【题目】
题目描述:
为了维持生计,上学期期末迎考期间小可可在育红小学兼任了英语助教。首要任务就是协助英语教研室的老师们挑选合适的短文作为寒假作业布置给小朋友们,以提高他们的英语阅读能力。
挑选短文有一个评价标准。那就是同样长的文章,出现的单词越少越好,也就是说文章中词汇出现的频度越高越好。小可可根据思路设计了一个评估函数:
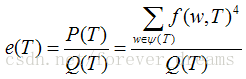
这个函数值越大,文章阅读难度越小。其中:T 是待评估的短文;Q(T)是短文中的单词数量,相同的单词重复计算;ψ( T )是短文 T 中单词构成的集合,单词是不区分大小写的,且该集合中没有重复的元素;f (w,T) 表示单词 w 在短文 T 中出现的次数。
为了简化处理,同一个英语单词的不同形态(如复数、过去式、过去分词等)算作不同单词。除了英文字母,短文中出现的数字和标点符号都不算单词,只能算作分隔符。
例如短文:
The International Olympic Committee (IOC) will decide the 2012 Olympic Games host in three years at a meeting in Singapore.
这篇短文的 = 19。 是由 The,International,Olympic,Committee,IOC,will,decide,Games,host,in,three,years,at,a,meeting,Singapore等单词构成的集合(注意:The 和 the算同一个单词),这些单词在该短文中出现的次数分别是 2,1,2,1,1,1,1,1,1,2,1,1,1,1,1,1。
因此:
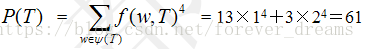
所以该短文的评估值

计算短文的评估值可不是一件轻松的事情,为了提高小可可的工作效率,请你帮她编写一个程序,只需要求出计算短文评估值所需要的 P(T) 和 Q(T) 。
输入格式:
输入文件中所有的内容构成了待评估短文 T ,并且已知待评估短文的 Q(T) ≤1000,任何一个单词的长度不超过 40 个字符,出现的次数不超过 50 。文章可能有很多段,段与段之间可能有一行空行,也可能没有。没有单词被拆分长两段。
输出格式:
在一行输出两个整数,分别代表 P(T) 和 Q(T) 。两个整数之间用一个空格隔开。
样例数据:
输入
The International Olympic Committee (IOC) will decide the 2012 Olympic Games host in three years at a meeting in Singapore.输出
61 19
输入
The International Olympic Committee (IOC) will decide the 2012 Olympic Games host in three years at a meeting in Singa23pore.输出
62 20
【分析】
(又是一道题描复杂实际上比较简单的题)
我们可以把它当做求单词的总个数和求每个单词出现的次数
这道题要注意两个点:
- 每个单词不区分大小写
- 一个单词中只能有字母,例如样例2中 "Singa23pore" 应该算为2个单词
知道了目的和注意的东西就可以愉快地敲代码了~
【Trie树】
(考试的时候竟然没有想到Trie树……)
用Trie树的话在存储每个单词的时候统计一下单词数量就行了,效率也是很高的
代码如下:
#include<cstdio>
#include<cstring>
#include<algorithm>
#define L 10005
#define N 1000005
using namespace std;
int t=0;
char s[L],rec[L];
struct node
{
int num;
int son[30];
}a[N];
void build(int l)
{
int x,i,p=0;
for(i=1;i<=l;++i)
{
x=rec[i]-'a';
if(a[p].son[x]==0)
a[p].son[x]=++t;
p=a[p].son[x];
}
a[p].num++;
}
int main()
{
// freopen("assess.in","r",stdin);
// freopen("assess.out","w",stdout);
int i,l,size,sum=0;
long long ans=0;
while(scanf("%s",s+1)!=EOF)
{
l=strlen(s+1);
for(i=1;i<=l;++i)
if(s[i]>='A'&&s[i]<='Z')
s[i]+=32;
for(i=1;i<=l;++i)
{
size=0;
while(s[i]>='a'&&s[i]<='z')
{
rec[++size]=s[i];
i++;
}
if(s[i-1]>='a'&&s[i-1]<='z')
{
sum++;
build(size);
}
}
}
for(i=1;i<=t;++i)
ans+=1ll*a[i].num*a[i].num*a[i].num*a[i].num;
printf("%lld %d",ans,sum);
// fclose(stdin);
// fclose(stdout);
return 0;
}【哈希】
(哈希写挂了……)
用哈希的话就是记录一下每个单词的哈希值,然后统计数量就可以了
给大家推荐一个大的质数:212370440130137957(反正我做哈希的题一般不用unsigned long long的话都用这个)
代码如下:
#include<cstdio>
#include<cstring>
#include<algorithm>
#define b 30
#define N 1005
#define L 10005
#define mod 212370440130137957
using namespace std;
int hash[N];
char s[L],rec[L];
int main()
{
// freopen("assess.in","r",stdin);
// freopen("assess.out","w",stdout);
int i,l,sum=0,num=1;
long long size,ans=0;
while(scanf("%s",s+1)!=EOF)
{
l=strlen(s+1);
for(i=1;i<=l;++i)
if(s[i]>='A'&&s[i]<='Z')
s[i]+=32;
for(i=1;i<=l;++i)
{
size=0;
while(s[i]>='a'&&s[i]<='z')
{
size=((size*b)+s[i]-'a'+1)%mod;
i++;
}
if(s[i-1]>='a'&&s[i-1]<='z')
{
sum++;
hash[sum]=size;
}
}
}
sort(hash+1,hash+sum+1);
hash[sum+1]=-1;
for(i=2;i<=sum+1;++i)
{
if(hash[i]==hash[i-1])
num++;
else
{
ans+=1ll*num*num*num*num;
num=1;
}
}
printf("%lld %d",ans,sum);
// fclose(stdin);
// fclose(stdout);
return 0;
}