除了之前介绍的多表查询,单表查询之外,还可以使用union/union all集合操作符将多个多个select的执行结果进行合并然后进行查询。
同样,本次的测试用数据库还是为scott数据库,大家可以在我的GitHub进行scott数据库创建脚本的下载。
1. 合并查询
1.1 union
union用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
- 例1:将工资大于25000和职位是MANAGER的人找出来。
mysql> select ename, sal, job from emp where sal>2500 union select ename, sal, job from emp where job='MANAGER';
+-------+---------+-----------+
| ename | sal | job |
+-------+---------+-----------+
| JONES | 2975.00 | MANAGER |
| BLAKE | 2850.00 | MANAGER |
| SCOTT | 3000.00 | ANALYST |
| KING | 5000.00 | PRESIDENT |
| FORD | 3000.00 | ANALYST |
| CLARK | 2450.00 | MANAGER |
+-------+---------+-----------+
6 rows in set (0.00 sec)1.2 union all
顾名思义,union all用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
我们继续使用例1的查询场景。
mysql> select ename, sal, job from emp where sal>2500 union all select ename, sal, job from emp where job='MANAGER';
+-------+---------+-----------+
| ename | sal | job |
+-------+---------+-----------+
| JONES | 2975.00 | MANAGER |
| BLAKE | 2850.00 | MANAGER |
| SCOTT | 3000.00 | ANALYST |
| KING | 5000.00 | PRESIDENT |
| FORD | 3000.00 | ANALYST |
| JONES | 2975.00 | MANAGER |
| BLAKE | 2850.00 | MANAGER |
| CLARK | 2450.00 | MANAGER |
+-------+---------+-----------+
8 rows in set (0.00 sec)我们可以看到,union all查询出来的结果要比union查询出来的结果多两行。
2. 自我复制
自我复制又叫蠕虫复制,是一种很有用的技巧,我们可以使用它进行大量测试数据的创建,复制表以及删除表中重复记录等场景下的应用。
2.1 大量测试数据的创建
我们以scott数据库的emp表为样板。
mysql> select * from emp;
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007654 | MARTIN | SALESMAN | 7698 | 1981-09-28 00:00:00 | 1250.00 | 1400.00 | 30 |
| 007698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 007782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 007844 | TURNER | SALESMAN | 7698 | 1981-09-08 00:00:00 | 1500.00 | 0.00 | 30 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007900 | JAMES | CLERK | 7698 | 1981-12-03 00:00:00 | 950.00 | NULL | 30 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
| 007934 | MILLER | CLERK | 7782 | 1982-01-23 00:00:00 | 1300.00 | NULL | 10 |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
14 rows in set (0.00 sec)我们可以看到,emp中有14条记录,现在我们要让它迅速扩充到100w以上的数据。
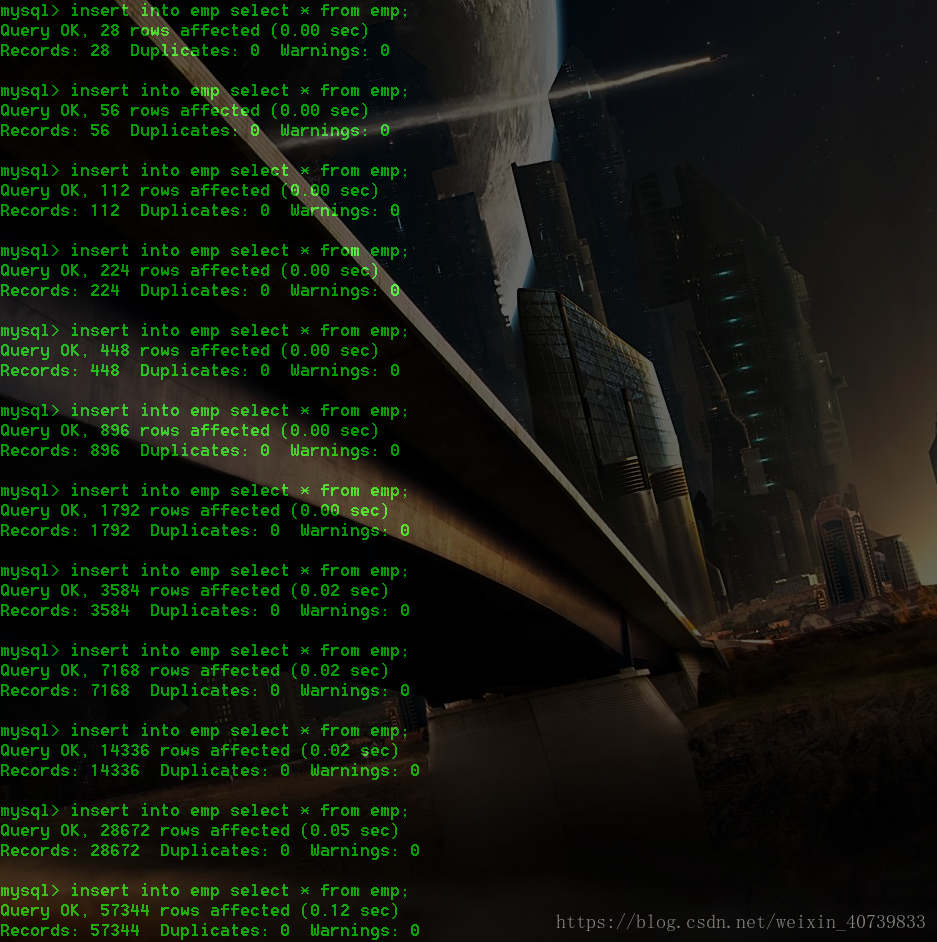
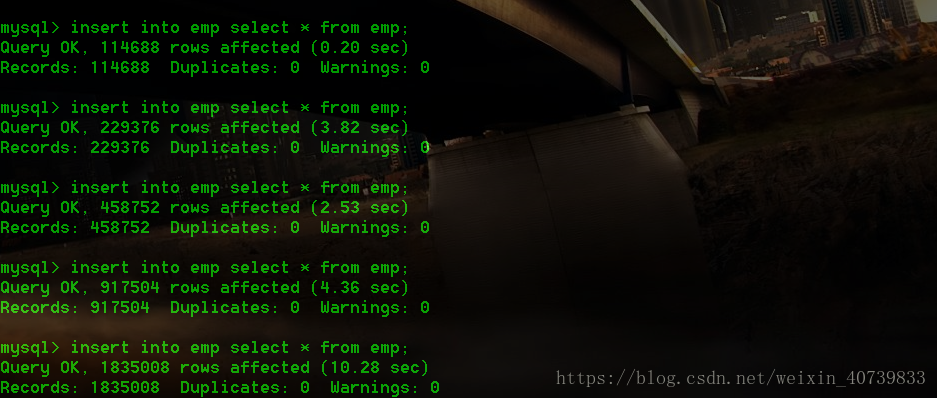
我们可以看到,在不到1分钟的时间里,我们就进行了100w以上条数据的插入,这也是数据库的魅力之一。
2.2 复制表
MySQL中没有提供复制操作,所以我们可以使用自我复制,进行表的复制。
- 例1:将scott数据库dept表进行复制,复制之后的表叫做copy_emp,实例如下:
mysql> create table copy_dept like dept;
Query OK, 0 rows affected (0.23 sec)
mysql> insert into copy_dept select * from dept;
Query OK, 4 rows affected (0.11 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> select * from copy_dept;
+--------+------------+----------+
| deptno | dname | loc |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------+------------+----------+
4 rows in set (0.00 sec)2.3 删除表中重复记录
删除表中重复记录也是实际场景之一,我们可以通过distinct配合select进行该操作。
- 例2:将上例中自我复制过的emp表中重复数据进行删除。
-- 第一步:创建一个与原表表结构相同的空表,使用like关键字
mysql> create table temp like emp;
Query OK, 0 rows affected (0.06 sec)
-- 第二步:使用distinct将重复元素过滤之后插入空表中
mysql> insert into temp select distinct * from emp;
Query OK, 14 rows affected (6.37 sec)
Records: 14 Duplicates: 0 Warnings: 0
-- 第三步:删除原表
mysql> drop table emp;
Query OK, 0 rows affected (0.01 sec)
-- 第四步:将新建的表表名改为原表表名(狸猫换太子)
mysql> alter table temp rename emp;
Query OK, 0 rows affected (0.03 sec)
mysql> select * from emp;
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007654 | MARTIN | SALESMAN | 7698 | 1981-09-28 00:00:00 | 1250.00 | 1400.00 | 30 |
| 007698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 007782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 007844 | TURNER | SALESMAN | 7698 | 1981-09-08 00:00:00 | 1500.00 | 0.00 | 30 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007900 | JAMES | CLERK | 7698 | 1981-12-03 00:00:00 | 950.00 | NULL | 30 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
| 007934 | MILLER | CLERK | 7782 | 1982-01-23 00:00:00 | 1300.00 | NULL | 10 |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
14 rows in set (0.01 sec)细心的同学们可以发现,100w条数据的数据库删除只花费了0.01秒,这是除了数据库之外任何工具都不可能实现的,这也印证了数据库是大量数据操作的必备之选。当然,由于我们在emp表中存在了大量的数据,所以在第二步使用distinct查找数据时花费了大量的时间,但这没关系,在之后的章节中,这个问题会被解决。