我们知道,计算机终究是只能存储和计算0和1的机器,因为现在的半导体元件的性质决定了二进制是计算机所有存储和计算的本质。

上面这张图可能很科幻,但是计算机里就是这种东西啊。
看到知乎上有个不错的解读:
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物。他们看到8个开关状态是好的,于是他们把这称为”字节“。再后来,他们又做了一些可以处理这些字节的机器,机器开动了,可以用字节来组合出很多状态,状态开始变来变去。他们看到这样是好的,于是它们就这机器称为”计算机“。
作者:于洋
链接:https://www.zhihu.com/question/23374078/answer/69732605
来源:知乎
1.字节?字符?
学过组成原理应该了解到,计算机存储是使用了补码,工程师最初用八位二进制表示一个基本的单位,也就是一个字节(bit),而补码就是根据数字的原码转化而来(为了方便计算所以用补码存储),而一个字节的取值范围是0-255,顺便说一句,java中的字节流其实就是封装的byte数组,本质上也就是一串二进制流。
当然以上是我自己的表述,如果有问题的话请大家批评我(基础渣这一类)
然后问题来了,我们希望在屏幕上看到的可不是一串二进制的0和1,我们希望看到英文字母,看到符号,甚至看到汉字,看到所有语言的文字,而操作系统如何把存储在硬盘上的二进制0和1字节转化为字符,就涉及到字符编码的问题了。
2.Ascii码
似乎谈及字符编码就绕不开Ascii码,对的,最初的编码是美国人发明的,美国人首先对其英文字符进行了编码,也就是最早的ascii码,用一个字节的低7位来表示英文的128个字符,高1位统一为0,这时候人们已经可以使用编码来将计算机存储的二进制转换为英文字母和符号展现在电脑屏幕上,甚至连各种换行空格等等也能使用这种字编码表示,于是大家都把这个方案叫做 ANSI 的”Ascii”编码,下图为ASCII码对照字符表。
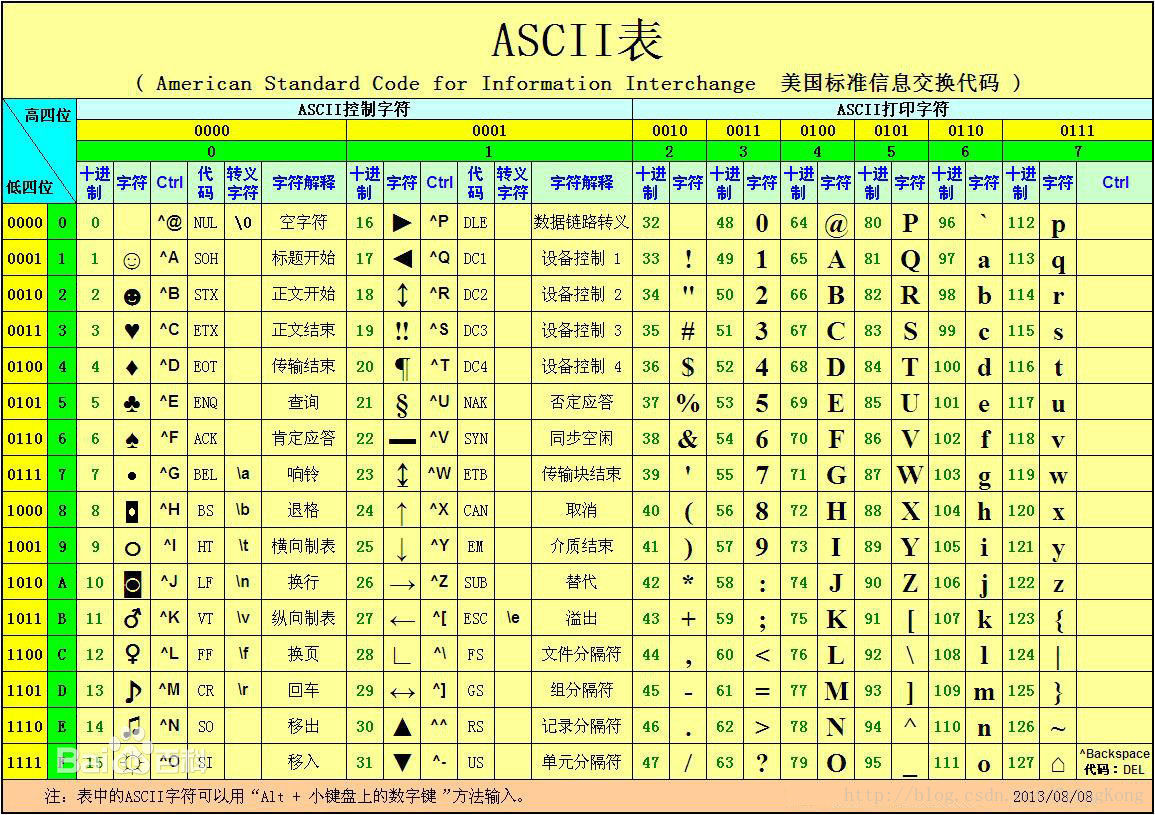
而后来,欧洲人发现这128个字符不够用啊,因为又对这种编码进行了扩充,扩充到了使用一个字节全部八位二进制,这种字符编码叫做 扩展字符集。
3.GBK和Unicode
说到现在,你可能已经对字节到字符的转化,有了一定的概念,就是通过人为规定的编码来实现,就像数学公式中的映射关系,后来计算机传入了我天朝,我们的程序员发现,这个显示器不行啊,不能显示汉字怎么办,于是他们发明了汉字的编码规则。
和一开始欧美的程序员一样,汉字的编码规则也是从二进制转换为字符(聪明的你是不是想到了用拼音~~),首先他们制定了GB 2312(国标2312)的字符集,使用两个字节,也就是16位二进制表示一个汉字,同时也将一些罗马数字,日文字符规定了进去。
后来发现这GB 2312(国标2312)还是不够用,汉字实在是太多了,于是国内程序员又对这个字符集进行了扩充,总之最后扩充成了GBK标准,GBK标准依旧使用两个字节(16位二进制)表示一个汉字,而对于Ascii本身就规定的英文字符和数字符号等,依旧使用一个字节来实现。
然而随着计算机的发展,各个国家都为了自己的便利出现了自己的编码标准,比如我朝台湾省就制定了自己的BIG5字符集。

可以看到一个“啊”字,海峡两岸的编码都不同的!!那世界上这么多国家岂不是乱了套。
因此,一个叫 ISO(国际标谁化组织)的国际组织决定着手解决这个问题。他们采用的方法很简单:废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号 的编码!他们打算叫它”Universal Multiple-Octet Coded Character Set”,简称 UCS, 俗称 “unicode“。
作者:于洋
链接:https://www.zhihu.com/question/23374078/answer/69732605
来源:知乎
4.Unicode和它的各种实现形式
Unicode制定了一个硬性的规定,所有的字符(无论是字母数字,符号还是汉字和其他语言文字)都使用两个字节(十六位二进制)实现
规矩是定下了,然而有些人就不服了,明明我们这些英文字母只需要一个字节就能存储,你非得让我用两个字节?那也就是说一个文件的存储体积就要扩大两倍了啊。这是操作系统不能承受的,因为作为程序员我们都了解,我们写的这些程序可都是英文字符,如果要扩大两倍,那无论是网络传输还是硬盘存储,都会出现巨大的问题。
因此,Unicode有了各种各样的实现形式,最出名的是UTF-8,UTF-8具体实现Unicode字符集的编码形式为:
- 单字节的字符,字节的第一位设为0,对于英语文本,UTF-8码只占用一个字节,和ASCII码完全相同;
- n个字节的字符(n>1),第一个字节的前n位设为1,第n+1位设为0,后面字节的前两位都设为10,这n个字节的其余空位填充该字符unicode码,高位用0补足。
作者:uuspider
链接:https://www.zhihu.com/question/23374078/answer/65352538
来源:知乎
也就是说,UTF-8是一种灵活设计的字符编码,对于本来只需要一个字节(8位二进制)就能存储表示的字符,就只给他一个字节来表示,而对于其他的,则按照自己的规定来进行编码表示。
而同时,也存在着UTF-16和UTF-32这种编码形式,它们都是基于Unicode的编码规则进行编码,只不过对于字符的字节填充有各种实现方式。以下是常见的编码所需要的字节存储数。
英文字母:
字节数 : 1;编码:GB2312
字节数 : 1;编码:GBK
字节数 : 1;编码:GB18030
字节数 : 1;编码:ISO-8859-1
字节数 : 1;编码:UTF-8
字节数 : 4;编码:UTF-16
字节数 : 2;编码:UTF-16BE
字节数 : 2;编码:UTF-16LE
中文汉字:
字节数 : 2;编码:GB2312
字节数 : 2;编码:GBK
字节数 : 2;编码:GB18030
字节数 : 1;编码:ISO-8859-1
字节数 : 3;编码:UTF-8
字节数 : 4;编码:UTF-16
字节数 : 2;编码:UTF-16BE
字节数 : 2;编码:UTF-16LE5.计算机上存储的二进制和文件编码的关系(实验)
首先我们新建一个文本文件,内容如下。
123
abc
啊喔额然后我们使用UE打开查看其真实的二进制内容。

这个是Windows记事本创建时默认使用的GBK编码。
可以看到:
对于数字和英文字符,确实只使用了一个字节(8位二进制,显示的31、32等等其实是二进制的十六进制格式,对应的二进制就是
0011 0001、0011 0002)对于汉字,使用了两个字节来存储,比如“啊”对应
B0 A1(二进制转换的十六进制)
我们使用UTF-8进行编码后,再打开看。

可以看到:
对于数字和英文字符,依旧只使用了一个字节(8位二进制,显示的31、32等等其实是二进制的十六进制格式,对应的二进制就是
0011 0001、0011 0002)对于汉字,使用了三个字节来存储,比如“啊”对应
E5 95 8A(二进制转换的十六进制)
在Windows中,你看到的UTF-8编码可能会不是这样,而是下图这种

可以看到前面多了EF BB BF(十六进制),这是因为微软公司夹私货的原因,**它在文件头部加入了 BOM 这种东西,**BOM可以表示:
- 文本流是Unicode的事实,是一种知识性的标志。
- 这个文本文件的文本流编码是Unicode编码中的哪一种编码为。(UTF-8,UTF-16等)
Unicode标准是允许BOM的使用的,但不是必须的,微软使用了这种东西,如果需要跨平台的话,文本就需要转码为不带BOM的UTF-8编码形式。
这里再讲一点Windows平台上的夹私货,就是Windows中的Unicode编码是什么东西,从理论上来说,Unicode字符集是一种编码标准,而真正的实现还是要靠UTF-8和UTF-16等兄弟,就像Java的接口和实现类的关系。
比如在Windows下使用了Unicode编码,就会看到刚才的文本文件内容的二进制是:

这又是什么东西呢?其实就是UTF-16LE编码!原因如下:
每一个字符严格的使用了两个字节来表示,无论是数字和英文字符
00 32、 00 61(十六进制)对应的1、a,还是汉字55 94(十六进制)对应的“啊”。其BOM是
FF FE
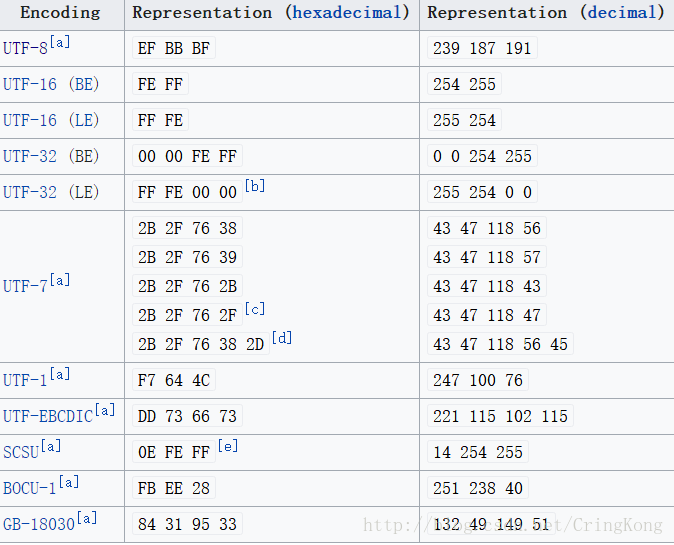
下图是各种编码允许使用对应的BOM
通过自己的实验,终于搞清楚了二进制存储和字符编码的关系。
纸上得来终觉浅,绝知此事要躬行。
看到这里的朋友,希望对你们有一些帮助。
参考资料: