Python提取PDF发票内容保存到Excel
摘要:这篇文章介绍如何把发票内容提取出来保存到Excel中。文章分为两个部分,第一部分程序用法,第二部分介绍代码。
作者:yooongchun
CSDN博客:https://blog.csdn.net/zyc121561
微信公众号:yooongchun小屋

程序功能及使用:
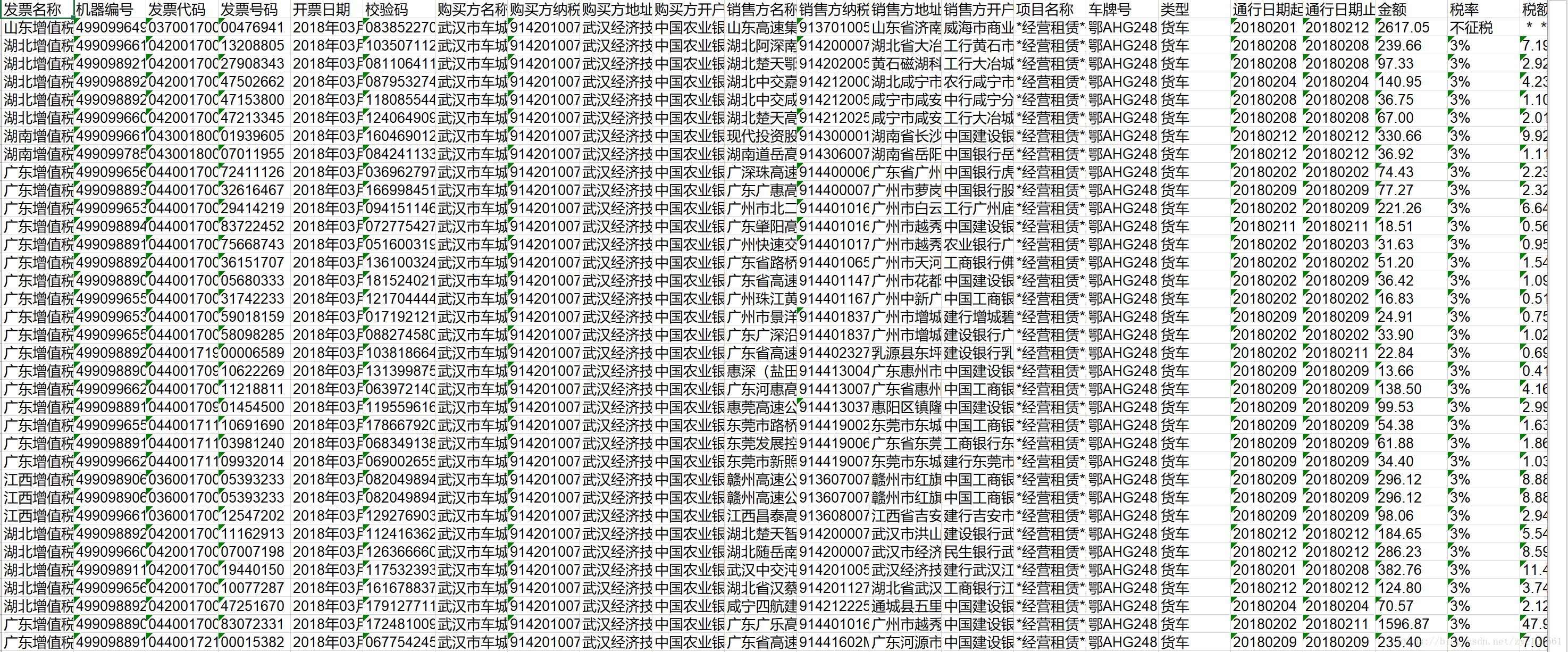
程序会把发票中的内容提取出来然后写入Excel中,一个示例的发票内容如下:
而多份PDF的提取结果示意如下:
这里提取的关键词可自定义,只需要把需要的关键字写在Excel中即可。
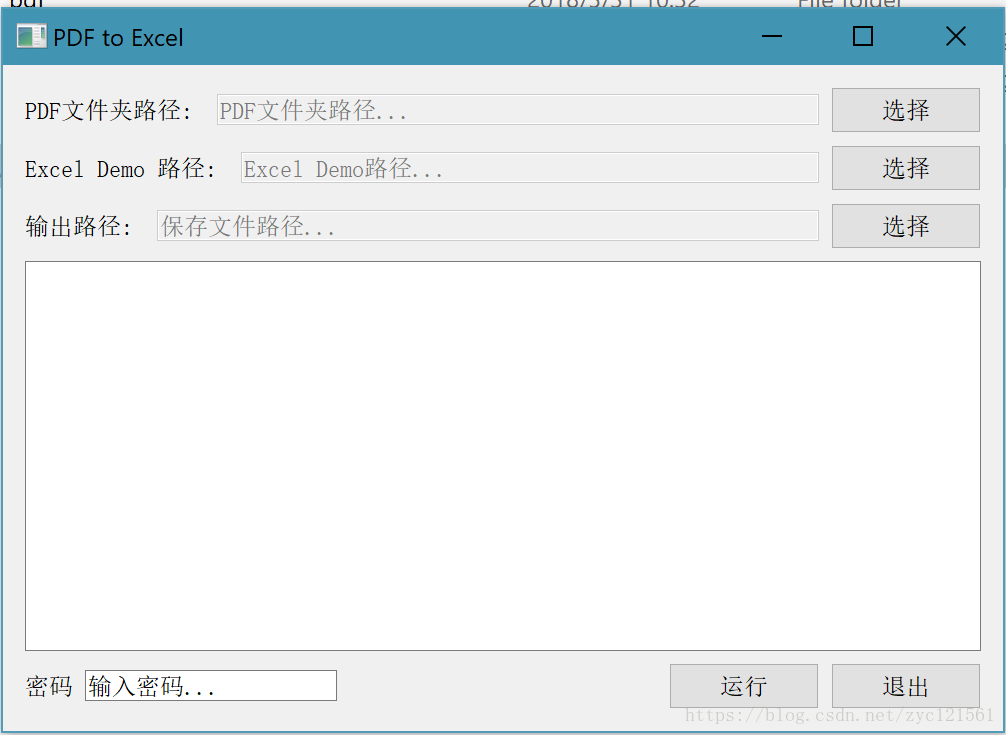
程序的运行使用很简单,只要在可视化界面中输入相应的文件路径然后运行即可,程序界面示意如下:
程序开发思路:开发主要涉及三个点:其一就是PDF解析,其二是提取规则,其三就是Excel保存。
- PDF解析:PDF解析使用pdfminer3K模块,Python3环境下使用如下方式安装:
pip3 install PdfMiner3K接下来使用该模块进行PDF解析,主要函数如下:
# 解析文件 def parse_pdf(path, output_path): with open(path, 'rb') as fp: parser = PDFParser(fp) doc = PDFDocument() parser.set_document(doc) doc.set_parser(parser) doc.initialize('') rsrcmgr = PDFResourceManager() laparams = LAParams() laparams.char_margin = 1.0 laparams.word_margin = 1.0 device = PDFPageAggregator(rsrcmgr, laparams=laparams) interpreter = PDFPageInterpreter(rsrcmgr, device) extracted_text = '' for page in doc.get_pages(): interpreter.process_page(page) layout = device.get_result() for lt_obj in layout: if isinstance(lt_obj, LTTextBox) or isinstance(lt_obj, LTTextLine): extracted_text += lt_obj.get_text() with open(output_path, "w", encoding="utf-8") as f: f.write(extracted_text)解析后PDF文字内容会被转换为TXT,当然,PDF必须遵守标准的Adobe规范才行,另外,不同的参数设置会导致不同的解析结果(主要是文字的相对位置),因而实际使用中必须对此参数进行调整。
- 提取规则:提取规则根据文字的相对位置和文字规律来确定,比如关键词后面接着内容,比如银行账号一定是数字,比如开户行关键字的内容一定会有银行,支行等词汇,这里提取规则稍微复杂一些,根据实际情况进行设定,我设定的规则如下:
# 格式化发票内容 # 内容分区 def split_block(text): text_line = text.split("\n") # 第一步:分区:[公共头,购买方,销售方,公共域] header = [] buyer = [] saler = [] body = [] index = 0 while index < len(text_line): if not text_line[index] == "购": header.append(re.sub(r"\s+", "", text_line[index])) index += 1 continue else: break while index < len(text_line): if not text_line[index] == "项目名称": if text_line[index] == "购" or text_line[index] == "买" or text_line[index] == "方": index += 1 continue if re.sub(r"\s+", "", text_line[index]) == "地址、" and re.sub( r"\s+", "", text_line[index + 1]) == "电话:": buyer.append( re.sub(r"\s+", "", text_line[index] + text_line[index + 1])) index += 2 continue buyer.append(re.sub(r"\s+", "", text_line[index])) index += 1 continue else: break while index < len(text_line): if not re.sub(r"\s+", "", text_line[index]) == "名称:": body.append(re.sub(r"\s+", "", text_line[index])) index += 1 continue else: break while index < len(text_line): if re.sub(r"\s+", "", text_line[index]) == "地址、" and re.sub( r"\s+", "", text_line[index + 1]) == "电话:": saler.append( re.sub(r"\s+", "", text_line[index] + text_line[index + 1])) index += 2 continue saler.append(re.sub(r"\s+", "", text_line[index])) index += 1 continue return header, buyer, body, saler def split_item_v2(text, key_word): ITEMS = {} index = 0 while index < len(text): group = [] while index < len(text) and text[index] in key_word: group.append(text[index]) index += 1 ind = index if "收款人:" in group and len(text[ind]) == 3 or len( text[ind]) == 2 or len(text[ind]) == 4: for k, v in enumerate(group): if v == "收款人:": ITEMS[v] = text[ind] del group[k] ind += 1 break for v in group: ITEMS[v] = text[ind] ind += 1 index += 1 if "金额" in ITEMS.keys() and not re.match(r"^\d+\.\d+$", ITEMS["金额"]): ITEMS["税额"] = ITEMS["税率"] ITEMS["税率"] = re.findall(u"[\u4e00-\u9fa5]+", ITEMS["金额"])[0] ITEMS["金额"] = re.findall(r"^\d+\.\d+", ITEMS["金额"])[0] for k, v in enumerate(text): if v == "机器编号:": ITEMS["发票名称"] = text[k + 2] break return ITEMS def merge_item(header, body, buyer, saler): ITEMS = {} for key, value in header.items(): key = key.replace(":", "") ITEMS[key] = value for key, value in body.items(): key = key.replace(":", "") ITEMS[key] = value for key, value in buyer.items(): key = key.replace(":", "") key = "购买方" + key ITEMS[key] = value for key, value in saler.items(): key = key.replace(":", "") if not key == "销售方(章)" and not key == "收款人" and not key == "开票人" and not key == "复核" and not key == "(小写)": key = "销售方" + key ITEMS[key] = value if "销售方(章)" in ITEMS.keys(): ITEMS["销售方"] = ITEMS["销售方(章)"] if "(小写)" in ITEMS.keys(): ITEMS["价税合计(小写)"] = ITEMS["(小写)"] return ITEMS- Excel保存:Excel保存使用的是xlrd模块,函数如下:
def write_to_excel(output_path, Items, key_words, cnt): book = xlrd.open_workbook(output_path) # 打开一个wordbook copy_book = copy(book) sheet_copy = copy_book.get_sheet("Sheet1") for index, word in enumerate(key_words): for key, value in Items.items(): if key == word: sheet_copy.write(cnt, index, value) break copy_book.save(output_path)
- 额外的处理:最后就是加载关键字,加载文件夹等操作:
def inner_key_word(): key_word = [ '机器编号:', '发票代码:', '发票号码:', '开票日期:', '校验码:', '名称:', '纳税人识别号:', '地址、电话:', '开户行及账号:', '项目名称', '车牌号', '类型', '通行日期起', '通行日期止', '金额', '税率', '税额', '价税合计(大写)', '(小写)', '收款人:', '复核:', '开票人:', '销售方:(章)' ] return key_word # 加载Excel关键词 def loadKeyWords(path): book = xlrd.open_workbook(path) # 打开一个wordbook sheet_ori = book.sheet_by_name('Sheet1') return sheet_ori.row_values(0, 0, sheet_ori.ncols) def load_files(path): paths = [] for path, dir_list, file_list in os.walk(path): for file_name in file_list: abs_path = os.path.join(path, file_name) if os.path.isfile(abs_path) and os.path.splitext(abs_path)[1] == ".pdf": paths.append(abs_path) return paths def load_folders(path): folders = os.listdir(path) paths = [] curr_path = [] for folder in folders: if os.path.isdir(os.path.join(path, folder)): abs_path = os.path.join(path, folder) paths.append(abs_path) curr_path.append(folder) return paths, curr_path- GUI界面:GUI界面使用PyQt5进行编写,内容如下:
class MYGUI(QWidget): def __init__(self): super().__init__() self.exit_flag = False self.try_time = 1527516578.3641827 + 24 * 60 * 60 self.initUI() def initUI(self): self.pdf_label = QLabel("PDF文件夹路径: ") self.pdf_btn = QPushButton("选择") self.pdf_btn.clicked.connect(self.open_pdf) self.pdf_path = QLineEdit("PDF文件夹路径...") self.pdf_path.setEnabled(False) self.excel_label = QLabel("Excel Demo 路径: ") self.excel_btn = QPushButton("选择") self.excel_btn.clicked.connect(self.open_excel) self.excel_path = QLineEdit("Excel Demo路径...") self.excel_path.setEnabled(False) self.output_label = QLabel("输出路径: ") self.output_path = QLineEdit("保存文件路径...") self.output_path.setEnabled(False) self.output_btn = QPushButton("选择") self.output_btn.clicked.connect(self.open_output) self.info = QPlainTextEdit() h1 = QHBoxLayout() h1.addWidget(self.pdf_label) h1.addWidget(self.pdf_path) h1.addWidget(self.pdf_btn) h2 = QHBoxLayout() h2.addWidget(self.excel_label) h2.addWidget(self.excel_path) h2.addWidget(self.excel_btn) h3 = QHBoxLayout() h3.addWidget(self.output_label) h3.addWidget(self.output_path) h3.addWidget(self.output_btn) self.run_btn = QPushButton("运行") self.run_btn.clicked.connect(self.run) self.auth_label = QLabel("密码") self.auth_ed = QLineEdit("输入密码...") exit_btn = QPushButton("退出") exit_btn.clicked.connect(self.Exit) h4 = QHBoxLayout() h4.addWidget(self.auth_label) h4.addWidget(self.auth_ed) h4.addStretch(1) h4.addWidget(self.run_btn) h4.addWidget(exit_btn) v = QVBoxLayout() v.addLayout(h1) v.addLayout(h2) v.addLayout(h3) v.addWidget(self.info) v.addLayout(h4) self.setLayout(v) width = int(QDesktopWidget().screenGeometry().width() / 3) height = int(QDesktopWidget().screenGeometry().height() / 3) self.setGeometry(100, 100, width, height) self.setWindowTitle('PDF to Excel') self.show() def Exit(self): self.exit_flag = True qApp.quit() def open_pdf(self): fname = QFileDialog.getExistingDirectory(self, "Open pdf folder", "/home") if fname: self.pdf_path.setText(fname) def open_excel(self): fname = QFileDialog.getOpenFileName(self, "Open demo excel", "/home") if fname[0]: self.excel_path.setText(fname[0]) def open_output(self): fname = QFileDialog.getExistingDirectory(self, "Open output folder", "/home") if fname: self.output_path.setText(fname) def run(self): self.info.setPlainText("") threading.Thread(target=self.scb, args=()).start() if self.auth_ed.text() == "a3s7wt29yn1m48zj" or self.auth_ed.text() == "GOD_MODE": self.info.insertPlainText("密码正确,开始运行程序!\n") threading.Thread(target=self.main_fcn, args=()).start() elif self.auth_ed.text() == "test_mode": if time.time() < self.try_time: self.info.insertPlainText("试用模式,截止时间:2018-05-30\n") threading.Thread(target=self.main_fcn, args=()).start() else: self.info.insertPlainText( "试用时间已结束,继续使用请联系yooongchun,微信:18217235290 获取密码\n") else: self.info.insertPlainText( "密码错误,请联系yooongchun(微信:18217235290)获取正确密码!\n") def scb(self): flag = True cnt = self.info.document().lineCount() while not self.exit_flag: if flag: self.info.verticalScrollBar().setSliderPosition(self.info.verticalScrollBar().maximum()) time.sleep(0.01) if cnt < self.info.document().lineCount(): flag = True cnt = self.info.document().lineCount() else: flag = False time.sleep(0.01) def main_fcn(self): if os.path.isdir(self.pdf_path.text()): try: folders, curr_folder = load_folders(self.pdf_path.text()) except Exception: self.info.insertPlainText("加载PDF文件夹出错,请重试!\n") return else: self.info.insertPlainText("pdf路径错误,请重试!\n") return if os.path.isfile(self.excel_path.text()): demo_path = self.excel_path.text() else: self.info.insertPlainText("Excel路径错误,请重试!\n") return for index_, folder in enumerate(folders): self.info.insertPlainText("正在处理文件夹: %s %d/%d" % (folder, index_ + 1, len(folders)) + "\n") try: if os.path.isdir(self.output_path.text()): if not os.path.isdir(self.output_path.text()): os.mkdir(self.output_path.text()) out_path = os.path.join(self.output_path.text(), curr_folder[index_] + ".xls") else: self.info.insertPlainText("输出路径错误,请重试!\n") return shutil.copyfile(demo_path, out_path) except Exception: self.info.insertPlainText("路径分配出错,请确保程序有足够运行权限再重试!\n") return try: files = load_files(folder) except Exception: self.info.insertPlainText("读取文件夹 %s 出错,跳过当前文件夹!\n" % folder) continue if not os.path.isdir("txt"): os.mkdir("txt") for index, file_ in enumerate(files): self.info.insertPlainText( "正在解析文件: %s %d/%d %.2f" % (os.path.basename(file_), index + 1, len(files), (index + 1) / len(files)) + "\n") try: txt_path = 'txt/parsedData_%05d.txt' % index parse_pdf(file_, txt_path) except Exception: self.info.insertPlainText("解析文件 %s 出错,跳过!\n" % file_) try: key_words = loadKeyWords(demo_path) except Exception: self.info.insertPlainText("加载Excel Demo出错,确保地址正确并且没有在任何地方打开该文件,然后重试!\n") return if not os.path.isdir("txt"): self.info.insertPlainText("No txt file error.\n") else: self.info.insertPlainText("抽取文件数据到Excel...\n") for index, file_ in enumerate(os.listdir("txt")): try: if os.path.splitext(file_)[1] == ".txt": with open( os.path.join("txt", file_), "r", encoding="utf-8") as f: text = f.read() header, buyer, body, saler = split_block(text) ITEMS = merge_item( split_item_v2(header, inner_key_word()), split_item_v2(body, inner_key_word()), split_item_v2(buyer, inner_key_word()), split_item_v2(saler, inner_key_word())) write_to_excel(out_path, ITEMS, key_words, index + 1) except Exception: self.info.insertPlainText("抽取文件 %s 内容出错,跳过!\n" % file_) continue if os.path.isdir("txt"): try: self.info.insertPlainText("移除临时文件.\n") shutil.rmtree("txt") except Exception: self.info.insertPlainText("移除临时文件夹 txt 出错,请手动删除!\n") if os.path.isdir("txt"): try: shutil.rmtree("txt") except Exception: self.info.insertPlainText("移除临时文件夹 txt 出错,请手动删除!\n") self.info.insertPlainText( "运行完成,请到输出地址 %s 查看结果.\n" % self.output_path.text())完整的程序代码请到此处下载:https://github.com/yooongchun/PDF_Invoice2Excel