在spark2.X版本后,新增了一个更高级的接口结构化流。
Structured Streaming (结构化流)是一种基于 Spark SQL 引擎构建的可扩展且容错的 stream processing engine (流处理引擎)。您可以以静态数据表示批量计算的方式来表达 streaming computation (流式计算)。 Spark SQL 引擎将随着 streaming data 持续到达而增量地持续地运行,并更新最终结果。您可以使用 Scala , Java , Python 或 R 中的 Dataset/DataFrame API 来表示 streaming aggregations (流聚合), event-time windows (事件时间窗口), stream-to-batch joins (流到批处理连接) 等。在同一个 optimized Spark SQL engine (优化的 Spark SQL 引擎)上执行计算。最后,系统通过 checkpointing (检查点) 和 Write Ahead Logs (预写日志)来确保 end-to-end exactly-once (端到端的完全一次性) 容错保证。简而言之,Structured Streaming 提供快速,可扩展,容错,end-to-end exactly-once stream processing (端到端的完全一次性流处理),而无需用户理解 streaming 。
理论就不多说了,直接上样例:
测试数据:demo_data1
{"name":"xiaoming","age":25}
{"name":"xiaohong","age":18}
{"name":"xiaobai","age":19}
{"name":"xiaoan","age":17}/Users/dongdong/Desktop/spark_contact/contact/data_test/structured_data/ 这是目录
代码:
package structstreaming
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.ProcessingTime
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
/**
* Created by dongdong on 18/1/25.
*/
object StructuredStreamingDemo {
def main(args: Array[String]): Unit = {
// 创建sparksession
val spark = SparkSession
.builder
.master("local")
.appName("StructuredStreamingDemo")
.getOrCreate()
import spark.implicits._
// 定义schema
val userSchema = new StructType().add("name", "string").add("age", "integer")
// 读取数据
val dataFrameStream = spark
.readStream
.schema(userSchema)
.format("json")
//只能是监控目录,当新的目录进来时,再进行计算
.load("/Users/dongdong/Desktop/spark_contact/contact/data_test/structured_data/")
//dataFrameStream.isStreaming
//注册成一张表
dataFrameStream.createOrReplaceTempView("Person")
// 对表进行agg 如果没有agg的话,直接报错
val aggDataFrame = spark.sql(
"""
|select
|name,
|age,
|count(1) as cnt
|from
|Person
|group by
|name,age
""".stripMargin
)
//在控制台监控
val query = aggDataFrame.writeStream
//complete,append,update。目前只支持前面两种
.outputMode("complete")
//console,parquet,memory,foreach 四种
.format("console")
//这里就是设置定时器了
.trigger(ProcessingTime(100))
.start()
query.awaitTermination()
}
}
sparkstructuredstreaming 监控file的时候,只能是有新的文件进来后再计算,没法计算相同的文件,即使这个文件发生了改变
最后,执行程序的时候,我在那个路径下,再添加一个文件
demo_data2
{"name":"xiaoming","age":25}
{"name":"xiaohong","age":18}
{"name":"xiaobai","age":19}
{"name":"xiaoan","age":17}执行如下:
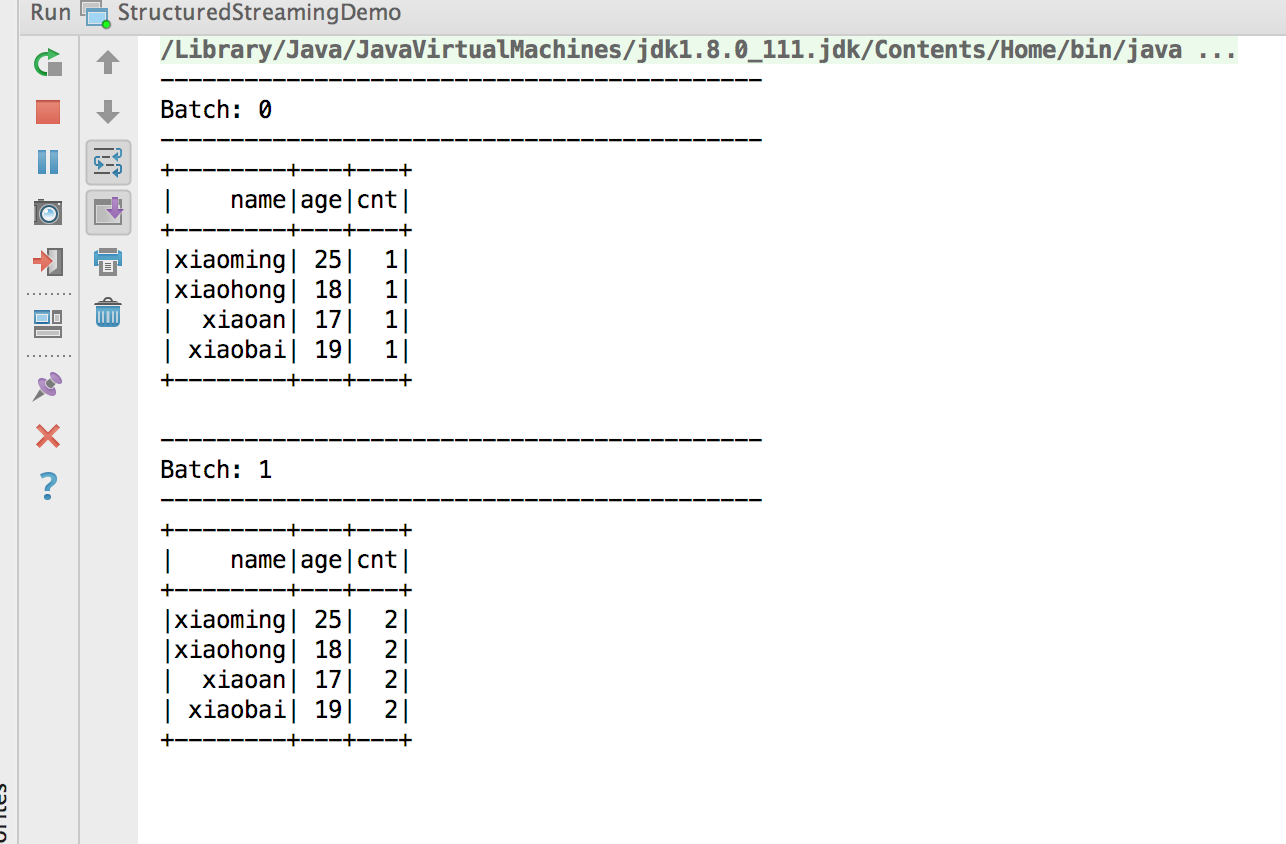
第一个batch是计算第一文件,
第二个batch是计算两个完整的文件的数量,然后cnt出现2次