0 数据容错机制: 1)数据检查点 2)记录数据更新, RDD使用的lineage是记录数据更新

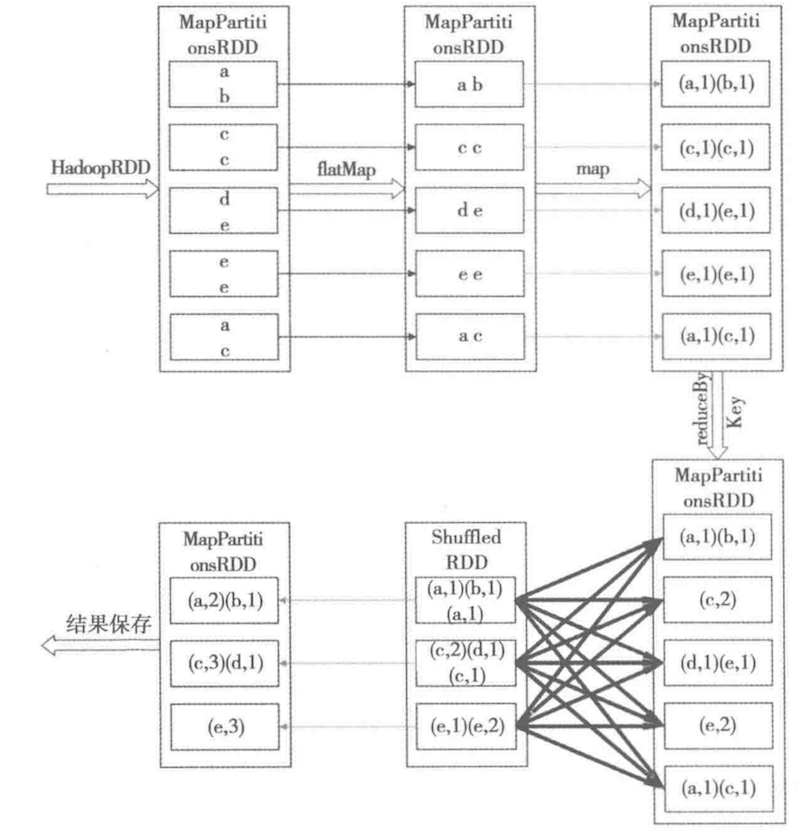
1 rdd是什么:
1.1 rdd的构成:rdd是只读的分布式的存储在worker上的数据集合, 比如 JavaRDD<String> record; 是从hdfs上创建出来的用户行为信息,一个条记录是一个String,比如用户数量是10M,理论上record.count()就是 10M.一个RDD会被划分为若干个分片,比如均匀划分为10个分片,那么一个分片包含的数据就是1M条String,默认的分片数量是worker集群中core的数量,例如我们有250台worker, 每个worker都是4 core, 那么就是1000个分片, 一个分片包含1W条记录。分片是一个逻辑概念partition, 物理上会被映射为一个block,一个block会被视作一个task。分片的划分有两种,一种是HashPartitioner 一种是RangePartitioner, spark2.0后默认就是rangePartiotioner。rdd之间存在依赖关系,如上图所示就是wordcount的rdd依赖流水线, HadoopRDD->MapPartitionRDD->ShuffledRDD-> MapPartitionRDD, 从上图可以看到在shuffle之前,每个分片之间是一一对应的,比如<c,c>-><(c,1),(c,1)>-><(c,2)>, 如果一个分片丢失了,并不需要重新计算所有的rdd,而是可以只计算失效的partition。但是在有shuffle的步骤,一个分片可能依赖多个来自上一个rdd的分片,做一次缓存对于提升性能有很大的帮助。
1.2 转换与动作:
1) 转换:map,filter, flatMap, mapPartition, sample,union, distinct, groupByKey, reduceByKey, sortByKey, join, cogroup,cartesian
2)动作:reduce, collect, count,first, take,save
3)RDD 转换之后依然是RDD,也就是依然分布式的存储在worker上,但是经过动作之后数据将返回到master上,master的内存是有限的,如果worker内存不足可以通过增加机器完成。转换是懒惰的 这是函数编程的三个主要特性之一, 这样有助与提升性能,当分析出运行图之后,根据action所需要的数据进行前面的数据转换操作。
4)缓存:spark速度快的一个主要原因就是有缓存,一个已经计算出来的rdd并不需要重新计算,rdd1=rdd0.map, rdd2=rdd1.mapPair, rdd3=rdd1.filter, 当执行某个action进行倒推的时候,rdd1会被缓存下来,因为rdd1会被后续的rdd使用两次
2 rdd => DAG:窄依赖和宽依赖,如果一个rdd中的分片对上一个rdd中分片的依赖只是一个分片,那么就是窄依赖,否则为宽依赖,注意分片要在同一个rdd中

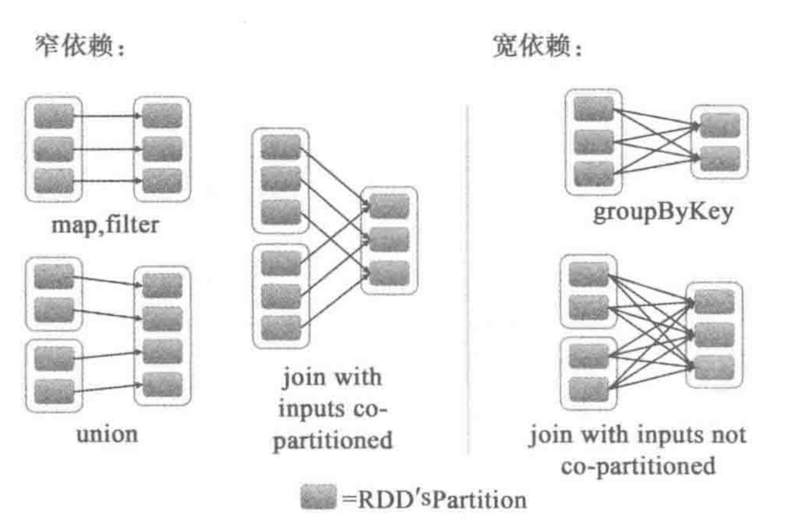
3 rdd的计算过程:
4 rdd的容错机制: