1.变成范式:数据流图
声明式编程和命令式编程是两种常见的变成范式。其中,声明式编程擅长基于数理逻辑的应用领域,比如:深度学习,人工智能,符号计算系统等;命令式编程擅长复杂业务逻辑领域,比如交互式UI程序等。Tensorflow采用声明式编程的编程方式,具有代码可读性强,支持引用透明(Tensorflow有很多内置函数,可以直接用于计算,用户不必从头开始编程),提供预编译优化的能力的特点。
Tensorflow将数据流图定义为:用节点和有向边描述数学运算的有向无环图。基于梯度下降的深度学习问题通常可以分为前向图求值与后向图求梯度两个计算阶段。其中前向图由用户自己编写代码完成;后向图由Tensorflow优化器自动生成。主要功能是使用梯度更新对应的模型参数。
数据流图中的主要概念:
1.节点 :前向图的节点有:数学函数或表达式(add,matmul)、存储类型参数变量(Variable)、占位符(placeholder);后向图节点有:梯度值、曾新参数模型的操作、更新后的模型参数。
2.有向边 :用来定义操作之间的关系,按照作用分为两类,一类用来传输数据,一类用来定义控制依赖。
3.执行原理
2.数据载体:张量
Tensorflow提供Tensor和SparseTensor两种张量抽象,分别表示稠密数据和稀疏数据。Tensorflow内部通过引用计数的方式判断是否应该释放张量数据的内存缓冲区。
2.1张量 Tensor
1.创建
Tensor类的构造方法的参数如下所示:dtype(张量传输数据的类型),name(张量在数据流中的名称),graph(张量所属的数据流图),op(生成该张量的前置操作),shape(张量传输数据形状),value_index(张量在该前置操作所有输出值中的索引)。
import tensorflow as tf a=tf.constant(1.0) b=tf.constant(2.0) c=tf.add(a,b)
2.求解
求解需要创建会话,以下是创建会话的两种方式:
with tf.Session() as sess:
print(c.eval())
print(sess.run([a,b,c])
#或者
sess=tf.InterativeSession()
print(c.eval())
print(sess.run([a,b,c])
3.成员方法
eval()#取出张量值 get_shape()#获取张量形状 set_shape()#修改张量形状 consumers()#获取张量的后置操作
2.2稀疏张量 SparseTensor
SparseTensor以键值对的形式表示高维稀疏矩阵。稀疏矩阵也有对应的一系列操作。
#本例表示的矩阵是[[0,0,1,0],[0,0,0,2],[0,0,0,0]] import tensorflow as tf sp=tf.SparseTensor(indices=[[0,2],[1,3]],values=[1,2],dense_shape=[3,4]) #indices表示非零元素的位置;values表示非零元素的值;dense_shape表示矩阵的真实大小。
3. 模型载体:操作
Tensorflow的算法模型由数据流图表示。数据流图由节点和有向边组成。节点分为以下三类:计算节点,存储节点和数据节点。
3.1计算节点Operation
计算节点对应的计算操作抽象是Operation类。计算节点的属性如下:
name #操作数据流的名字 type #操作的类型名称 inputs #操作的输入 control_inputs #输入控制依赖列表 outputs #输出张量列表 device #操作执行的使用设备(cpu或者gpu) graph #操作所属的数据流 traceback #操作实例化调用的栈
下面以add操作为例,说明变量内部的子节点是如何进行运作的。
c=tf.add(a,b,name='add')
变量a 内部由(a),Assign,read和initial_value四个子节点组成。当执行c=tf.add(a,b,name='add')的时候,add调用a子图内部的read子节点,将a转换为标量(0阶的张量)传输给add操作。在数据流计算开始之前,用户通常要执行tf.global_variables_initializer函数进行全局初始化。其本质是将intial_value传入Assign子节点,对变量实现初次赋值。
3.2存储节点Variable
1.变量
Tensorflow数据流图上的存储节点抽象是Variable类。通常称为变量。Variable类的构造函数提供的属性如下所示:
name #变量在数据流中的名称 dtype #变量的数据类型 shape #变量的形状 initial_value #变量的初始值 initializer #计算前为变量赋值的初始化操作 device #变量的存储设备 graph #变量所属的数据流图 op #变量操作
构造变量的时候需要指明shape和dtype。Variable的两种构造方法分别是:使用初始值构造,和使用Protocol Buffers定义的变量构造。两种初始化方法分别实现于Variable类的私有成员方法_init_from_args和_init_from_proto。
3.3 数据节点:Placeholder
在用户向Tensorflow的数据流图填充数据之前,图中并没有执行任何操作。Tensorflow的数据节点由占位操作符实现,它对应的操作函数是tf.placeholder。对稀疏数据,Tensorflow也提供了稀疏占位操作符,对应的函数是tf.sparse_placeholder。这两个函数的构造函数参数如下所示:
name #占位操作符在数据流图中的名称 dtype #填充数据的类型 shape #填充数据的形状
以下使用tensor和sparsetensor说明如何对占位符进行填充。
import tensorflow as tf
import numpy as np
with tf.name_scope("PlaceholderExample"):
x=tf.placeholder(tf.float32,shape=(2,2),name='x')#声明一个占位符
y=tf.matmul(x,x,name='matmul')
with tf.Session() as sess:
rand_array=np.random.rand(2,2)
#使用feed_dict(填充字典)参数,调用numpy库生成随机数的方法np.rand.rand_array对x进行填充
print(sess.run(y,feed_dict={x:rand_array}))
import tensorflow as tf
import numpy as np
x=tf.sparse_placeholder(tf.float32)
y=tf.sparse_reduce_sum(x)
with tf.Session() as sess:
indices=np.array([[3,2,1],[4,5,0]],dtype=np.int64)
values=np.array([1.0,2.0],dtype=np.float32)
shape=np.array([7,9,2],dtype=np.int64)
#第一种方式
tmp=sess.run(y,feed_dict={x:(indices,values,shape)})
print(tmp)
#第二种方式
print(sess.run(y,feed_dict={x:tf.SparseTensorValue(indices,values,shape)}))
#第三种方式
sp=tf.SparseTensor(indices=indices,values=values,dense_shape=shape)
sp_value=sp.eval()
print(sess.run(y,feed_dict={x:sp_value}))
4 运行环境:会话
会话的三个步骤:创建会话,运行会话,关闭会话。Session构造方法的参数如下所示:
target #会话连接的执行引擎 graph #会话加载的数据流图,当用户在代码中定义了多幅数据流图的时候需要graph显式指定 config #会话启动的配置
Session类用于运行会话的方法是run。该方法的参数表如下所示:
fetches #带求解的张量或者操作 feed_dict #数据填充字典 options #RunOptions对象,用来设置会话运行时的可选特性开关 run_metadata #RunMetadata对象,用于手机会话运行时张量元信息输出
除了用Session.run求解,还可以用Tensor的eval方法。
关闭会话使用sess.close()
交互式对话:sess=tf.InteractiveSession()
5. 训练工具:优化器
机器学习大致分为三类,分别是监督学习,无监督学习和半监督学习。典型的监督学习由三部分组成,分别是模型,损失函数和优化方法。主流的监督学习模型主要采用基于梯度下降的优化算法进行魔性训练。
5.1损失函数
常见的损失函数有 平方损失函数,交叉熵损失函数和知识损失函数。损失函数非负,损失函数越小说明拟合越好。但如果过分追求损失函数的最小值将可能导致过拟合的问题。因此需要引入正则化项或者惩罚项。此时最优化目标为
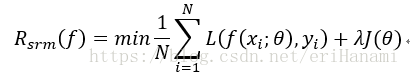
5.2 优化器概述
//其实没有很懂这里的反向传播算法。