一、 TF-IDF算法原理
TF-IDF是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。TF-IDF是一种统计方法,用以评估某个字词对于一个语料库中的其中一份文本的重要程度。字词的重要性随着它在文本中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆文档频率(Inverse Document Frequency)。
TF-IDF的计算过程:
第一步,计算词频TF。(单个文本中某个词的词频)

第二步,计算逆文档频率IDF。(这里需要计算整个语料库,语料库由多个文本组成)
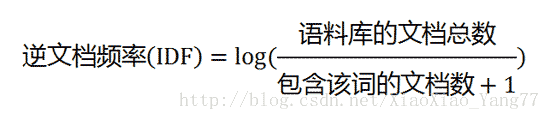
分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。
第三步,计算TF-IDF。
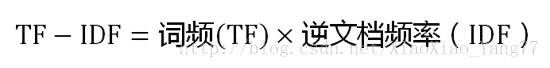
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以”词频”衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。
示例:假如某篇文本分词后有1000个词,”旅游”出现20次,则”旅游”的”词频”(TF)为0.02。语料库共有10000个文本,而语料库中出现“旅游”这个词的文本共有100个,则”旅游”的“逆文档频率”(IDF)为log(10000 / 100)=2,则TF-IDF(旅游)=0.04。
二、 文本挖掘入门—IF-IDF的计算流程
1、语料库的获取
小编通过写爬虫采集了某个新闻网站的文本共计10000个,并存入TXT文档中。采集时进行了初步的清洗,即通过正则匹配去除网页标签、特殊格式等,获取到纯文本。
2、文本的分词
这里小编采用ansj_seg来进行分词。ansj是一个基于n-Gram+CRF+HMM的中文分词的java实现。ansj分词速度达到每秒钟大约200万字左右(mac air下测试),准确率能达到96%以上。Ansj目前实现了:中文分词、词性识别、中文姓名识别 、用户自定义词典、关键字提取、自动摘要、关键字标记等功能。可以应用到自然语言处理等方面,适用于对分词效果要求高的各种项目。
ansj_seg的使用请参考下面的文档地址,这里不再赘述:
项目的github地址:https://github.com/NLPchina/ansj_seg
项目的文档地址:http://nlpchina.github.io/ansj_seg/
3、IF-IDF的计算流程
对每篇文本进行分词处理,分词后循环计算该文本中每个词的TF值,当所有文本循环完后再次计算每个词的IDF值,最后计算TF-IDF并存入到TXT文档中。下面是整个流程的Java代码实现:
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.text.DecimalFormat;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import org.ansj.domain.Result;
import org.ansj.domain.Term;
import org.ansj.splitWord.analysis.NlpAnalysis;
/**
*
* @author X.H.Yang
* 计算文档的TF值 词频(TF)=某个词在文章中出现的次数/文章的总词数
* 计算文档的IDF值 逆文档频率(IDF)=log(文档总数/包含改词的文档数)
* 计算TF-IDF值:TF-IDF = 词频(TF)*逆文档频率(IDF)
*/
public class NewsTF {
public static void main(String[] args) throws FileNotFoundException, UnsupportedEncodingException {
DecimalFormat df = new DecimalFormat("######0.0000");
//只关注这些词性的词
Set<String> expectedNature = new HashSet<String>() {
{
add("n");
add("nt");
add("nz");
add("nw");
add("nl");
add("ns");
add("ng");
}
};
//从本地读取采集好的语料库,每篇文档占用一行
FileInputStream sampleFile = new FileInputStream("C:\\Users\\Administrator\\Desktop\\news.txt");
InputStreamReader isr = new InputStreamReader(sampleFile, "UTF-8");
String text = "";
BufferedReader buread = new BufferedReader(isr);
List<List<Map.Entry<String, Double>>> Textlist = new ArrayList<>();
try {
while ((text = buread.readLine()) != null) {
//正则匹配去除文本中的标点符号
text = text.replaceAll("[\\pP+~$`^=|<>~`$^+=|<>¥×]", "");
//采用nlp分词
Result result = NlpAnalysis.parse(text);
List<Term> terms = result.getTerms();
//size用来统计每篇文档分词后的总词数
double size = 0.0;
Map<String, Double> dict = new HashMap<>();
for (int i = 0; i < terms.size(); i++) {
String key = terms.get(i).getName();
String natureStr = terms.get(i).getNatureStr(); //拿到词性
if (expectedNature.contains(natureStr)) {
size++;
if (dict.containsKey(key)) {
double count = dict.get(key) + 1;
dict.put(key, count);
} else {
dict.put(key, 1.0);
}
}
}
List<Map.Entry<String, Double>> list = new ArrayList<>();
for (Map.Entry<String, Double> entry : dict.entrySet()) {
Double tf = entry.getValue() / size;
entry.setValue(tf);
list.add(entry); //将map中的元素放入list中
}
Textlist.add(list);
System.out.println(list.size());
}
int index = 0;
for (List<Map.Entry<String, Double>> entry : Textlist) {
index ++;
for (Map.Entry<String, Double> each : entry) {
String key = each.getKey();
Double idf = getIDF(key, Textlist);
Double tf_idf = each.getValue() * idf;
each.setValue(Double.valueOf(df.format(tf_idf)));
}
entry.sort(new Comparator<Map.Entry<String, Double>>() {
@Override
public int compare(Map.Entry<String, Double> o1, Map.Entry<String, Double> o2) {
Double d1 = o1.getValue();
Double d2 = o2.getValue();
return d2.compareTo(d1);
}
//逆序(从大到小)排列,正序为“return o1.getValue()-o2.getValue”
});
System.out.println("处理了"+index+"篇文档");
}
saveTextTF(Textlist, "E:\\DataMiningLearn\\TextTFIDF.txt");
} catch (Exception e) {
System.out.println(e.toString());
}
}
//计算IDF值
public static double getIDF(String key, List<List<Map.Entry<String, Double>>> Textlist) {
try {
Double count = 0.0;
for (List<Map.Entry<String, Double>> entry : Textlist) {
for (Map.Entry<String, Double> each : entry) {
if (key.equals(each.getKey())) {
count++;
break;
}
}
}
Double idf = Math.log(Textlist.size() / (count + 1));
return idf;
} catch (Exception e) {
System.out.println(e.toString());
return 0.0;
}
}
public static void saveTextTF(List<List<Map.Entry<String, Double>>> list, String path) throws IOException {
// TODO Auto-generated method stub
System.out.println("保存TF-IDF值");
int countLine = 0;
File outPutFile = new File(path);
//if file exists, then delete it
if (outPutFile.exists()) {
outPutFile.delete();
}
//if file doesnt exists, then create it
if (!outPutFile.exists()) {
outPutFile.createNewFile();
}
FileWriter outPutFileWriter = new FileWriter(outPutFile);
for (List<Map.Entry<String, Double>> entry : list) {
for (Map.Entry<String, Double> each : entry) {
outPutFileWriter.write(each.getKey() + ":" + each.getValue() + ",");
}
outPutFileWriter.write("\n");
}
outPutFileWriter.close();
System.out.println("属性词个数:" + countLine);
}
}采集的语料库示例:

每篇文档的TF-IDF值:(值按大到小排序)
