个人笔记,仅供复习
1.哈夫曼树
1.1 定义:
- 带圈路径长度(WPL):设二叉树有n个叶子结点,每个叶子结点带有权值W(k),从根结点到每个叶子结点的长度为L(k),则每个叶子结点的带权路径长度之和就是:WPL = W(1)*L(1) + W(2)*L(2) + ... + W(k)*L(k)
- 最优二叉树或哈夫曼树:WPL最小的二叉树
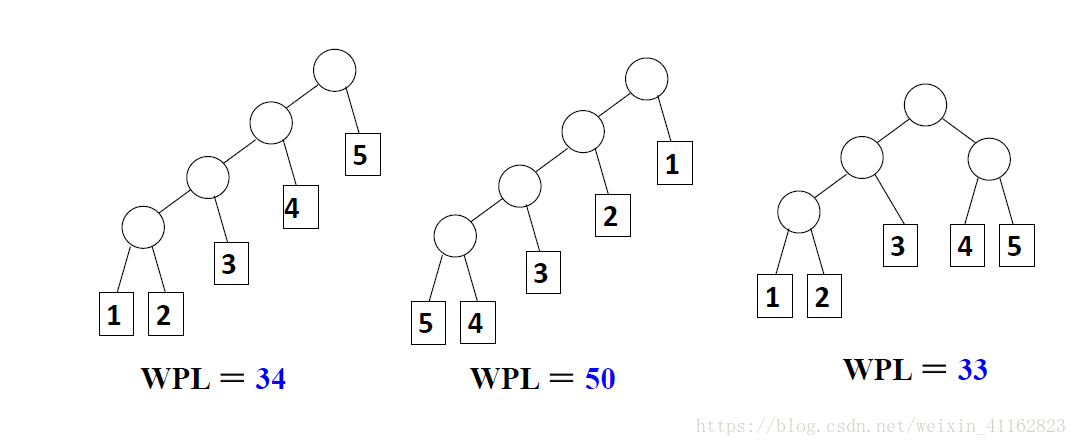
如上面三棵树,第三颗的WPL最小,所以它是哈夫曼树。
1.2 构造哈夫曼树
1.2.1 思想:每次把权值最小的两棵树合并,合并后的新树作为新的结点再与其他结点进行比较。
1.2.2 伪代码:
(1)从所有结点的集合A中选出权值最小的两个结点
(2)将这两个结点合并成一棵树,同时从集合A删除这两个结点,新结点的权值为两个子树权值的和
(3)将新结点放回集合A,重复(1),直到A为空
1.2.3 代码实例:
typedef struct TreeNode *HuffmanTree;
struct TreeNode{
int Weight;
HuffmanTree Left, Right;
}
HuffmanTree Huffman( MinHeap H )
{ /* 假设H->Size个权值已经存在H->Elements[]->Weight里 */
int i; HuffmanTree T;
BuildMinHeap(H); /*将H->Elements[]按权值调整为最小堆*/
for (i = 1; i < H->Size; i++) { /*做H->Size-1次合并*/
T = malloc( sizeof( struct TreeNode) ); /*建立新结点*/
T->Left = DeleteMin(H);
/*从最小堆中删除一个结点,作为新T的左子结点*/
T->Right = DeleteMin(H);
/*从最小堆中删除一个结点,作为新T的右子结点*/
T->Weight = T->Left->Weight+T->Right->Weight;
/*计算新权值*/
Insert( H, T ); /*将新T插入最小堆*/
}
T = DeleteMin(H);
return T;
} 1.2.4 代码分析:
以上代码是用C语言的指针来建树,同时用最小堆来存储结点,方便每次找权值最小的结点。其中的MinHeap是最小堆的结构体的指针;DeleteMin()函数是对最小堆进行删除最小权值结点,同时返回该结点地址的操作。
1.3 哈夫曼树的特点:
- 没有度为1的结点
- n个叶子结点的哈夫曼树共2n-1个结点
- 哈夫曼树的任意非叶结点的左右子树交换后仍是哈夫曼树
2.哈夫曼编码
2.1 背景:给定一段字符串,如何对字符进行编码,可以使得该字符串的编码存储空间最少?
2.2 分析:共三种方法
- 用等长ASCII编码:58 ×8 = 464位;
- 用等长3位编码:58 ×3 = 174位;
- 不等长编码:出现频率高的字符用的编码短些,出现频率低的字符则可以编码长些。
2.3 如果要进行不等长编码需要考虑的问题:
- 如何避免编码的二义性(即如何让编码意义唯一确定,不会有歧义)
- 如何让编码代价最小(让频率高的编码尽量短,频率低的可以长点)
2.3.1 避免二义性:
使任何字符的编码都不是其他字符编码的前缀码(例如,将0编码为1,那么其他字符编码就不能以1开头)。用二叉树进行编码,左分支定为0,右分支为1,字符只放在叶结点上。这样就可以确定任一个字符编码不是另一个的前缀。
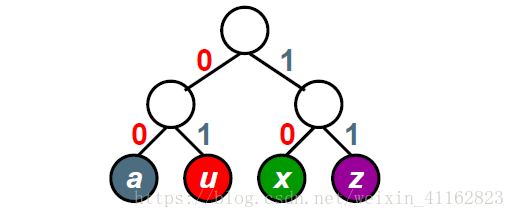
如上图a、u、x、z的编码分别为:a:00,u:01,x:10,z:11
2.3.2 编码代价最小:
这样问题就从如何让编码代价最小变成了如何让二叉树WPL最小。于是用哈夫曼树来进行建树,就可以使编码代价最小。