首先介绍下参数模型和变参模型
机器学习算法可以被分为两大类:参数模型和变参模型。
对于参数模型,在训练过程中我们要学习一个函数,重点是估计函数的参数,然后对于新数据集,我们直接用学习到的函数对
齐分类。典型的参数模型包括感知机、逻辑斯蒂回归和线性SVM。
对于变参模型,变参模型中的参数个数不是固定的,它的参数个数随着训练集增大而增多!很多书中变参(nonparametric)被翻译为无参模型,一定要记住,不是没有参数,而是参数个数是变量!变参模型的两个典型示例是决策树/随机森林和核SVM。
KNN属于变参模型的一个子类:基于实例的学习(instance-based learning)。基于实例的学习的模型在训练过程中要做的是记住整个训练集,而懒惰学习是基于实例的学习的特例,在整个学习过程中不涉及损失函数的概念。简而言之,KNN并不去学习一个判别式函数(损失函数)而是要记住整个训练集。
在sklearn中knn的重要参数有:
n_neighbors:也就是k,对于每一个测试样本,基于事先选择的距离度量,KNN算法在训练集中找到距离最近(最相似)的k个样本
metric:距离度量方法,默认是:minkowski,它是欧氏距离和曼哈顿距离的一般化

如果p=2,则退化为欧氏距离,p=1,则退化为曼哈顿距离。使用metric参数可以选择不同的距离度量。
# -*- coding: utf-8 -*-
# @Time : 2018/7/25 16:34
# @Author : Alan
# @Email : [email protected]
# @File : knn_sk1.py
# @Software: PyCharm
from sklearn.tree import DecisionTreeClassifier
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cross_validation import train_test_split
from sklearn.preprocessing import StandardScaler
from matplotlib.colors import ListedColormap
from sklearn.tree import export_graphviz
iris = datasets.load_iris()
X = iris.data[:,[2,3]]
y = iris.target
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state = 0)
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
X_combined_std = np.vstack((X_train_std,X_test_std))
y_combined_std = np.hstack((y_train,y_test))
def plot_decision_regions(X, y, classifier,test_idx=None, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'cyan','gray')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# plot all samples
#X_test, y_test = X[test_idx, :], y[test_idx]
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
alpha=0.8, c=cmap(idx),
marker=markers[idx], label=cl)
# highlight test samples
if test_idx:
X_test, y_test = X[test_idx, :], y[test_idx]
plt.scatter(X_test[:,0], X_test[:,1], c='',
alpha=1.0, linewidth=1, marker='o',
s=55, label='test set')
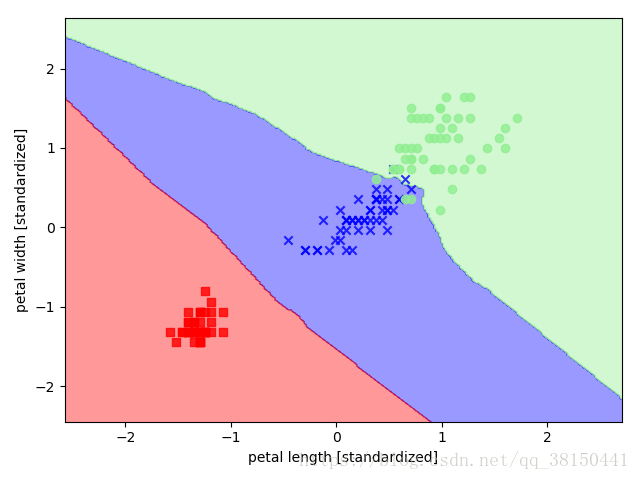
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=5,p=2,metric='minkowski')
knn.fit(X_train_std,y_train)
plot_decision_regions(X_combined_std,y_combined_std,classifier=knn,test_idx=range(105,150))
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.show()图片:
KNN需要注意的地方:
1.如果特征维度过大,KNN算法很容易过拟合。因为,对于一个固定大小的训练集,如果特征空间维度非常高,空间中最相似的两个点也可能距离很远(差别很大)。
2.对于KNN,我们只能通过特征选择和降维手段来避免维度爆炸。逻辑回归中可以用正则项来防止过拟合,但是正则项却不适用于KNN和决策树模型。
reference:
《python machine learning》