前言
是否了解protobuf的编码并不影响使用。但是了解编码原理对理解不同protobuf的格式生成的编码字节大小有帮助,可以帮助我们生成占用硬盘更少的字节编码
Varint编码
Varint编码中,每7位为一组表示2位16进制的数字,因为每一个字节是8位,所以在Varint中最高位是有特殊作用的,它用来表示后续是否还有内容,1代表后续还有内容,0代表为最后一个字节的内容。
Varint编码的时候,是把目标数字转换为二进制,然后7位一组进行编码,并以小端的方式进行编码,也就是说低位放低字节,高位存高字节。
150 对应的二进制 10010110
第一组 000 0001 第二组 0010110
10010110 00000001
9 6 0 1
所以 set 150 对应Varint编码是 9601protocolbuf编码原理
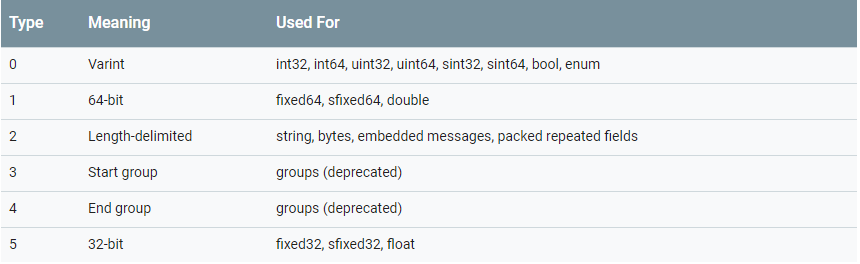
不同的类型,有的不同的类型号。protobuf的编码第一个部分总是 (field_number << 3) | wire_type 的编码,wire_type 就是上图的类型。field_number是Varint编码,它的有效位只有7位,其最高有效位代表后续是否有内容。其余的编码就是对于类型的设置的值的编码了。其实从第一部分最后一个字节的低3位就可以看出来它是什么类型的数据。
message Test{
required int a = 1;
}
我们set_a(150),把它编码之后输出出来是这样的:
08 96 01
0000 0100 从第一个字节低三位看出来是Varint类型,那么剩余150设置的值开始进行Valint编码Varint正数和负数的编码
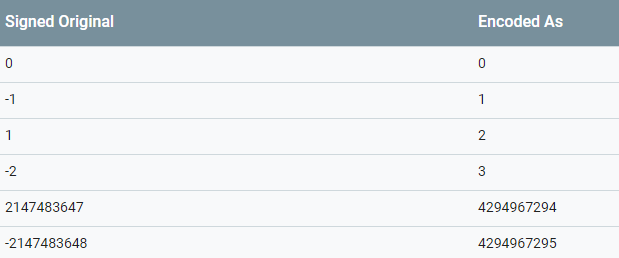
Varint编码的时候如果遇见负数,就会把它编码上十个字节,它就像用无符号来表示有符号。但是如果我们使用sint32/sint64 , Varint 就会使用Zig-zag的方式进行编码,这样编码的字节数就降了下来,它的公式是sint32 对应 (n << 1) ^ (n >> 31) ,sint64 对应 (n<<1) ^ (n>>63),右移是算术右移。对应的转换图
Strings 编码
第一个部分的编码还是同样的,用(field_number << 3) | wire_type 编码,紧接着的是后续UTF-8编码的长度大小,然后是后续UTF-8编码
message Test2 {
optional string b = 2;
}
set_b("testing");
12 07 74 65 73 74 69 6e 67 7 代表后续UTF-8编码长为7Embedded Messages 编码
首先Embedded 很像内置类
message Test1 {
optional int32 a = 1;
}
message Test3 {
optional Test1 c = 3;
}它的编码方式,先是(field_number << 3) | wire_type , 然后是后续编码的大小,后续编码是上一Messages的编码