2018数据库直播大讲堂峰会HBase专场,阿里云技术专家陆豪带来云数据库HBase产品架构场景解析。本文主要谈及了云HBase产品架构,进而着重分享了云HBase应用场景解析和典型客户案例,接着介绍了云HBase内核优化及特性,最后对云HBase平台运维和稳定性保障作了简要分享。
直播视频:https://yq.aliyun.com/video/play/1333
PDF下载:https://yq.aliyun.com/download/2458
以下是精彩视频内容整理:
云HBase产品架构
关系型数据库主要解决中小规模存储需求,当数据量变大后,会有分库分表以解决一定容量的需求实现复杂、业务感知,当数据量达到海量存储时,会有分布式存储、海量存储,数据库会牺牲一些一致性要求达到千万并发及QPS。
传统关系型数据库遇到的问题主要包括四个方面:
- 成本:一般需要高端存储,成本较高!
- 容量:无法满足TB、PB级别的存储。
- QPS:无法满足超高的并发要求,性能不不能横向扩展。
- 分析:缺乏分析的框架及支持。
而HBase使用普通磁盘,其分布式存储可以轻松满足从GB到PB的需求,可以自动横向扩展,满足高达5000w QPS需求,Spark on HBase原生支持分析需求,通过分析HFile可以加速分析性能。
HBase支持实时更新、增量导入、多维删除、随机查询、范围查询,它是高伸缩、高可用、高可靠、高性能、高适应在线分布式NOSQL数据库。
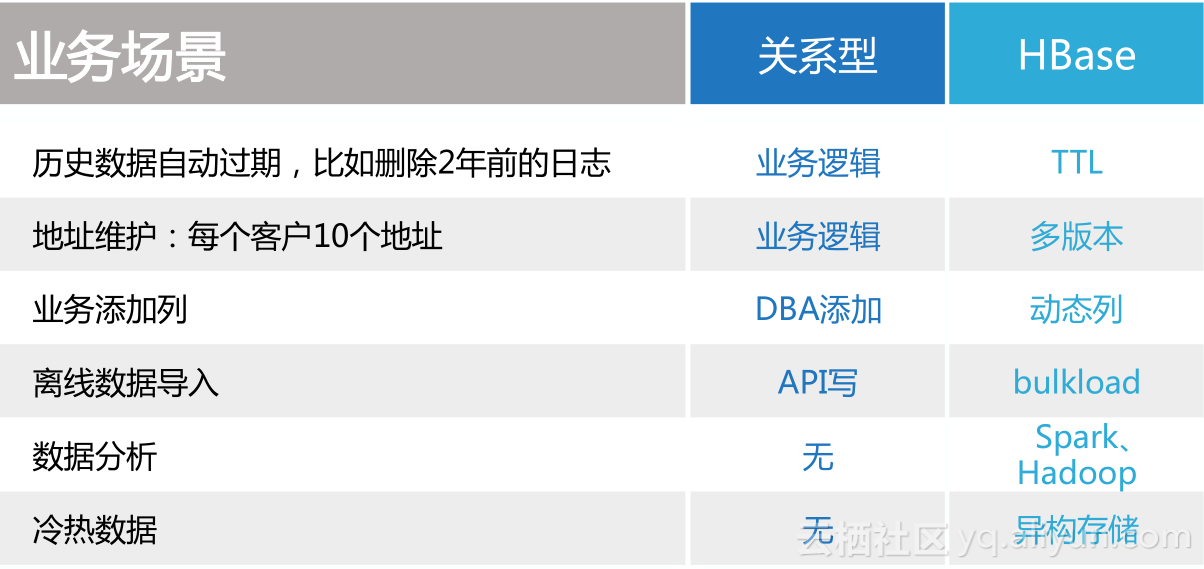
HBase还解决了其它关系型数据库解决不了的问题,支持多版本、动态列、异构存储等。
ApsaraDB HBase
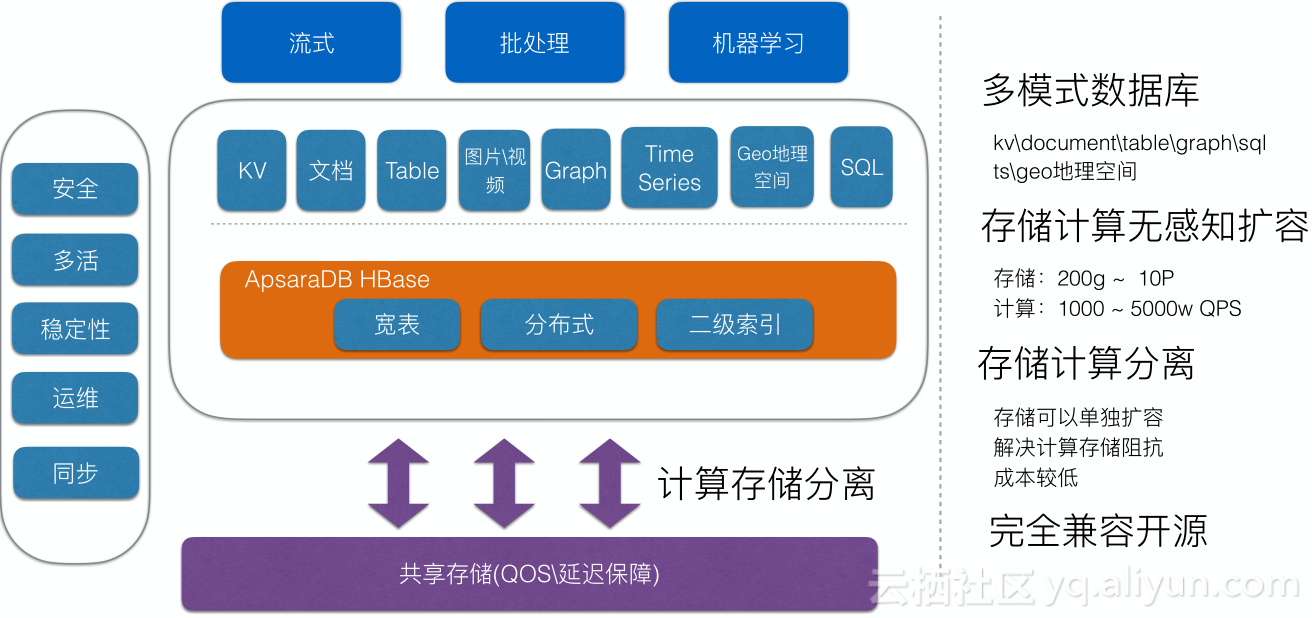
ApsaraDB HBase提供安全、多活、稳定性和同步等运维体系,底层基于共享存储做到计算存储分离,我们使用的HBase内核是在阿里HBase内部版本,相比开源版本做了很多改进,性能方面有一定的提升,HBase天然支持KV方式访问,在HBase之上集成其它组件可以提供更丰富的访问形式,我们和阿里其它产品做到很好的打通,可以很好支持流式处理、批处理和机器学习需求。
ApsaraDB HBase主要特性包括容量大(200G-10P)、动态扩容、高并发/高吞吐量(1W-5000W)、强大丰富的生态。
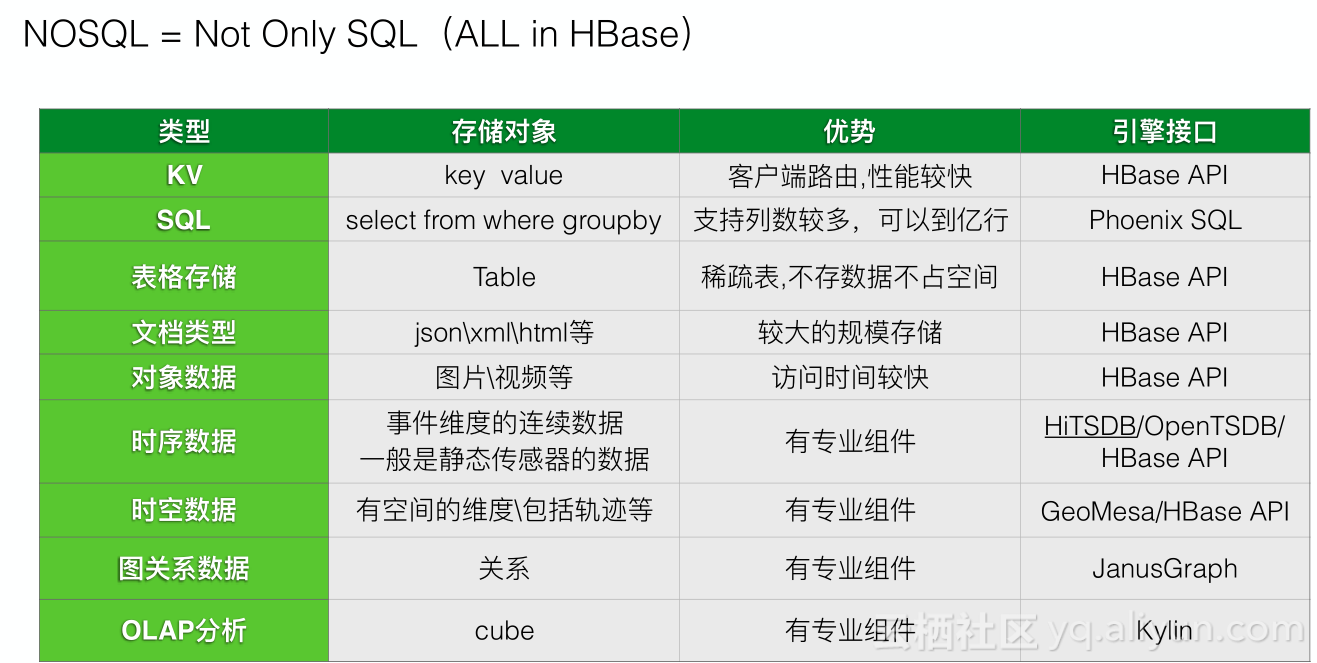
ApsaraDB HBase支持丰富接口,比如KV、SQL、表格存储、文档类型等。
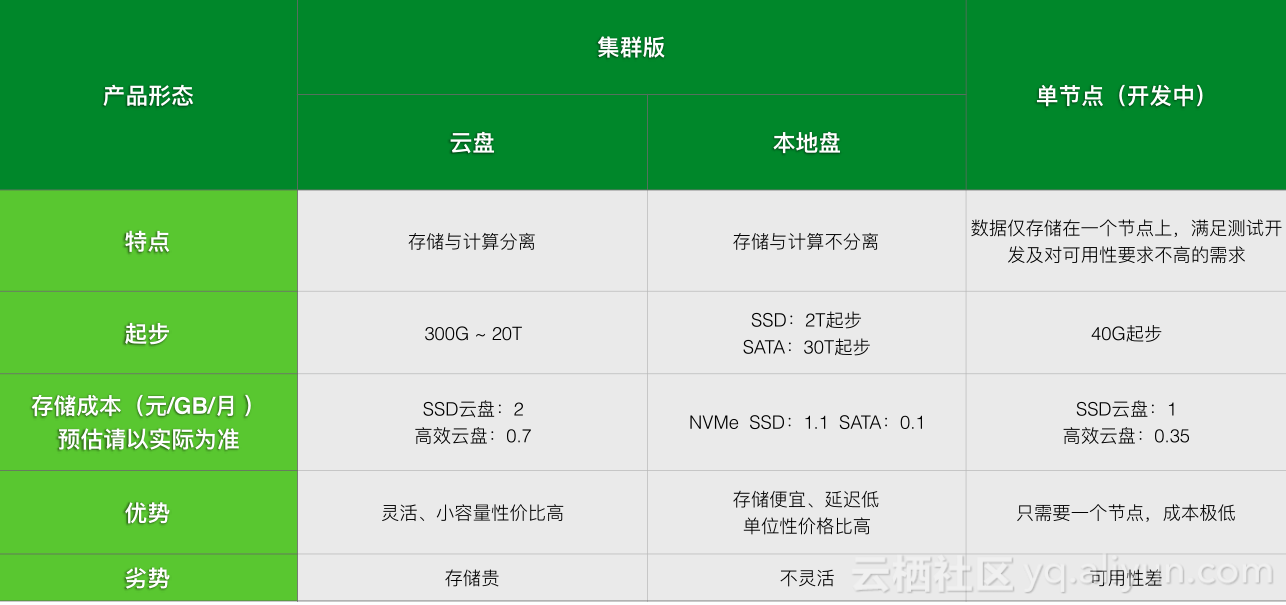
ApsaraDB HBase产品形态分为集群版和单节点版本,单节点版主要满足测试开发的需求,成本极低。集群版又分为云盘和本地盘,云盘特点是存储与计算分离,可以很方便扩容,本地盘与用物理机搭建HBase一致,存储与计算不分离,但存储便宜、延迟低。
ApsaraDB HBase与云上许多产品进行了很好的打通,其中包括支持:
- EMR Spark:包括Spark组件,可以访问HBase,分析数据。SparkStreaming可以实时写入数据到HBase;
- ODPS SQL:HBase数据可以实时同步到 ODPS,ODPS可以离线计算,满足离线数仓需求;
- ElasticSearch :HBase中的字段,实时检索的需求;
- Blink: 流式计算写入到HBase。
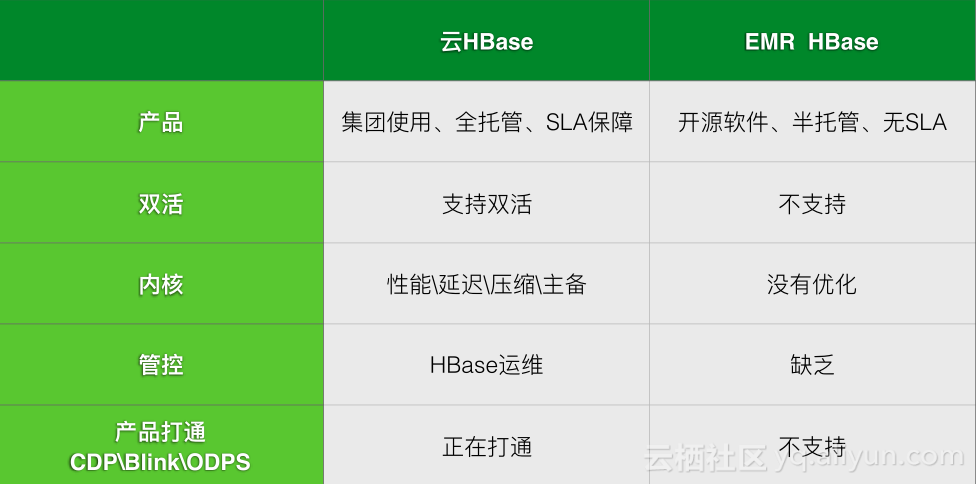
ApsaraDB HBase与开源HBase(EMR HBase或者自建)的区别如图,云HBase是全托管,所有运维工作都是阿里云来做,支持双活,内核在性能、主备多个方面进行了优化。
与竞争产品对比,我们的产品更成熟、内核性能高出2~3倍、延迟低且稳定性高。
云HBase应用场景解析和典型客户案例
HBase应用场景十分广泛,从存储类型来看,HBase支持报表类、时序类、日志类、消息类、推荐类、风控类和轨迹类数据等;从应用行业来说,电子商务、物联网、聊天软件、金融、广告商、新闻、电信等在使用。阿里内部拥有数百个集群、数百个业务,总计10000+节点、PB+数据、1亿+TPS,主要支撑日志、聊天、监控、订单、IOT、风控和搜索等业务,阿里、京东、小米、腾讯、网易、360、知乎、中国人寿、电信等都在使用HBase。
某车联网企业
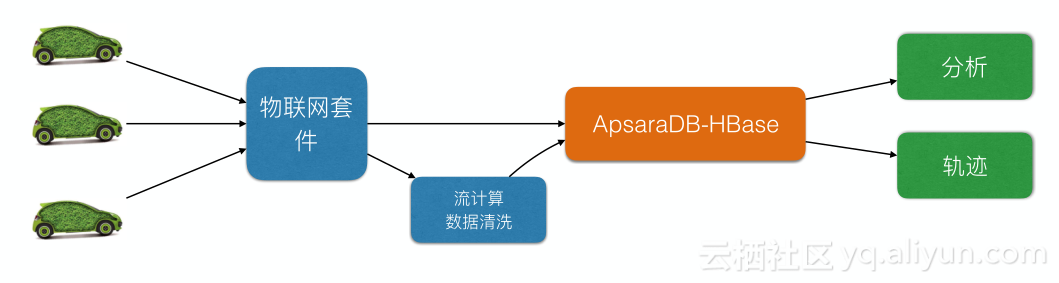
某车联网企业使用HBase架构如图所示,数据通过阿里IOT套件经过流计算清洗写入到HBase,将存储汽车轨迹数据和传感器数据进行分析计算。
Rowkey设计是用Sub(Hash(车辆ID),5) + 车辆ID + 时间,每辆车 10s上传一次,每次1KB。使用GeoHash存放轨迹信息,100万台车1年数据存储3P,读写请求达100w+。
白骑士(大数据风控公司)
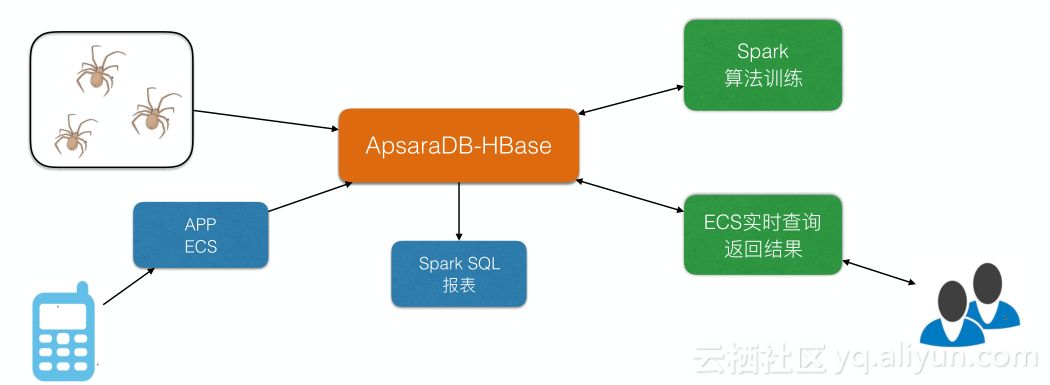
用户行为数据是高度非结构化的,数据有不同的来源,每种来源结构不一样,HBase能够很好支撑各种不同结构数据存储。爬虫和APP收集到的原始数据信息会用Spark做一些算法训练,算法结果会回写到HBase里面,使用Spark SQL来生成一些报表,会有ECS实时查询返回结果,数据量达到200T+.
Soul社交
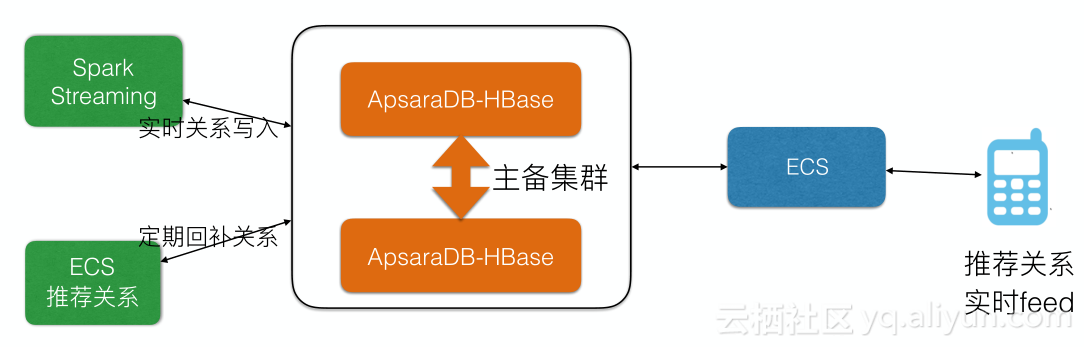
社交消息是feed流模式消息推进,feed流需要根据时间、兴趣等维度从数据库中做查询,对于系统可用性要求非常高。我们做了双集群保障,SLA要求达到99.99,单集群读写高峰QPS 1000w+,数据量达30T。
某金融公司(历史数据实时查询)
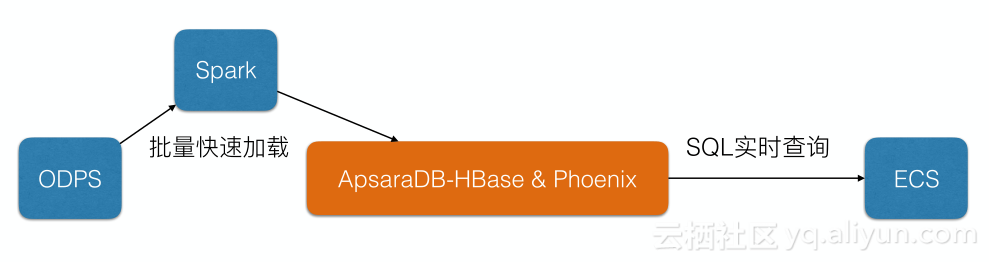
金融公司需要保留很长时间的历史数据且实时查询,HBase在该场景下有很大优势,ODPS批量加载到HBase中,HBase使用Phoenix实现SQL实时查询,单表10000亿数据,建立了很多二级索引,多个索引字段,数据量达100T。
数据流
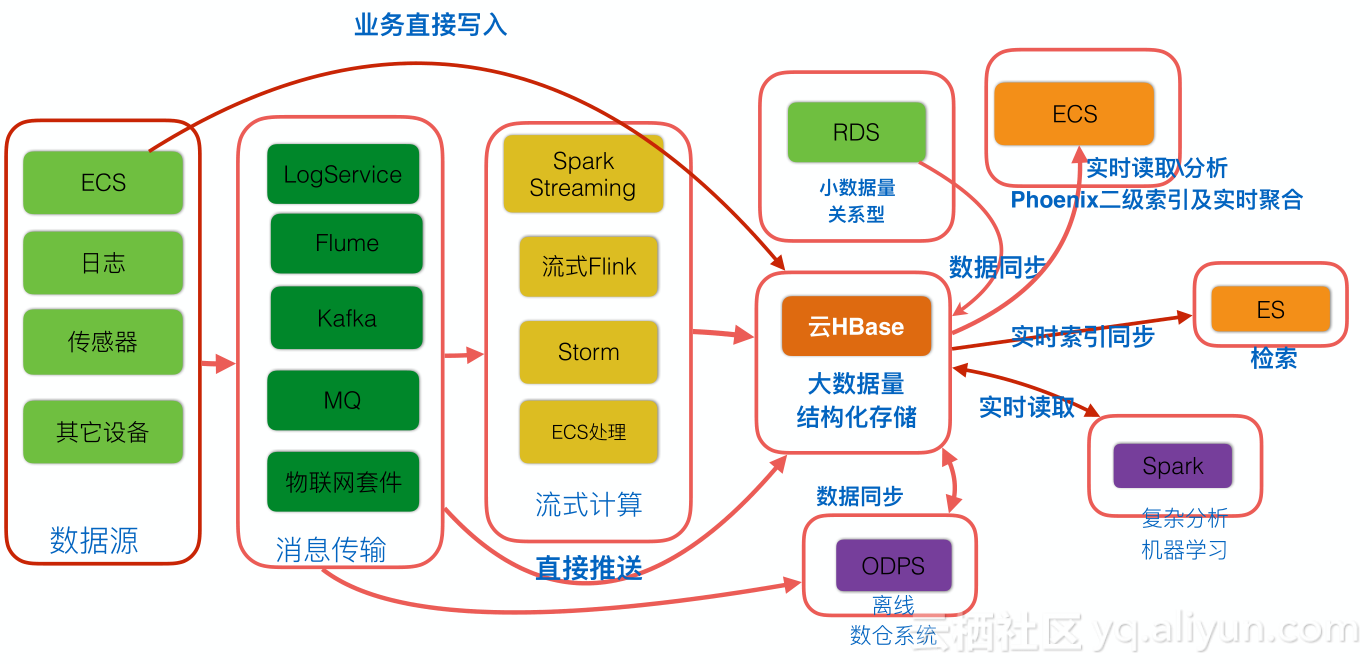
阿里云经过多年沉淀积累的HBase数据流大图如图,可以看到,数据源可以是ECS服务、传感器等,中间经过消息队列通过流式计算方式写入到HBase中,也可以在ECS上直接写入,也支持从消息队列直接写入HBase。此外,也可以通过数据同步批量写入其它数据源的数据。数据出口通过ECS实时读取分析,也可以实时索引同步ES等。
众多客户信任ApsaraDB HBase,包括大搜车、千寻位置、天虹基金、蚂蚁金服、亿方云、南华期货、白骑士等。
云HBase内核优化及特性
阿里对云HBase内核进行了数百项优化及功能改进,经历天猫双十一历练,服务阿里集团,数百个集群、10000+ 机器、QPS 10亿,最大集群2000台,在集团各个业务有广泛的应用,有2 HBase PMC、3 Committer、数十位内核贡献者贡献200+ patch。
HBase性能优化包括更高的QPS,随机读最高提升 200%以上、随机写提升50%,还有更高的压缩比,以及更平稳的读写延迟。
云HBase还具备以下特性:
- 云HBase提供增量导出功能,把增量数据实时写入到消息中间件中,再把数据同步到ODPS中做离线分析,或同步到ES做全文索引,原始数据存放HBase,检索字段存放ES。
- 云HBase还支持企业安全,使用用户名密码登录HBase,这样可以有安全白名单,还会进行数据加密。
- 云HBase支持公网访问,在自己的开发机器上即可访问,方便用户在线下部署开发测试环境,方便线下HBase集群上云。
云HBase平台运维和稳定性保障
我们的数据可靠性可以达到9个9,几乎不会丢数据,我们的服务可用性单集群99.9%、双集群99.99%。
ApsaraDB HBase提供了很多保障,包括运维自动化、自动守护服务、在线扩容节点/磁盘、内核在线升级、可用性检测/容量报警、15分钟快速交付、指标可视化和专家在线24小时在线服务。
在稳定性运维处理方面,我们会做热点检测并自动迁移、MajorCompaction分阶段处理、读写分离、大Scan报警、HDFS定时自动均衡、更多的参数在线生效。ApsaraDB HBase 双活保障可用性,切换时间20S以内。
本文由云栖志愿小组毛鹤整理,编辑百见