目录
1、solr的下载
从Solr官方网站(http://lucene.apache.org/solr/ )下载Solr4.10.3,根据Solr的运行环境,Linux下需要下载lucene-4.10.3.tgz,windows下需要下载lucene-4.10.3.zip。
Solr使用指南可参考:https://wiki.apache.org/solr/FrontPage。
2、solr的文件夹结构
将solr-4.10.3.zip解压:

bin:solr的运行脚本
contrib:solr的一些贡献软件/插件,用于增强solr的功能。
dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。
docs:solr的API文档
example:solr工程的例子目录:
(1)example/solr:
该目录是一个包含了默认配置信息的Solr的Core目录。
(2)example/multicore:
该目录包含了在Solr的multicore中设置的多个Core目录。
(3)example/webapps:
该目录中包括一个solr.war,该war可作为solr的运行实例工程。
licenses:solr相关的一些许可信息
3、 运行环境要求
solr 需要运行在一个Servlet容器中,Solr4.10.3要求jdk使用1.7以上,Solr默认提供Jetty(java写的Servlet容器),本篇使用Tocmat作为Servlet容器,环境如下:
(1)Solr:Solr4.10.3
(2)Jdk:jdk1.7.0_72
(3)Tomcat:apache-tomcat-7.0.53
4、 solr整合Tomcat
4.1 solrHome与solrCore
solrHome:solrhome就是solr最核心的目录, 一个solrhome中可以有多个solr实例
solrCore:一个solrCore就是一个solr实例,solr中实例与实例之间他们的索引库和文档库是相互隔离的
每个实例对外单独的提供索引和文档的增删改查服务,默认实例叫做collection1
创建一个Solr home目录,SolrHome是Solr运行的主目录,目录中包括了运行Solr实例所有的配置文件和数据文件,Solr实例就是SolrCore,一个SolrHome可以包括多个SolrCore(Solr实例),每个SolrCore提供单独的搜索和索引服务。
example\solr是一个solr home目录结构,我们把它放在了根目录下,内容如下:

上图中collection1是solrCore(Solr实例)目录。内容如下

说明:
collection1:叫做一个Solr运行实例SolrCore,SolrCore名称不固定,一个solr运行实例对外单独提供索引和搜索接口。
solrHome中可以创建多个solr运行实例SolrCore。
一个solr的运行实例对应一个索引目录。
conf是SolrCore的配置文件目录 。
data目录存放索引文件需要创建
4.2 整合步骤
第一步:安装另一个端口号的Tomcat ,防止和在eclipse上面发生端口冲突 apache-tomcat-7.0.85_test
第二步:把solr的war包复制到Tomcat的webAPP目录下
把\solr-4.10.3\dist\solr-4.10.3.war复制到E:\JavaTomcat\apache-tomcat-7.0.85_test\webapps下。
改名为solr.war(输入地址就可以省略上面的数字了)
第三步:solr.war解压。启动Tomcat,完成之后删除solr.war
第四步:把\solr-4.10.3\example\lib\ext目录下的所有的jar包添加到solr工程中
E:\JavaTomcat\apache-tomcat-7.0.85_test\webapps\solr\WEB-INF\lib
第五步:配置solrHome和solrCore
(1)创建一个solrhome(存放solr所有配置文件的一个文件夹)。\solr-4.10.3\example\solr目录就是一个标准的solrhome。
(2)把\solr-4.10.3\example\solr文件夹复制到E:\路径下,改名为solrhome,改名不是必须的,是为了便于理解。
(3)在solrhome下有一个文件夹叫做collection1这就是一个solrcore。就是一个solr的实例。一个solrcore相当于mysql中一个数据库。Solrcore之间是相互隔离。
- 在solrcore中有一个文件夹叫做conf,包含了索引solr实例的配置信息。
- 在conf文件夹下有一个solrconfig.xml。配置实例的相关信息。如果使用默认配置可以不用做任何修改。
Xml的配置信息:
Lib:solr服务依赖的扩展包,默认的路径是collection1\lib文件夹,如果没有就创建一个
dataDir:配置了索引库的存放路径。默认路径是collection1\data文件夹,如果没有data文件夹,会自动创建。
requestHandler:

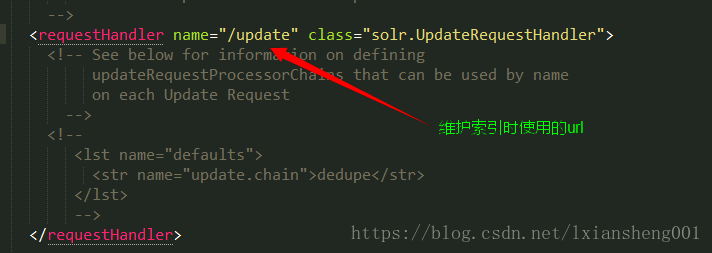
第六步:告诉solr服务器配置文件,SolrHome的位置,修改web.xml
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>E:\solrHome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>第七步:启动tomcat
第八步:访问http://localhost:8080/solr/
5、sorl后台管理
5.1 管理界面
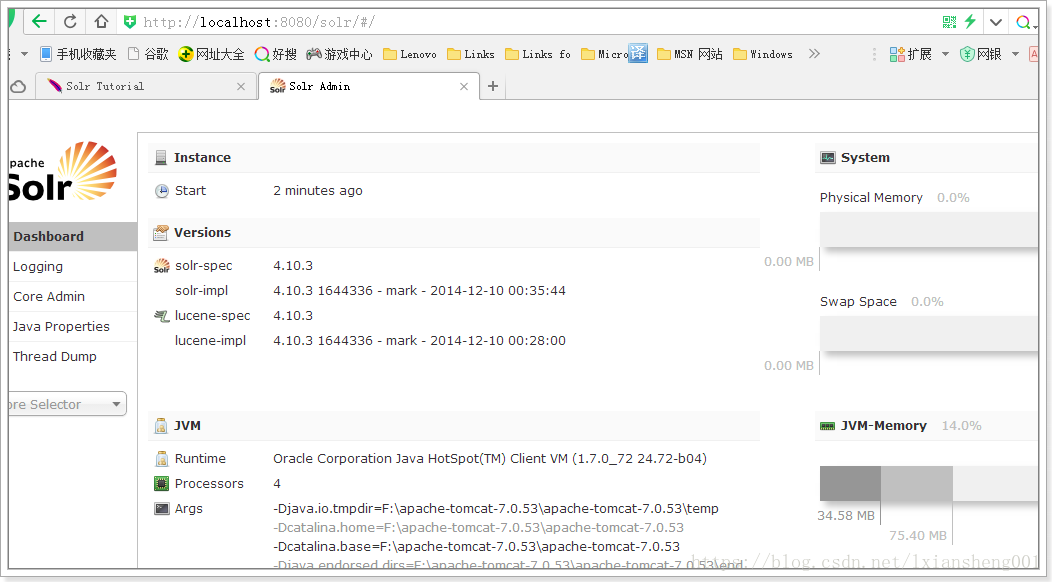
5.1.1 dashboard
仪表盘,显示了该Solr实例开始启动运行的时间、版本、系统资源、jvm等信息
5.1.2 logging solr运行日志信息
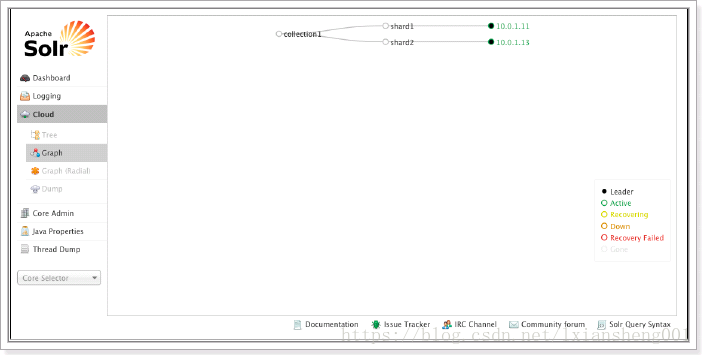
5.1.3 Cloud
Cloud即SolrCloud,即Solr云(集群),当使用Solr Cloud模式运行时会显示此菜单,如下图是Solr Cloud的管理界面:
5.1.4 Core Admin
Solr Core的管理界面。Solr Core 是Solr的一个独立运行实例单位,它可以对外提供索引和搜索服务,一个Solr工程可以运行多个SolrCore(Solr实例),一个Core对应一个索引目录。
添加solrcore:
第一步:复制collection1改名为collection2
第二步:修改core.properties。name=collection2
第三步:重启tomcat
注意:多个实例会影响solr的效率
5.1.5 Java properties
Solr在JVM 运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息。
5.1.6 Thread Dump 显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息。
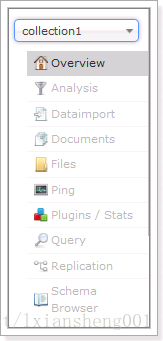
5.1.7 Core selector (重点)
选择一个SolrCore进行详细操作,如下:
5.1.8 Analysis

通过此界面可以测试索引分析器和搜索分析器的执行情况。
5.1.9 Dataimport
可以定义数据导入处理器,从关系数据库将数据导入 到Solr索引库中。
5.1.10 Document
通过此菜单可以创建索引、更新索引、删除索引等操作,界面如下:

/update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
5.1.11 Query
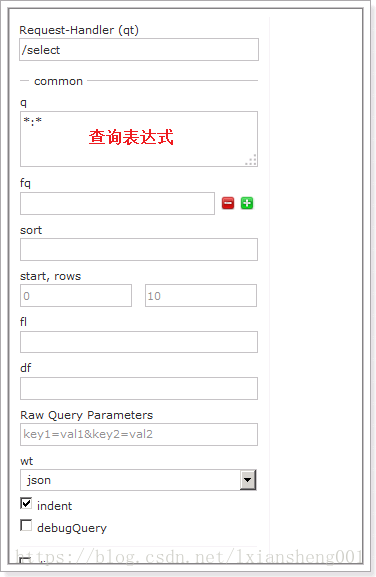
通过/select执行搜索索引,必须指定“q”查询条件方可搜索。
5.2 配置中文分词器
5.2.1 Schema.xml
schema.xml,在SolrCore的conf目录下,它是Solr数据表配置文件,它定义了加入索引的数据的数据类型的。主要包括FieldTypes、Fields和其他的一些缺省设置。
- FieldType域类型定义
下边“text_general”是Solr默认提供的FieldType,通过它说明FieldType定义的内容:

FieldType子结点包括:name,class,positionIncrementGap等一些参数:
name:是这个FieldType的名称
class:是Solr提供的包solr.TextField,solr.TextField 允许用户通过分析器来定制索引和查询,分析器包括一个分词器(tokenizer)和多个过滤器(filter)
positionIncrementGap:可选属性,定义在同一个文档中此类型数据的空白间隔,避免短语匹配错误,此值相当于Lucene的短语查询设置slop值,根据经验设置为100。
例如:搜索big car,如果document中存的是big red car,就无法搜索到了, positionIncrementGap就是设置big和car中间最大的间隔距离,只要在距离内就能搜索到.
在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括分词和过滤
索引分析器中:使用solr.StandardTokenizerFactory标准分词器,solr.StopFilterFactory停用词过滤器,solr.LowerCaseFilterFactory小写过滤器。
搜索分析器中:使用solr.StandardTokenizerFactory标准分词器,solr.StopFilterFactory停用词过滤器,这里还用到了solr.SynonymFilterFactory同义词过滤器。
- Field定义
在fields结点内定义具体的Field,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否存储多个值)等属性。如下:
<field name="name" type="text_general" indexed="true" stored="true"/>
<field name="features" type="text_general" indexed="true" stored="true" multiValued="true"/>
multiValued:该Field如果要存储多个值时设置为true,solr允许一个Field存储多个值,比如存储一个用户的好友id(多个),商品的图片(多个,大图和小图),通过使用solr查询要看出返回给客户端是数组:

- UniqueKey
Solr中默认定义唯一主键key为id域,如下
<!-- Field to use to determine and enforce document uniqueness.
Unless this field is marked with required="false", it will be a required field
-->
<uniqueKey>id</uniqueKey>Solr在删除、更新索引时使用id域进行判断,也可以自定义唯一主键。
注意在创建索引时必须指定唯一约束。
- CopyField 复制域
copyField复制域,可以将多个Field复制到一个Field中,以便进行统一的检索:
比如,输入关键字 搜索product_name和product_description,定义product_keywords、product_description、product_name的域:
<field name="product_name" type="text_ik" indexed="true" stored="true"/>
<field name="product_description" type="text_ik" indexed="true" stored="false" />
<field name="product_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="product_name" dest="product_keywords"/>
<copyField source="product_description" dest="product_keywords"/>dynamicField(动态字段)
动态字段就是不用指定具体的名称,只要定义字段名称的规则,例如定义一个 dynamicField,name 为*_i,定义它的type为text,那么在使用这个字段的时候,任何以_i结尾的字段都被认为是符合这个定义的,例如:name_i,gender_i,school_i等。
自定义Field名为:product_title_t,“product_title_t”和scheam.xml中的dynamicField规则匹配成功,如下:

创建索引

搜索索引

5.2.2 安装中文分词器
使用IKAnalyzer中文分析器。
- 第一步:把IKAnalyzer2012FF_u1.jar添加到solr/WEB-INF/lib目录下。
- 第二步:复制IKAnalyzer的配置文件和自定义词典和停用词词典到solr的classpath下。
也就是在apache-tomcat-7.0.54\webapps\solr\WEB-INF目录下新建classes目录,将配置文件和词典放进去.
- 第三步:在schema.xml中添加一个自定义的fieldType,使用中文分析器。
<!-- IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
- 第四步:定义field,指定field的type属性为text_ik
<!--IKAnalyzer Field-->
<field name="title_ik" type="text_ik" indexed="true" stored="true" />
<field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true"/>
第五步:重启Tomcat 测试

5.3 设置业务系统Field
如果不使用Solr提供的Field可以针对具体的业务需要自定义一套Field,如下是商品信息Field:
<!--product-->
<field name="product_name" type="text_ik" indexed="true" stored="true"/>
<field name="product_price" type="float" indexed="true" stored="true"/>
<field name="product_description" type="text_ik" indexed="true" stored="false" />
<field name="product_picture" type="string" indexed="false" stored="true" />
<field name="product_catalog_name" type="string" indexed="true" stored="true" />
<field name="product_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="product_name" dest="product_keywords"/>
<copyField source="product_description" dest="product_keywords"/>