本文很多图片显示错误,正在修复中。。。。。。
一些惨不忍睹的错误:

一点随想
事实上做深度学习的端到端映射做多了,就知道这里面新花样并不多,在网络结构上巧妙一点,或者说用多个映射来做结构上的创新,是比较常见的。(这让人想起了所谓的数据结构头脑风暴:说的是面试问题的解答不外乎是”堆”,”栈”,”队列”,”链表”的东拼西凑尝试解决,而此处的”堆”,”栈”,”队列”,”链表”变成了”CNN”,”RNN”,”LSTM”,”GAN”等等罢了。)
快速入门
我建议看如下两篇:
看图说话的AI小朋友——图像标注趣谈(上)
看图说话的AI小朋友——图像标注趣谈(下)
seq2seq模型
(这一段参考”Image Caption浅谈”)在正式介绍image caption之前,需要谈谈机器翻译领域大名鼎鼎的seq2seq模型,思考这样一个问题,在翻译的时候,不同语言表达同样意思的时候,可能长度不一致,那么翻译模型如何解决这个问题呢?
seq2seq打破了固定输入输出的模型,seq2seq模型是以编码(Encode)和解码(Decode)架构方式。Encoder通过学习输入,将其编码成一个固定大小的状态向量S,继而将S传给Decoder,Decoder再通过对状态向量S的学习来进行输出。具体实现就是用RNN(LSTM)对输入进行编码,得到固定长度的状态向量,再用RNN(LSTM)进行解码,框架如下图所示:
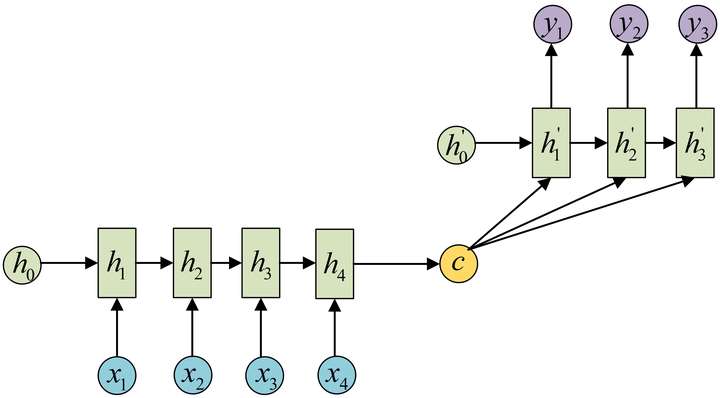
具体最早适用于机器翻译:
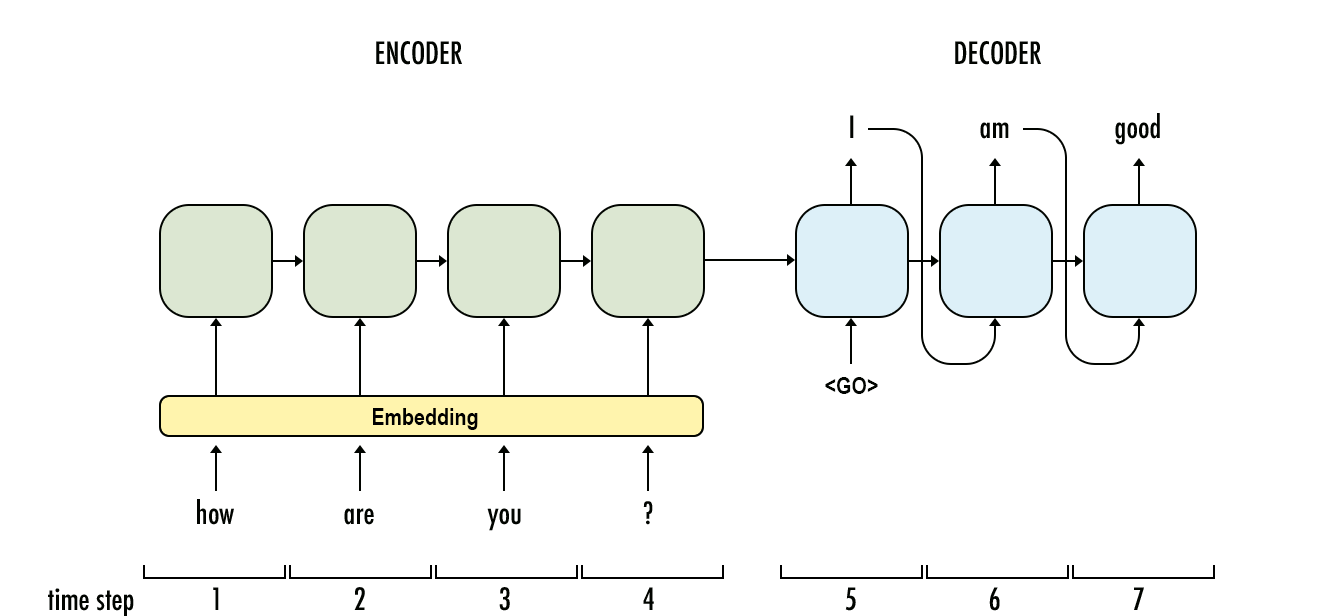
现在要谈谈什么叫注意力机制? Attention-based mechanism:
以英语-法语翻译为例,给定一对输入序列“they are watching”和输出序列“Ils regardent”,解码器在时刻1可以使用更多编码了“they are”信息的背景向量来生成“Ils”,而在时刻2可以使用更多编码了“watching”信息的背景向量来生成“regardent”。这看上去就像是在解码器的每一时刻对输入序列中不同时刻分配不同的注意力。这也是注意力机制的由来。(参考博客文章:”Seq2seq模型及注意力机制”)
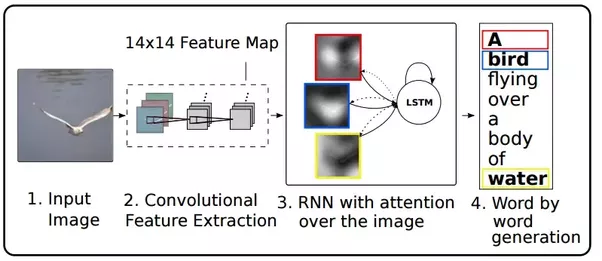
各种方法图解
利用BRNN与RCNN做视觉与语言数据的对齐:

带有视觉标记的自适应 Attention 模型(Adative Attention Model with a Visual Sentinel),在每一个 time step,模型决定更依赖于图像还是 Visual Sentinel。其中,visual sentinel 存放了 decoder 已经知道的信息。
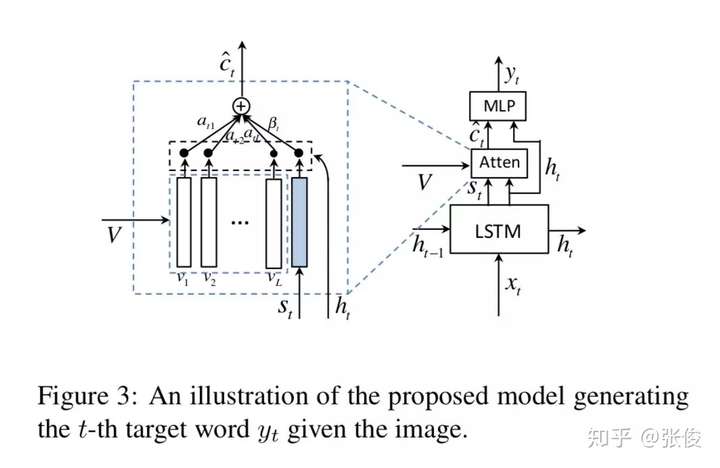
(参考“看图说话的AI小朋友”)
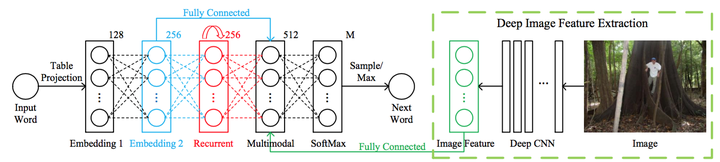
百度研究院的m-RNN模型,模型的输入是图像和与图像对应的标注语句(比如在上图中,这个语句就可能是a man at a giant tree in the jungle)。其输出是对于下一个单词的可能性的分布;模型在每个时间帧都有6层:分别是输入层、2个单词嵌入层,循环层,多模型层和最后的Softmax层;循环层的维度是 维,在其中进行的是对 时刻的单词表达向量 和 时刻的循环层激活数据 的变换和计算,具体计算公式是: 。
其中,函数 是 ,这个非线性激活函数在本专栏的CS231n笔记系列中已经详细介绍过,这里略过。而 是为了将 映射到和 同样的向量空间中所做的变换;512维的多模型层连接着模型的语言部分和图像部分。图像部分就是上图中绿色虚线包围的部分,其本质是利用深度卷积神经网络来提取图像的特征。在该文中,使用的是大名鼎鼎的AlexNet的第七层的激活数据作为特征数据输入到多模型层,如此就得到了图像特征向量I。而语言部分就是包含了单词嵌入层和循环层;
NIC模型:2014年11月,谷歌的Vinyals等人发布了论文《Show and Tell: A Neural Image Caption Generator》,推出了NIC(Neural Image Caption)模型。
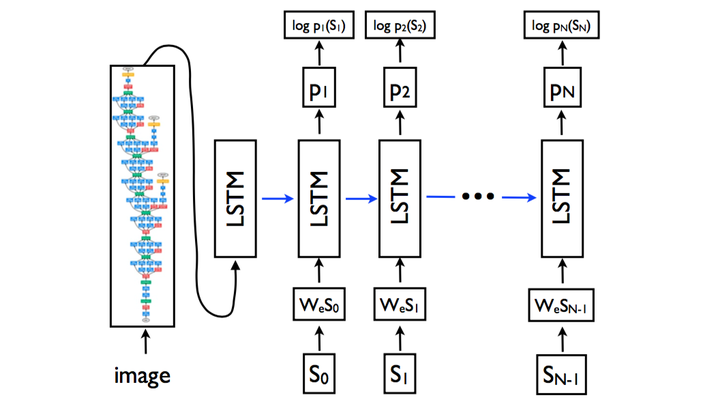
图像特征部分是换汤不换药:我们可以看见,图像经过卷积神经网络,最终还是变成了特征数据(就是特征向量)出来了。唯一的不同就是这次试用的CNN不一样了,取得第几层的激活数据不一样了,归根结底,出来的还是特征向量;但是!图像特征只在刚开始的时候输入了LSTM,后续没有输入,这点和m-RNN模型是不同的!单词输入部分还是老思路:和m-RNN模型一样,每个单词采取了独热(one-hot)编码,用来表示单词的是一个维度是词汇表数量的向量。向量和矩阵 相乘后,作为输入进入到LSTM中。使用LSTM来替换了RNN。LSTM是什么东西呢,简单地来说,可以把它看成是效果更好RNN吧。为什么效果更好呢?因为它的公式更复杂哈哈?(并不是)。如果知友对LSTM的细节感兴趣,想要理解LSTM。
《What Value Do Explicit High Level Concepts Have in Vision to Language Problems?》这篇论文中的模型:通过实验回答了论文题目本身提出的这个问题:在视觉到语言问题(比如图像标注)中,明确的高等级概念到底有没有价值?
直接把用CNN提取的图像特征数据扔进RNN的方法寻求的是从图像特征直接到文本,而不是先将其用更高等级的语义概念进行表达。于是作者们在当前的CNN+RNN模型中,增加了一个高等级的语义概念表达,结果发现这么一改,结果很好,出现了很大的提升。这就说明,之前稀里糊涂地把图像特征直接扔进RNN并不是一个好办法,将图像特征用高等级的语义概念表达后再输入RNN会更好!
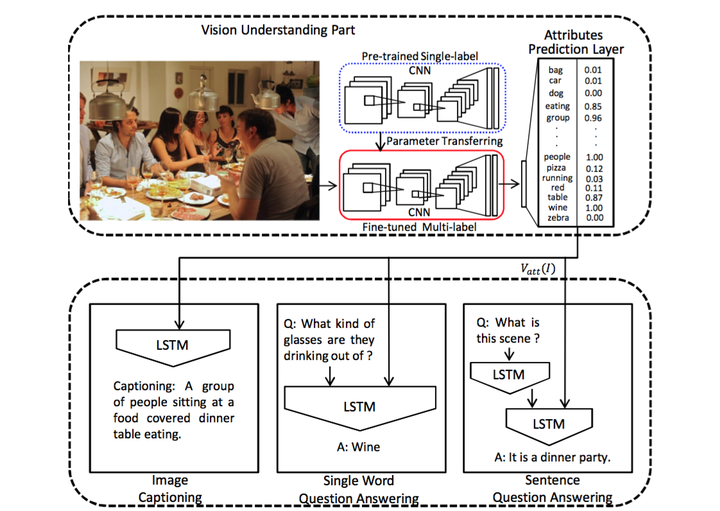
- 在语言模型部分使用的是LSTM,这一点和之前的模型没有太大区别。针对3各不同的任务(图像标注、单个单词问答,语句问答)分别实际了3个语言模型部分,这里我们只关注第一个图像标注任务。
- 改进重在视觉部分:请往上看看之前的m- RNN和NIC模型,在他们的视觉部分,图像的处理是相对简单的:图像输入CNN,然后从CNN靠后的层中取出激活数据,输入到RNN即可。然而在这里,我们看到情况变复杂了。
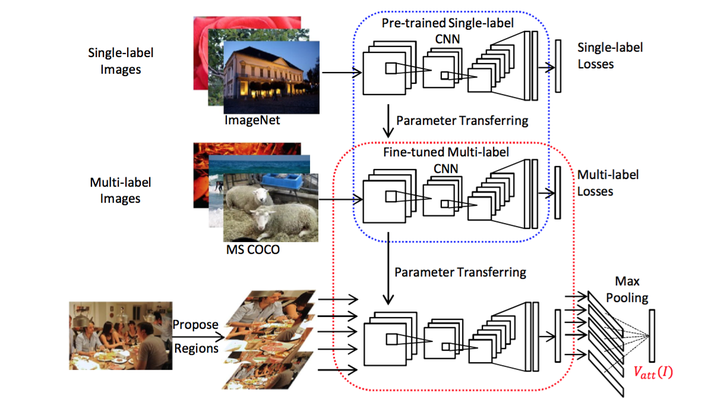
- 首先预训练一个的单标签的CNN(蓝色虚线中),然后把该CNN的参数迁移到下方多标签的CNN中(红色虚线中),并对多标签的CNN做精细调整(fine-tune)。
- 图像输入到红色虚线中的CNN,输出的是一个有高等级语义概念和对应概率的向量,并将这个向量作为语言部分LSTM的输入。
也就是说,输入LSTM的不是一个不知道到底是什么的浮点数向量了,而是我们可以理解的语义概念的概率的向量。
属性预测部分:该论文最有价值的部分,还是在它的图像分析部分中如何从图像到属性的实现,这是它的核心创新点.首先拿一个用ImageNet预训练好的VGGNet模型作为初始模型。然后再用MS COCO这样的有多标签的数据集来对这个VGGNet做精细调整(fine-tune)。精细调整具体怎么做呢?就是将最后一个全连接层的输出输入到c分类的softmax中。 代表的是词汇表的数量。然后使用逐元素的逻辑回归作为损失函数:
对于一张输入的图像,要将其分割成不同的局部。刚开始的时候是计划分割出上百个局部窗口,后来感到计算起来太耗费时间,就采取了归一化剪枝的算法将所有的方框分从 个簇,然后每个簇中保留最好的 个方框,最后加上原图,得到 个建议方框,将对应的局部输入到网络中。在使用中,作者令 ;