1.1 爬虫概论
网络爬虫(Web crawler)也叫网络蜘蛛(Web spide)自动检索工具(automatic indexer),是一种”自动化浏览网络“的程序,或者说是一种网络机器人。
爬虫被广泛用于互联网搜索引擎或其他类似网站,以获取或更新这些网站的内容和检索方式。它们可以自动采集所有其能够访问到的页面内容,以供搜索引擎做进一步处理(分检整理下载的页面),而使得用户能更快的检索到他们需要的信息。
通俗的讲,就是把你手动打开窗口,输入数据等等操作用程序代替。用程序替你获取你想要的信息,这就是网络爬虫
1.2 爬虫应用
1.2.1 搜索引擎
爬虫程序可以为搜索引擎系统爬取网络资源,用户可以通过搜索引擎搜索网络上一切所需要的资源。搜索引擎是一套非常庞大且精密的算法系统,搜索的准确性,高效性等都对搜索系统有很高的要求。
1.2.2 数据挖掘
爬虫除了用来做搜索外,还可以做非常多的工作,可以说爬虫现在在互联网项目中应用的非常广泛。
互联网项目通过爬取相关数据主要进行数据分析,获取价值数据。
HttpClient抓取网页流程
使用HttpClient发送请求、接收响应很简单,一般需要如下几步:
1. 创建HttpClient对象。

2. 创建请求方法的实例,并指定请求URL。如果需要发送GET请求,创建HttpGet对象;如果需要发送POST请求,创建HttpPost对象。
3. 如果需要发送请求参数,可调用HttpGet、HttpPost共同的setParams(HetpParams params)方法来添加请求参数;对于HttpPost对象而言,也可调用setEntity(HttpEntity entity)方法来设置请求参数。
4. 调用HttpClient对象的execute(HttpUriRequest request)发送请求,该方法返回一个HttpResponse。
5. 调用HttpResponse的getAllHeaders()、getHeaders(String name)等方法可获取服务器的响应头;调用HttpResponse的getEntity()方法可获取HttpEntity对象,该对象包装了服务器的响应内容。程序可通过该对象获取服务器的响应内容。
6. 释放连接。无论执行方法是否成功,都必须释放连接。
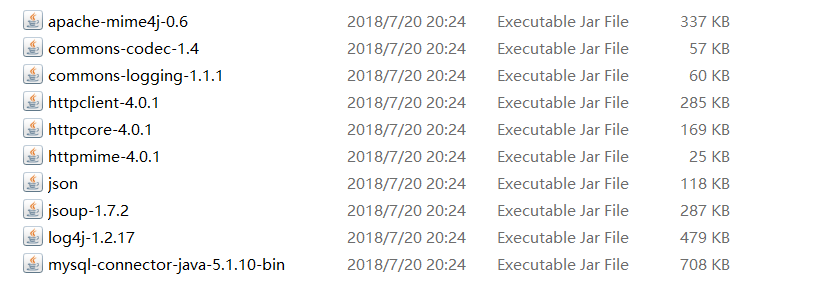
需要用的的jar包
简单案例源代码
1 import java.io.IOException; 2 3 import org.apache.http.HttpHost; 4 import org.apache.http.HttpResponse; 5 import org.apache.http.client.ClientProtocolException; 6 import org.apache.http.client.HttpClient; 7 import org.apache.http.client.methods.HttpGet; 8 import org.apache.http.conn.params.ConnRouteParams; 9 import org.apache.http.impl.client.DefaultHttpClient; 10 import org.apache.http.params.CoreConnectionPNames; 11 import org.apache.http.util.EntityUtils; 12 import org.jsoup.Jsoup; 13 import org.jsoup.nodes.Document; 14 import org.jsoup.select.Elements; 15 16 public class MyHttpClient { 17 /*** 18 * 需求:使用httpClient爬取传智播客官方网站数据 19 * @param args 20 * @throws Exception 21 * @throws ClientProtocolException 22 */ 23 public static void main(String[] args) throws Exception { 24 25 //创建HttpClient对象 26 HttpClient hClient = new DefaultHttpClient(); 27 28 29 //设置响应时间,设置传智源码时间,设置代理服务器 防止被对方判断出为爬虫程序 30 /*hClient.getParams(). 31 setParameter(CoreConnectionPNames.CONNECTION_TIMEOUT, 10000) 32 .setParameter(CoreConnectionPNames.SO_TIMEOUT, 10000) 33 .setParameter(ConnRouteParams.DEFAULT_PROXY, new HttpHost("118.190.95.43", 9001));*/ 34 35 //爬虫URL大部分都是get请求,创建get请求对象 36 HttpGet hget = new HttpGet("http://www.stdu.edu.cn/index.php/2012-04-11-16-29-00/administration.html"); 37 //向石家庄铁道大学网站发送请求,获取网页源码 38 HttpResponse response = hClient.execute(hget); 39 //EntityUtils工具类把网页实体转换成字符串 40 String content = EntityUtils.toString(response.getEntity(), "utf-8"); 41 //System.out.println(content);//整个页面的源代码 42 Document doc = Jsoup.parse(content); 43 //使用元素选择器选择网页内容 44 /*Elements elements = doc.select("ul"); 45 System.out.println(elements.text());*/ 46 //Elements elements1 = doc.select("title"); 47 48 Elements elements1 = doc.select("a"); 49 String shuchu0 = elements1.text(); 50 String shuchu1 = elements1.get(1).text(); 51 System.out.println(shuchu0); 52 System.out.println(shuchu1); 53 // Elements elements4 = doc.select("a"); 54 Elements elements4 = doc.select("a[href]"); 55 56 System.out.println(elements4.html()); 57 //附 标签选择器使用参考链接 58 59 } 60 61 }
运行结果截图: