一、基本查询语句
select语句基本格式:
SELECT
{*|<字段列表>}
[
FROM <表1>,<表2>...
[WHERE <表达式>
[GROUP BY <group by definition>]
[HAVING <expression> [{<operator>< expression >}...]]
[ORDER BY <order by definition >]
[LIMIT [offset,] <row count>]
]
SELECT [字段1,字段2,…,字段n]
FROM [表或视图];
二、单表查询
1、查询所有字段
- 使用“*”通配符查询所有字段:select * from 表名;
- 在select语句中指定所有字段:select 字段1,字段2,...,字段n from 表
2、查询指定字段
- 查询单个字段:select 列名 from 表名;
- 查询多个字段:select 字段名1,字段名2,字段名3,...字段名n, from 表名。
3、查询指定记录
- 语法:select 字段名1,字段名2,...,字段名n from 表名 where 查询条件;
where条件判断符 操作符 说明 = 相等 <>,!= 不相等 < 小于 <= 小于或等于 > 大于 >= 大于或等于 between a and b 位于两值之间(大于等于小于等于b)
4、带IN关键字的查询
- 语法:select 字段1,字段2,...,字段n from 表名 where 字段名 in(值1,值2,...,值n);
5、带between and 的范围查询
- 语法:select 字段1,字段2,...,字段n from 表名 where 字段名 between 值1 and 值2;
6、带like的字符匹配查询
- 使用通配符“%”匹配任意长度的字符串,包括0字符;
- 使用通配符“_”一次只能匹配任意一个字符
7、查询空值
- 查询空值,语法:select 字段1,字段2,...,字段3 from 表名 where 字段名 is null;
- 查询非空值,语法:select 字段1,字段2,...,字段3 from 表名 where 字段名 is not null;
8、带and的多条件查询语句
- 语法:select 字段1,字段2,...,字段3 from 表名 where 条件表达式1 and 条件表达式2;
9、带OR的多条件查询(and和or可以同时使用,and优先级更高)
- 语法:select 字段1,字段2,...,字段3 from 表名 where 条件表达式1 or 条件表达式2;
10、查询结果不重复
- 语法:select distinct 字段名 from 表名;
11、对查询结果排序
- 单列排序:select 字段1,字段2,...,字段3 from 表名 order by 列名;
- 多列排序:select 字段1,字段2,...,字段3 from 表名 order by 列名1,列名2;(先按列名1排序,再按列名2排序);
- 指定排序方向:select 字段1,字段2,...,字段3 from 表名 order by 列名 desc;(默认是asc升序,降序是desc);
12、分组查询
- 创建分组,例:select 字段名1,count(*) form 表名 group by 字段名1;
- 使用group_concat()将每个分组中各个字段值显示出来:select 字段1,group_concat(字段2) form 表名 group by 字段1;
- 使用having过滤分组:select 字段1,group_concat(字段2) form 表名 group by 字段1 having 条件表达式;
- 在group by 字句中使用 with rollup增加一条记录为记录的总和:select 字段1,count(*) form 表名 group by 字段1 with rollup;
- 多字段分组:select * from 表名 group by 字段1,字段2;(先按字段1分组,然后在第一个字段值相同的记录中,再根据第二个字段分组,以此类推);
- group by和order by可以同时使用,order by在group by的后面使用。使用with rollup时不能同时使用oeder by。
13、使用limit限制查询结果数量
- select * from 表名 limit [位置偏移量],行数
三、使用聚合函数查询
1、COUNT()函数
- COUNT(*) 计算表中总的行数,不管某一列有数值或者是空值。
- COUNT(字段名) 计算指定列下总的行数,计算时将忽略空值的行。比如总数据有5行,字段1有值的只有3行,那就返回3。
2、SUM()函数
- SUM()函数返回指定列值的总和。查询语句后面可以加 WHERE 条件语句,用来查询指定条件指定列的值的总和。
- SUM()还可以和 group by 一起使用,计算每个分组的总和。
3、AVG()函数
- AVG()函数获取指定列数据的平均值。
- AVG()可以和group by 一起使用,获取每个分组的平均值。
4、MAX()函数
- MAX()函数返回指定列中的最大值。
- MAX()可以和group by一起使用,获取每个分组中的最大值。
5、MIN()函数
- MIN()函数返回指定列的最小值。
- MIN可以和group by一起使用,获取每个分组中的
四、连接查询
先看测试连接查询的两个表结构:
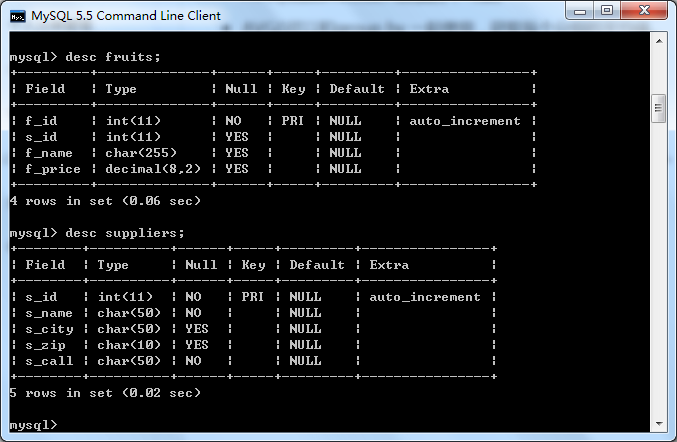
1、内联结查询
select uppliers.s_id,s_name,f_name,f_price
from fruits inner join suppliers
on fruits.s_id=suppliers.s_id;查询出来的结果:

内联结查询就是查询出两个表的关联字段符合条件的数据。
2、外联结查询
LEFT JOIN(左联结):返回包括左表中的所有记录和右表中连接字段相等的记录。
RIGHT JOIN(右联结):返回包括右表中的所有记录和左表中连接字段相等的记录。
左联结:
select suppliers.s_id,s_name,f_name,f_price
from fruits left join suppliers
on fruits.s_id=suppliers.s_id;查询出来的结果:
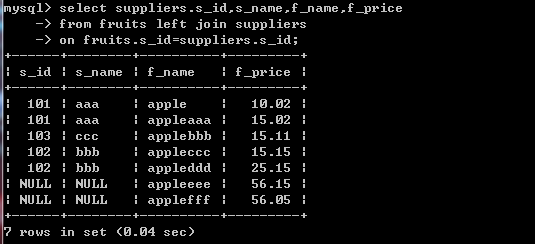
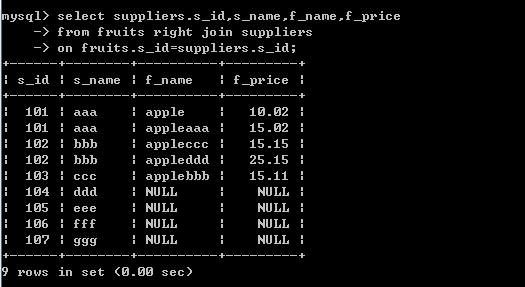
右联结:
select suppliers.s_id,s_name,f_name,f_price
from fruits right join suppliers
on fruits.s_id=suppliers.s_id;查询结果:
3、连接查询也可以实现复合条件查询,比如使用order by排序,比如在on后面使用and查询复合多个条件的数据。
五、子查询
1、带ANY、SOME关键字的子查询
下面的例子在子查询中返回的num2结果是(6,14,11,20),然后将tb1中的num1列的值与之比较,只要大于num2列的任意一个数即为符合条件的结果。
-- 先创建两张表
create table tb1(num1 int not null);
create table tb2(num2 int not null);
-- 分别向两张表中插入数据
insert into tb1 values(1),(5),(13),(27);
insert into tb2 values(6),(14),(11),(20);
-- 测试ANY关键字
select * from tb1 where num1 > any(select num2 from tb2);
-- 查询出的结果
+------+
| num1 |
+------+
| 13 |
| 27 |
+------+2、带ALL关键字的子查询
这里子查询返回(6,14,11,20),则tb1中的num1必须要大于(6,14,11,20)所有的值,才能查询出结果,也就是返回27。
mysql> select * from tb1 where num1 > all(select num2 from tb2);
+------+
| num1 |
+------+
| 27 |
+------+3、带EXISTS关键字的子查询
EXISTS后面跟的是任意一个子查询,如果这个子查询返回的有数据,EXISTS的值就是true,此时会执行外层查询语句;否则EXISTS的值是false,此时不会执行外层查询语句。
-- 这里如果子查询语句查询出来的有结果,就会执行外层查询语句;否则不会执行
mysql> select * from fruits;
+------+------+---------+---------+
| f_id | s_id | f_name | f_price |
+------+------+---------+---------+
| 1 | 101 | apple | 5.20 |
| 2 | 102 | apricot | 5.20 |
| 3 | 103 | berry | 6.20 |
| 4 | 104 | berry1 | 7.20 |
| 5 | 105 | berry3 | 1.20 |
+------+------+---------+---------+
5 rows in set (0.00 sec)
mysql> select * from fruits
-> where exists
-> (select * from fruits where f_id='0');
Empty set (0.00 sec)
mysql> select * from fruits
-> where exists
-> (select * from fruits where f_id='1');
+------+------+---------+---------+
| f_id | s_id | f_name | f_price |
+------+------+---------+---------+
| 1 | 101 | apple | 5.20 |
| 2 | 102 | apricot | 5.20 |
| 3 | 103 | berry | 6.20 |
| 4 | 104 | berry1 | 7.20 |
| 5 | 105 | berry3 | 1.20 |
+------+------+---------+---------+
5 rows in set (0.00 sec)其中上面的查询语句的where还可以加其他查询条件。
-- 这里如果子查询语句查询出来的有结果,就会执行外层查询语句;否则不会执行
mysql> select * from fruits;
+------+------+---------+---------+
| f_id | s_id | f_name | f_price |
+------+------+---------+---------+
| 1 | 101 | apple | 5.20 |
| 2 | 102 | apricot | 5.20 |
| 3 | 103 | berry | 6.20 |
| 4 | 104 | berry1 | 7.20 |
| 5 | 105 | berry3 | 1.20 |
+------+------+---------+---------+
5 rows in set (0.00 sec)
mysql> select * from fruits
-> where f_price='5.20' and exists
-> (select * from fruits where f_id='1');
+------+------+---------+---------+
| f_id | s_id | f_name | f_price |
+------+------+---------+---------+
| 1 | 101 | apple | 5.20 |
| 2 | 102 | apricot | 5.20 |
+------+------+---------+---------+
2 rows in set (0.00 sec)也可以使用NOT EXISTS,和EXISTS效果正好相反。
4、带IN关键字的子查询
使用IN关键字时,内层查询语句仅仅返回一个数据列。这个数据列的值提供给外层查询进行比较操作。NOT IN与IN效果相反。
mysql> select * from fruits where f_id in(select f_id from fruits where f_price='5.20');
+------+------+---------+---------+
| f_id | s_id | f_name | f_price |
+------+------+---------+---------+
| 1 | 101 | apple | 5.20 |
| 2 | 102 | apricot | 5.20 |
+------+------+---------+---------+
2 rows in set (0.00 sec)5、带比较运算符的子查询
子查询还可以使用“>”、“<”等比较运算符。
注意:这里使用运算符时子查询里面只能返回一条数据,否则报错。
mysql> select * from fruits where f_id=(select f_id from fruits where f_price='6.20');
+------+------+--------+---------+
| f_id | s_id | f_name | f_price |
+------+------+--------+---------+
| 3 | 103 | berry | 6.20 |
+------+------+--------+---------+
1 row in set (0.00 sec)六、合并查询结果
合并查询结果使用UNION关键字,也可以使用UNION ALL。区别在于:UNION会自动去除重复的数据,而UNION ALL会保留所有数据。
注意:使用UNION和UNION ALL时,两个select查询出来的列数和数据类型必须相同。
基本语法:
select column... from table1
union [all]
select column... from table2七、为表和字段取别名
1、为表取别名
给表取别名经常用在连接查询里面或多表查询中。
基本语法:表名 [as] 表别名
示例:
mysql> select f.* from fruits as f where f.f_price='5.20';
+------+------+---------+---------+
| f_id | s_id | f_name | f_price |
+------+------+---------+---------+
| 1 | 101 | apple | 5.20 |
| 2 | 102 | apricot | 5.20 |
+------+------+---------+---------+
2 rows in set (0.03 sec)2、为字段取别名
基本语法:列名 [as] 列别名
示例:
mysql> select f.f_name as fruit_name,f.f_price from fruits f;
+------------+---------+
| fruit_name | f_price |
+------------+---------+
| apple | 5.20 |
| apricot | 5.20 |
| berry | 6.20 |
| berry1 | 7.20 |
| berry3 | 1.20 |
+------------+---------+
5 rows in set (0.03 sec)八、使用正则表达式查询
| 选项 | 说明 | 例子 | 匹配值示例 |
| ^ | 匹配文本的开始字符 | “^b”匹配以字母b开头的字符串 | book、big、banana |
| $ | 匹配文本的结束字符 | “st$”匹配以st结尾的字符串 | test、resist |
| . | 匹配任何单个字符 | “b.t”匹配任何b和t之间有一个字符 | bit,bat,bite |
| * | 匹配零个或多个在它前面的字符 | “f*n”匹配字符n前面有任意个字符f | fn,fan,faan,abcn |
| + | 匹配前面的字符一次或多次 | “ba+”匹配以b开头后面紧跟至少一个a | ba,bay,bare,battle |
| <字符串> | 匹配包含指定的字符串的文本 | “fa” | fan,afa,faad |
| [字符集合] | 匹配字符集合中的任意一个字符 | “[xz]”匹配x或z | dizzy,zebra, |
| [^] | 匹配不在括号中的任意字符 | [^abc]匹配任何不包含a、b、或c的字符串 | desk,fox |
| 字符串{n,} | 匹配前面的字符串至少n次 | b{2}匹配两个或更多的b | bbb,bbbb,bbbbb |
| 字符串{n,m} | 匹配前面的字符串至少n次,至多m次 |
b{2,4}匹配最少两个虽多4个b | bb、bbb、bbbb |
使用正则表达式的语法:
select * from 表名 where 列名 regexp '正则表达式';
示例:
mysql> select * from fruits where f_name regexp '^a';
+------+------+---------+---------+
| f_id | s_id | f_name | f_price |
+------+------+---------+---------+
| 1 | 101 | apple | 5.20 |
| 2 | 102 | apricot | 5.20 |
+------+------+---------+---------+
2 rows in set (0.05 sec)