 分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。
# -*- coding: utf-8 -*-
# Scrapy settings for bbsdmoz project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'bbsdmoz'
SPIDER_MODULES = ['bbsdmoz.spiders']
NEWSPIDER_MODULE = 'bbsdmoz.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'bbsdmoz (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'bbsdmoz.middlewares.BbsdmozSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'bbsdmoz.middlewares.BbsdmozDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'bbsdmoz.pipelines.BbsdmozPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'Crawling
写好爬虫程序后,我们就可以运行程序抓取数据。进入项目的根目录bbsDomz/下,执行下列命令启动spider (会爬很久):
scrapy crawl bbsSpider【完整代码】
- dataProcess.py
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 20 14:45:01 2018
@author: Administrator
"""
from lxml import etree
# In Python 3, ConfigParser has been renamed to configparser
from configparser import ConfigParser
class dataProcess:
def __init__(self, source_filename, target_filename):
# load stop words into the memory.
fin = open(source_filename, 'r')
read = fin.read()
output = open(target_filename, 'w')
output.write(read)
fin.close()
output.close()- settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for bbsdmoz project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'bbsdmoz'
SPIDER_MODULES = ['bbsdmoz.spiders']
NEWSPIDER_MODULE = 'bbsdmoz.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'bbsdmoz (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'bbsdmoz.middlewares.BbsdmozSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'bbsdmoz.middlewares.BbsdmozDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'bbsdmoz.pipelines.BbsdmozPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'- pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy import signals
from scrapy import log
from bbsdmoz.items import BbsItem
from twisted.enterprise import adbapi
from scrapy.contrib.exporter import XmlItemExporter
from dataProcess import dataProcess
class BbsdmozPipeline(object):
def __init__(self):
pass
@classmethod
def from_crawler(cls, crawler):
pipeline = cls()
crawler.signals.connect(pipeline.spider_opened, signals.spider_opened)
crawler.signals.connect(pipeline.spider_closed, signals.spider_closed)
return pipeline
def spider_opened(self, spider):
self.file = open('bbsData.xml', 'wb')
self.expoter = XmlItemExporter(self.file)
self.expoter.start_exporting()
def spider_closed(self, spider):
self.expoter.finish_exporting()
self.file.close()
# process the crawled data, define and call dataProcess function
# dataProcess('bbsData.xml', 'text.txt')
def process_item(self, item, spider):
self.expoter.export_item(item)
return item- items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
from scrapy.item import Item, Field
class BbsItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = Field()
forum = Field()
poster = Field()
content = Field()- forumSpider.py
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 20 13:18:58 2018
@author: Administrator
"""
from scrapy.selector import Selector
from scrapy.http import Request
from scrapy.contrib.spiders import CrawlSpider
from scrapy.contrib.loader import ItemLoader
#SGMLParser based link extractors are unmantained and its usage is discouraged. It is recommended to migrate to LxmlLinkExtractor
#from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from scrapy.contrib.linkextractors.lxmlhtml import LxmlLinkExtractor
from bbsdmoz.items import BbsItem
class forumSpider(CrawlSpider):
# name of spiders
name = 'bbsSpider'
allow_domain = ['bbs.sjtu.edu.cn']
start_urls = [ 'https://bbs.sjtu.edu.cn/bbsall' ]
link_extractor = {
'page': LxmlLinkExtractor(allow = '/bbsdoc,board,\w+\.html$'),
'page_down': LxmlLinkExtractor(allow = '/bbsdoc,board,\w+,page,\d+\.html$'),
'content': LxmlLinkExtractor(allow = '/bbscon,board,\w+,file,M\.\d+\.A\.html$'),
}
_x_query = {
'page_content': '//pre/text()[2]',
'poster' : '//pre/a/text()',
'forum' : '//center/text()[2]',
}
def parse(self, response):
for link in self.link_extractor['page'].extract_links(response):
yield Request(url = link.url, callback=self.parse_page)
def parse_page(self, response):
for link in self.link_extractor['page_down'].extract_links(response):
yield Request(url = link.url, callback=self.parse_page)
for link in self.link_extractor['content'].extract_links(response):
yield Request(url = link.url, callback=self.parse_content)
def parse_content(self, response):
bbsItem_loader = ItemLoader(item=BbsItem(), response = response)
url = str(response.url)
bbsItem_loader.add_value('url', url)
bbsItem_loader.add_xpath('forum', self._x_query['forum'])
bbsItem_loader.add_xpath('poster', self._x_query['poster'])
bbsItem_loader.add_xpath('content', self._x_query['page_content'])
return bbsItem_loader.load_item()The end.