转自:http://www.xuebuyuan.com/1409669.html
https://blog.csdn.net/bbbeoy/article/details/72967794
针对经验风险最小化算法的过拟合的问题,给出交叉验证的方法,这个方法在做分类问题时很常用:
一:简单的交叉验证的步骤如下:
1、 从全部的训练数据 S中随机选择 中随机选择 s的样例作为训练集 train,剩余的 作为测试集 作为测试集 test。
2、 通过对测试集训练 ,得到假设函数或者模型 。3、 在测试集对每一个样本根据假设函数或者模型,得到训练集的类标,求出分类正确率。
4,选择具有最大分类率的模型或者假设。
这种方法称为 hold -out cross validation 或者称为简单交叉验证。由于测试集和训练集是分开的,就避免了过拟合的现象
二:k折交叉验证 k-fold cross validation
1、 将全部训练集 S分成 k个不相交的子集,假设 S中的训练样例个数为 m,那么每一个子 集有 m/k 个训练样例,,相应的子集称作 {s1,s2,…,sk}。
2、每次从分好的子集中里面,拿出一个作为测试集,其它k-1个作为训练集
3、根据训练训练出模型或者假设函数。
4、 把这个模型放到测试集上,得到分类率。
5、计算k次求得的分类率的平均值,作为该模型或者假设函数的真实分类率。
这个方法充分利用了所有样本。但计算比较繁琐,需要训练k次,测试k次。
三:留一法 leave-one-out cross validation
留一法就是每次只留下一个样本做测试集,其它样本做训练集,如果有k个样本,则需要训练k次,测试k次。
留一发计算最繁琐,但样本利用率最高。适合于小样本的情况。
crossvalind交叉验证
Generate cross-validation indices 生成交叉验证索引
Syntax语法
Indices = crossvalind('Kfold', N, K) K折交叉
[Train, Test] = crossvalind('HoldOut', N, P)
[Train, Test] = crossvalind('LeaveMOut', N, M)留M法交叉验证,默认M为1,留一法交叉验证
[Train, Test] = crossvalind('Resubstitution', N, [P,Q])
[...] = crossvalind(Method, Group, ...)
[...] = crossvalind(Method, Group, ..., 'Classes', C)
[...] = crossvalind(Method, Group, ..., 'Min', MinValue)
部分转载自https://blog.csdn.net/NNNNNNNNNNNNY/article/details/45789323
交叉验证是一种随机循环验证方法,它可以将数据样本随机分割成几个子集。交叉验证主要用于评估统计分析或机器学习算法的泛化能力等。
对于第一种在评估机器学习算法的泛化能力时,我们可以选择随机分割后的一部分数据作为训练样本,另一部分作为测试样本。具体实现流程如下:
Data = rand(9,3);%创建维度为9×3的随机矩阵样本
indices = crossvalind('Kfold', 9, 3);%将数据样本随机分割为3部分
for i = 1:3 %循环3次,分别取出第i部分作为测试样本,其余两部分作为训练样本
test = (indices == i);
train = ~test;
trainData = Data(train, :);
testData = Data(test, :);
end生成的随机矩阵Data:
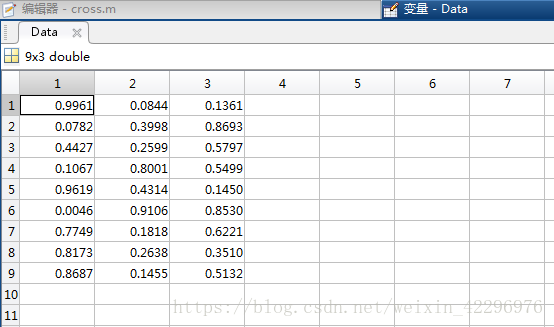
indices数据,即分成的三类,数字相同表示对应的行数为同一类:
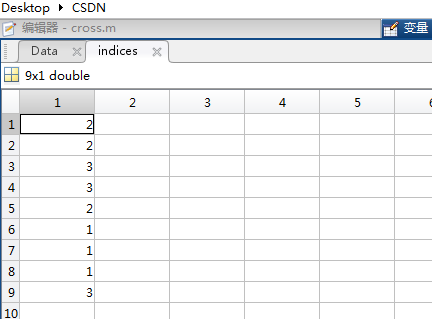
当i=3时的test数据:
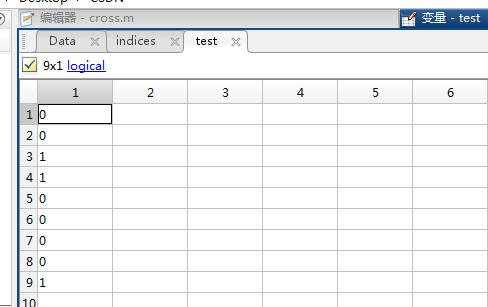
对应的train数据(即对test取反):
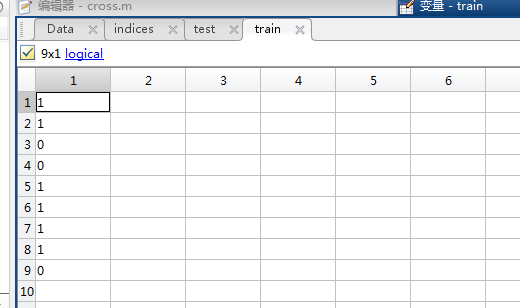
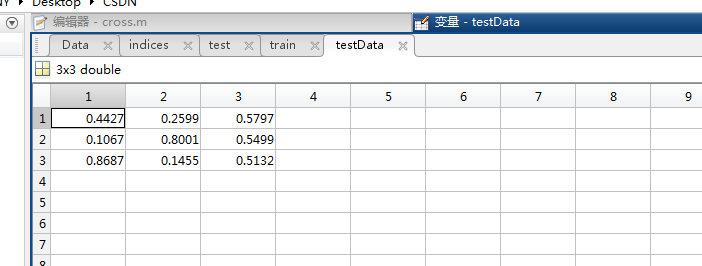
testData(即test数据中‘1’所对应的行的数据)
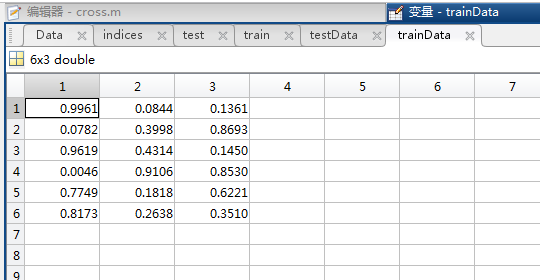
trainData:
k-折交叉验证(k-fold crossValidation):
在机器学习中,将数据集A分为训练集(training set)B和测试集(test set)C,在样本量不充足的情况下,为了充分利用数据集对算法效果进行测试,将数据集A随机分为k个包,每次将其中一个包作为测试集,剩下k-1个包作为训练集进行训练。
在matlab中,可以利用:
indices=crossvalind('Kfold',x,k);
来实现随机分包的操作,其中x为一个N维列向量(N为数据集A的元素个数,与x具体内容无关,只需要能够表示数据集的规模),k为要分成的包的总个数,输出的结果indices是一个N维列向量,每个元素对应的值为该单元所属的包的编号(即该列向量中元素是1~k的整随机数),利用这个向量即可通过循环控制来对数据集进行划分。
例:
[M,N]=size(data);//数据集为一个M*N的矩阵,其中每一行代表一个样本
indices=crossvalind('Kfold',data(1:M,N),10);//进行随机分包
for k=1:10//交叉验证k=10,10个包轮流作为测试集
test = (indices == k); //获得test集元素在数据集中对应的单元编号
train = ~test;//train集元素的编号为非test元素的编号
train_data=data(train,:);//从数据集中划分出train样本的数据
train_target=target(:,train);//获得样本集的测试目标,在本例中是train样本的实际分类情况
test_data=data(test,:);//test样本集
test_target=target(:,test);//test的实际分类情况
...........
end①indices =crossvalind('Kfold', N, K):
该命令返回一个对于N个观察样本的K个fold(意为折,有“层”之类的含义,感觉还是英文意思更形象)的标记(indices)。该标记中含有相同(或者近似相同)比例的1—K的值,将样本分为K个相斥的子集。在K-fold交叉检验中,K-1个fold用来训练,剩下的一个用来测试。此过程循环K次,每次选取不同的fold作为测试集。K的缺省值为5。 使用程序:
[m n]=size(data); %data为样本集合。每一行为一个观察样本
indices = crossvalind('Kfold',m,10); %产生10个fold,即indices里有等比例的1-10
for i=1:10
test=(indices==i); %逻辑判断,每次循环选取一个fold作为测试集 train=~test; %取test的补集作为训练集,即剩下的9个fold
data_train=data(trian,:); %以上得到的数都为逻辑值,用与样本集的选取 label_train=label(train,:); %label为样本类别标签,同样选取相应的训练集 data_test=data(test,:); %同理选取测试集的样本和标签 label_test=label(test,:); end 该命令返回一个逻辑值的标记向量,从N个观察样本中随机选取(或近似于)P*N个样本作为测试集。故P应为0-1,缺省值为0.5。 使用程序:
groups=ismenber(label,1); %label为样本类别标签,生成一个逻辑矩阵groups,1用来逻辑判断筛选
[train, test] = crossvalind('holdOut',groups); %将groups分类,默认比例1:1,即P=0.5 该命令返回一个逻辑值的标记向量,从N个观察样本中随机选取M个样本作为测试集。M的缺省值为1。值得注意的是,LeaveMOut在循环中使用不能保证产生的是互补集合,即每次循环的随机选取是独立的。如果要用互补的话还是使用Kfold命令。 使用程序:
[m,n]=size(data);
[train,test]=crossvalind('LeaveMOut',m,10)
svmStruct = svmtrain(data(train,:),groups(train)); classes = svmclassify(svmStruct,data(test,:)); cp=classperf(groups); cr=cp.CorrectRate ④[Train, Test] = crossvalind('Resubstitution',N, [P,Q]):
本函数为②的一个特殊情况。当我不想把 P*N 剩下的部分全部作为训练集的时
候使用该函数,用 Q 指定一个比例, 选取 Q*N 作为训练集。两个集合的选取以
最小化交集为原则。