博文TF-IDF算法介绍及实现主要介绍了TF-IDF,包括原理、不足、实战。阅读问题的提出中包含了对TF-IDF的拓展。
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
词频(TF):表示词条(关键字)在文本中出现的频率。
这个数字通常会被归一化(一般是词频除以文章总词数),以防止它偏向长的文件。即:
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。

某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。但算法不考虑语义信息,无法解决一词多义或者一义多词的问题。
在本质上 IDF 是一种试图抑制噪音的加权,并且单纯地认为文本频率小的单词就越重要,文本频率大的单词就越无用。这对于大部分文本信息,并不是完全正确的。IDF 的简单结构并不能使提取的关键词十分有效地反映单词的重要程度和特征词的分布情况,使其无法很好地完成对权值调整的功能。尤其是在同类语料库中,这一方法有很大弊端,往往一些同类文本的关键词被盖。TF-IDF算法实现简单快速,但是仍有许多不足之处:
(1)没有考虑特征词的位置因素对文本的区分度,词条出现在文档的不同位置时,对区分度的贡献大小是不一样的。
(2)按照传统TF-IDF,往往一些生僻词的IDF(反文档频率)会比较高、因此这些生僻词常会被误认为是文档关键词。
(3)传统TF-IDF中的IDF部分只考虑了特征词与它出现的文本数之间的关系,而忽略了特征项在一个类别中不同的类别间的分布情况。
扫描二维码关注公众号,回复: 12974562 查看本文章
(4)对于文档中出现次数较少的重要人名、地名信息提取效果不佳。

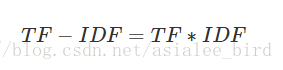
问题:此处的log的作用?为何tf是归一化而idf是取log?归一化为什么可以解决偏向问题?
这篇从历史角度粗略了解log的由来:
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明。在搜索、文献分类和其他相关领域有广泛的应用。讲起 TF/IDF 的历史蛮有意思。IDF 的概念最早是剑桥大学的斯巴克-琼斯[注:她有两个姓] (Karen Sparck Jones)提出来的。斯巴克-琼斯 1972年在一篇题为关键词特殊性的统计解释和她在文献检索中的应用的论文中提出IDF。遗憾的是,她既没有从理论上解释为什么权重IDF 应该是对数函数log(D/Dw)(而不是其它的函数,比如平方根),也没有在这个题目上作进一步深入研究,以至于在以后的很多文献中人们提到 TF/IDF时没有引用她的论文,绝大多数人甚至不知道斯巴克-琼斯的贡献。同年罗宾逊写了个两页纸的解释,解释得很不好。倒是后来康乃尔大学的萨尔顿 (Salton)多次写文章、写书讨论 TF/IDF 在信息检索中的用途,加上萨尔顿本人的大名(信息检索的世界大奖就是以萨尔顿的名字命名的)。很多人都引用萨尔顿的书,甚至以为这个信息检索中最重要的概 念是他提出的。当然,世界并没有忘记斯巴克-琼斯的贡献,2004年,在纪念文献学学报创刊 60 周年之际,该学报重印了斯巴克-琼斯的大作。罗宾逊在同期期刊上写了篇文章,用香农的信息论解释 IDF,这回的解释是对的,但文章写的并不好、非常冗长(足足十八页),把一个简单问题搞复杂了。其实,信息论的学者们已经发现并指出,其实 IDF 的概念就是一个特定条件下、关键词的概率分布的交叉熵(Kullback-Leibler Divergence)(详见上一系列)。这样,信息检索相关性的度量,又回到了信息论。
这篇从信息熵和实例角度介绍log的合理性:
所谓信息是指对不确定性(熵)的减小程度,信息的单位是比特(bit),信息量越大对于不确定性的减小程度越大。
……
回到信息检索,比如,“2012美国大选”这个查询串包含了“2012”,“美国”和“大选”3个关键词,我们应该如何定量计算它们的信息量呢?根据信息的定义,词的信息量等于它对不确定性的缩小程度。如果文档总数为230,其中214篇文档出现了“美国”,那么“美国”这个词就把文档的不确定性从230缩小为214,它所包含的信息量为log(230/214)=16;而只有210篇文档出现了“大选”,那么大选的信息量就是log(230/2^10)=20,比“美国”多了4个bit。而“的”,“什么”,“我们”这些高频词对减小文档不确定性几乎没有帮助,因而信息量为0。相信你已经发现,上面idf(w)公式中的log(n / docs(w, D))实际上就是词w的信息量了。
从博文中我们可以了解到:TF-IDF中IDF实际上是TF的权重,TF代表频率,IDF从信息熵角度出发进行定义,代表在文本集上分布的广泛程度,二者本质不同,计算方式自然不同。而对TF进行归一化能够防止TF偏向长的文件,我认为可以从机器学习中归一化的作用上理解问题:
在机器学习领域中,不同评价指标(即特征向量中的不同特征就是所述的不同评价指标)往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。
如果单文件中某一生僻词出现的频率非常高,这将导致整个文本集中该次的未归一化的TF相对较高,如果不对TF进行归一化而直接进行IDF加权计算,那么IDF这个泛化指标即使较小,但作用也十分有限。因此,需要对TF进行归一化。
算法改进—— 改进的 TF-IDF 关键词提取方法 TF-IWF
该论文实际上是改变了权重计算方法,IDF是对文档数的统计和计算,而IWF是对词语层面的统计和计算。论文表示:
这种加权方法降低了语料库中同类型文本 对词语权重的影响,更加精确地表达了这个词语在待 查文档中的重要程度。