最近做了一些技改,由于本次618大促我作为稳定性负责人,梳理了大量系统稳定性相关的功能,平时疲于业务的迭代很多系统性的问题在大促前才梳理出来,本问也沉淀一下关于稳定性这块自己的心得。
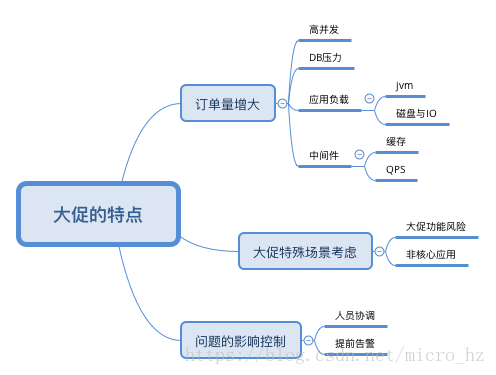
订单量的增加可能导致一些并发的问题,这块需要做好并发的控制,单机可以使用JUC提供的锁控制,现在集群一般采取redis等高可用的分布式缓存去做分布式锁,但是一般采取DB做分布式锁可靠性更高。
DB的优化也是重中之重,本次大促出现一个问题也是因为未被识别慢SQL导致。
应用负载,需要考虑GC的情况,大促期间会不会频繁GC或则生成大对象,这个需要平时的代码规范,大促前的全链路压测也能够提前暴露。
磁盘需要看是否有大日志,IO性能如何。
大促不同于同时的运营,需要考虑的事情也要从一切保证当天运行的稳定性。甚至提前半个月就要进行封网措施保证系统不引入新的问题,能够尽早发现线上bug。大促前只允许稳定性相关的需求进行发布,产品需求封版。
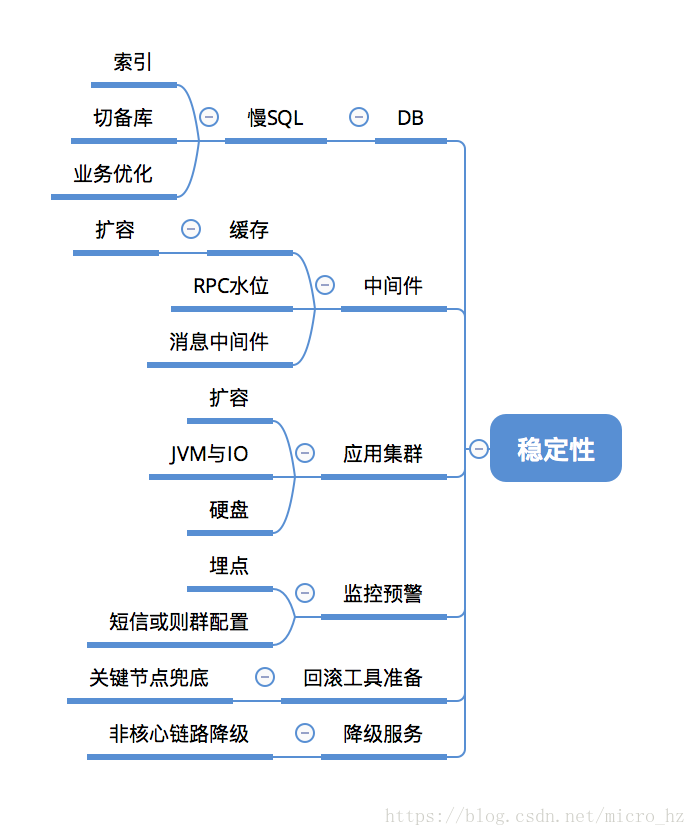
稳定性的准备主要也需要考虑这些部分。
DB
一般早期的应用都是单库,各种功能与多个应用都直连一个DB,这样不可避免的导致一些非核心业务给DB造成巨大的压力,导致核心链路受到影响,这个时候一般是采取读写分离的思想,把非核心流量打到备库,主库只做核心查询与写入操作,可能有同学会问为什么不完全做到读写分离呢?因为很多核心链路是写入再读取的操作,备库与主库的同步是至少有毫秒级延迟的,这个时候完全的读写分离会导致写入的数据查询不到导致报错,因此必须要识别流量的入口,如果存在写入再读取的链路,如果做读写分离是存在风险的。
索引是非常有用的一种优化慢SQL的手段,首先识别出一些慢SQL,可以手动EXPLAIN查看是否走索引,走索引有一些技巧,例如最左匹配索引,避免使用!=或则运算符 NOT IN等等,这些都是会走全表扫描的。当然并不是索引加的越多越好,这是会消耗空间的,MySQL会把索引文件加载到内存,这部分空间是比较昂贵的,应该合理创建索引,还有就是注意不能在作业高峰期添加索引,数据量大的情况下会导致全表锁定,存在一定的风险。
还有就是业务优化,一部分SQL只是因为开发人员写法不规范导致的,这块可以从业务上去规避,加强开发人员的培训与SQL的治理是一个长期性的工作。
虽然我们应用已经水平分表,一个我能感受到的有点就是加索引锁表同时最多影响一张分表,而不是所有表。但是单库的问题也是存在极大风险的,单点导致系统的不可用,整个集群的高可用并无意义了。因此大促还没开始,团队已经开始了DB的水平拆分,因为我们业务主要是统一水平分表,因此水平拆库之后尽量避免了跨DB事务的产生。
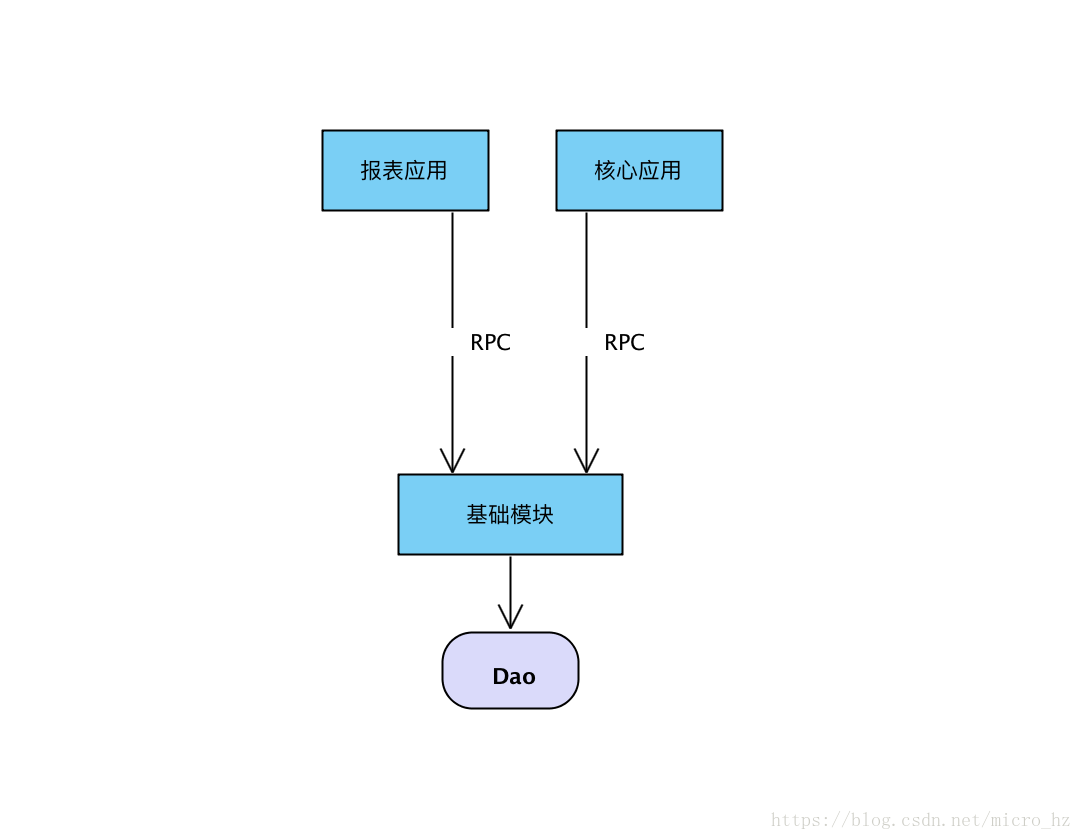
关于切备库的具体措施,我们有一个应用主要就是报表和导出报表操作,这个应用流量理论上应该全切备库,但是有两个问题,第一是底层一个SQL,在上层可能有非核心链路和链路都在调, 应用如图所示:
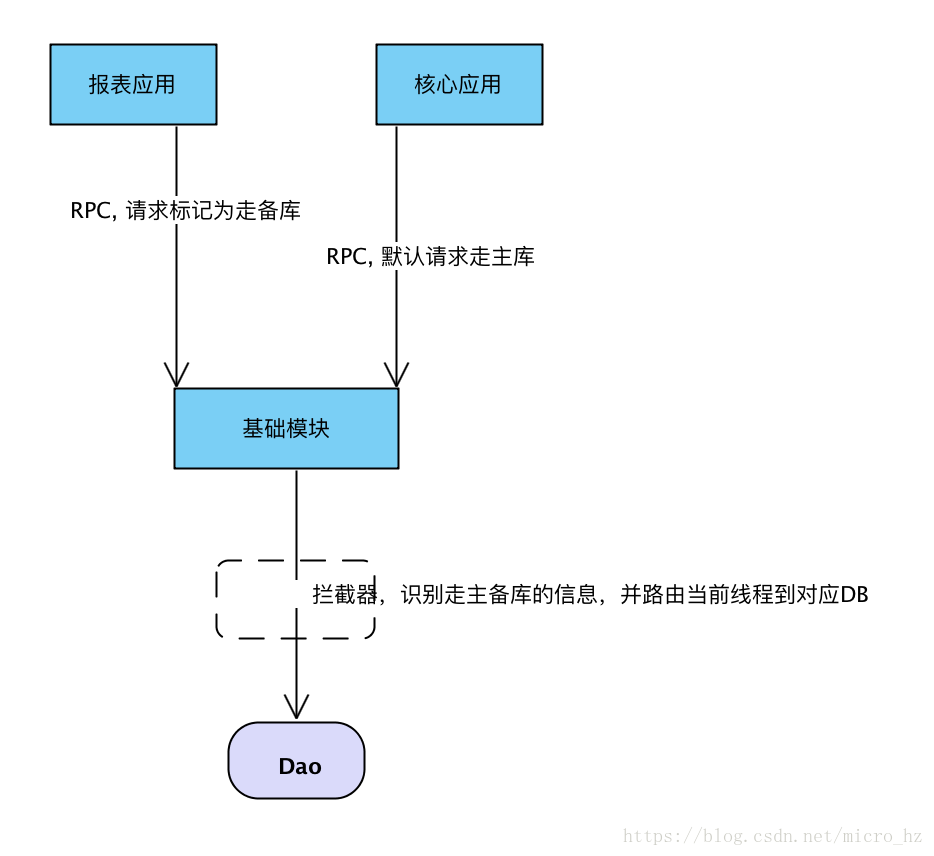
我们不太可能把代码写死,或则拆分成两个Dao。完全为了走备库单独写个Dao,的确很多小公司是这么做的,但是公司提供组件,能够当前线程的粒度去控制走主备库,并且整个请求链路能够拿到一个请求的唯一标识符,这样我们就可以在流量的入口与Dao曾统一做一个AOP切面,在流量的入口打标记是否走主备库。实现非核心链路走备库,核心链路走主库,并且底层不用维护两套SQL。对业务没有什么入侵,比较透明的切换流量。
为了避免流量切换写死如果修改需要发布代码,所以流量再设置为可配置,那就更加灵活的控制流量切换。缓存
缓存是非常好的一种设计,主要避免一些变化不频繁的热点数据进行缓存,加载到内存可以提高查询速度并且降低DB的压力,但是需要注意的是缓存是不适合做高可用的,因此要考虑到缓存丢失的情况,例如分布式锁如果强依赖缓存可能导致一些问题,或则缓存挂掉,整个流量打到DB是否会导致雪崩。这个需要梳理业务上依赖的缓存的部分一个一个去评估,这个更多是平时设计上就需要考虑的东西,而不太可能临阵去改造。大促来临前,查看水位是否需要缓存扩容,尽量避免风险。RPC
主要看调用链的稳定性,评估依赖的外部接口性能上是否能够扛住压力,因为大促前一般都会预估一个业务上的指标,例如订单量,根据这个订单量去评估系统的QPS,并且也应该做到模拟的演练,即全链路压测,看是否依赖的接口会出现瓶颈,而且在紧急情况是否有熔断机制或则优雅的降级。也要考虑保护下游的应用,当下游应用挂掉,需要进行限流操作。消息
消息一定程度解决了瞬间流量的问题,异步也提高了系统的性能,但是要考虑消息丢失和消息超时重试的问题,重试就要考虑接口的幂等性。包括RPC调用,很多时候分布式事务的产生,为了保证一致性,会一直重试到成功,因此一定要保证幂等性。应用集群
需要关注当前应用的负载,内存与磁盘和IO等信息,是否需要水平扩容,JVM配置是否合理,大日志是否需要清理。监控告警
监控能够提前发现一些线上问题,理想的告警是一般没告警,告警了一定是出问题了,因此需要平时的埋点做到精确的统计,是一个持续化建设的过程。一些比较非常重要的告警可以配置成短信信息。工具准备
各种的稳定性准备不可能覆盖全面,毕竟没人能保证代码在各种场景下是没问题的,因此必须要准备一些兜底工具,就是真实线上出现问题的预案,很多预案是我们能够提前演练的,如果出现这些情况,应该怎么去排查和解决问题,这个也是需要团队头脑风暴去覆盖的,因为很多时候业务的变更可能导致工具的过时,这也是TL后期需要安排专人维护。降级服务
大促的时期,为了保证核心链路的稳定,需要把一些非核心但是存在风险或则占用资源较多的功能做一个临时的降级服务,例如限制QPS或则直接禁用,这也可以规避一部分风险。
总结:大促对系统的考验是全方面的,并且对团队也是巨大的挑战,稳定性的建设也需要团队每个人去关注和落地,而不是牵头人,例如慢SQL的治理,永远只是稳定性负责人消灭,而其他组员天天再制造慢SQL,这是在浪费资源。稳定性建设是一个持续性的过程,理想的情况是不需要大促的稳定性工作不是吗?当然要达到那样的目标就逐渐有意识的在考虑需求迭代的过程中把稳定性建设也覆盖到,只有这样才能做到像天猫淘宝一样的“喝着茶过大促“对开发人员无感知。