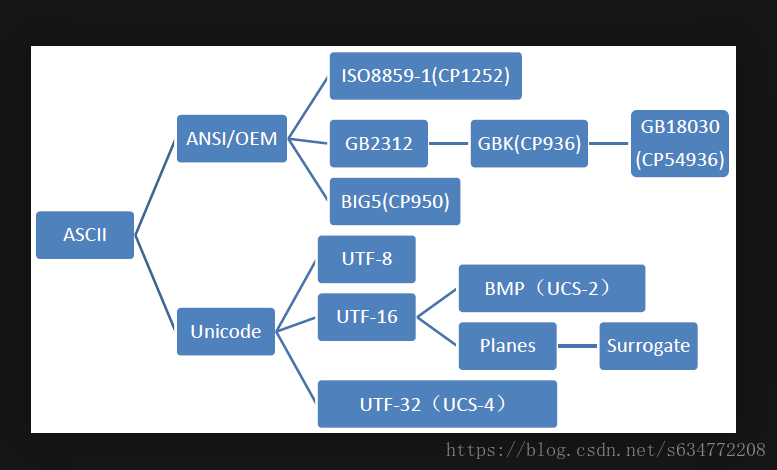
ASCII
ASCII(American Standard Code for Information Interchange),美国信息交换标准代码。20世纪60年代,美国人制定了这套字符编码,对英语字符做了统一的规定,一共包含128个字符。对于这套编码的实现,只需要用一个字节就可以表示,而且只用了7个比特位。如图:
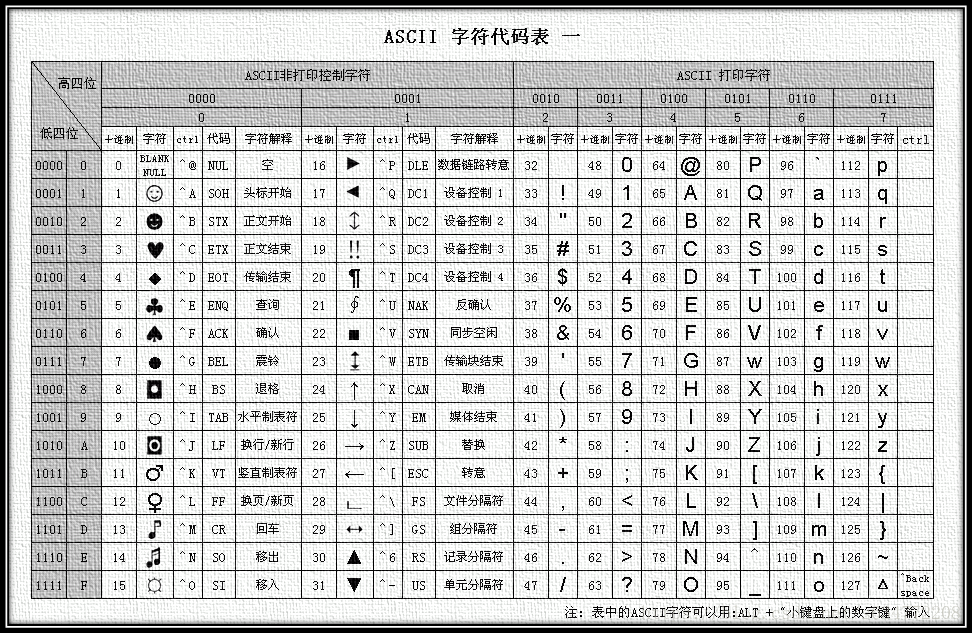
出现问题:随着计算的发展流行,这套编码在使用更多字符的国家来说,如欧洲的国家,就不够用了,于是出现了新的字符编码。
EASCII
EASCII(Extended American Standard Code for Information Interchange),扩展美国标准信息交换码。为了突破ASCII下127个字符的限制,一些欧洲国家就扩展了ASCII,将字节的第8位利用起来,这样就可以表示256个字符了,如图:
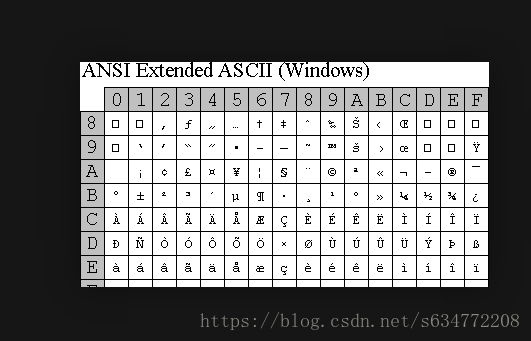
出现问题: 256个字符对于中国,日本,韩国等等这样的国家来说,远远不够,所以又出现了另外一套编码。
ANSI
ANSI(American National Standards Institute),美国国家标准学会。它是负责制定美国国家标准的非营利组织。为使计算机支持更多的语言,不同的国家和地区制定了不同的标准,并得到了ASNI的认可,全世界在表示对应国家文字的时候都通用这种编码就叫ANSI编码。这种编码实现的方式非常多,如中国的GB2312,繁体中文的BIG5,日本的JIS等等。1个字节只能表示256个字符,所以这种编码只能用多个字节来表示(注:具体的实现之后再讨论)。
出现问题:不同的国家,有不同的ANSI编码实现,相互不能兼容。若要显示一份文本,就必须要知道其编码,处理不当就会乱码。于是又出现了一套更科学的编码。
UNICODE、UCS
- 统一码联盟,他们由Xerox、Apple等软件制造商于1988年组成,并且开发了Unicode标准(The Unicode Standard)。 UNICODE目前的实现有:UTF-8,UTF-16,UTF-32。
- 国际标准化组织(ISO),他们于1984年创建ISO/IEC JTC1/SC2/WG2工作组,试图制定一份“通用字符集”(Universal Character Set,简称UCS),并最终制定了ISO 10646标准。UCS目前的实现有:UCS-2, UCS-4。
1991年前后,两个项目的参与者都认识到,世界不需要两个不兼容的字符集。于是,它们开始合并双方的工作成果,并为创立一个单一编码表而协同工作。从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码;ISO也承诺,ISO 10646将不会替超出U+10FFFF的UCS-4编码赋值,以使得两者保持一致。两个项目仍都独立存在,并独立地公布各自的标准。不过由于Unicode这一名字比较好记,因而它使用更为广泛。
总结
网友的一张图总结的很好,出自https://blog.csdn.net/luoweifu/article/details/49382969,如图: