KMP及拓展KMP算法
KMP算法是一种线性时间复杂度的字符串匹配算法,它是对BF(Brute-Force,最基本的字符串匹配算法)的改进。对于给定的原始串S和模式串T,需要从字符串S中找到字符串T出现的位置的索引。KMP算法由D.E.Knuth与V.R.Pratt和J.H.Morris同时发现,因此人们称它为Knuth--Morris--Pratt算法,简称KMP算法。在讲解KMP算法之前,有必要对它的前身--BF算法有所了解,因此首先将介绍最朴素的BF算法。
一:BF算法简介

如上图所示,原始串S=abcabcabdabba,模式串为abcabd。(下标从0开始)从s[0]开始依次比较S[i] 和T[i]是否相等,直到T[5]时发现不相等,这时候说明发生了失配,在BF算法中,发生失配时,T必须回溯到最开始,S下标+1,然后继续匹配,如下图所示:

这次立即发生了失配,所以继续回溯,直到S开始下表增加到3,匹配成功。
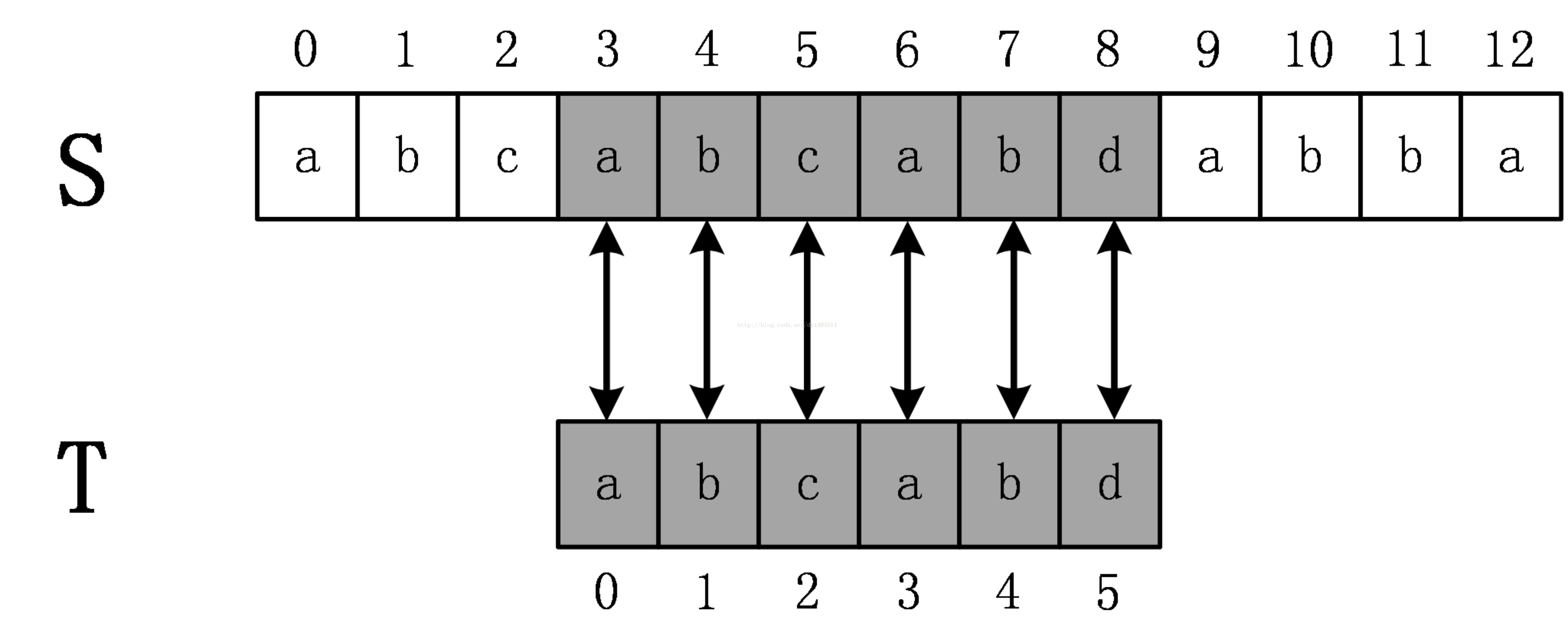
容易得到,BF算法的时间复杂度是O(n*m)的,其中n为原始串的长度,m为模式串的长度。BF的代码实现也非常简单直观,这里不给出,因为下一个介绍的KMP算法是BF算法的改进,其时间复杂度为线性O(n+m)。
二:KMP算法简介
前面提到了朴素匹配算法,它的优点就是简单明了,缺点当然就是时间消耗很大,既然知道了BF算法的不足,那么就要对症下药,设计一种时间消耗小的字符串匹配算法。
KMP算法就是其中一个经典的例子,它的主要思想就是:
在匹配匹配过程中发生失配时,并不简单的从原始串下一个字符开始重新匹配,而是根据一些匹配过程中得到的信息跳过不必要的匹配,从而达到一个较高的匹配效率。
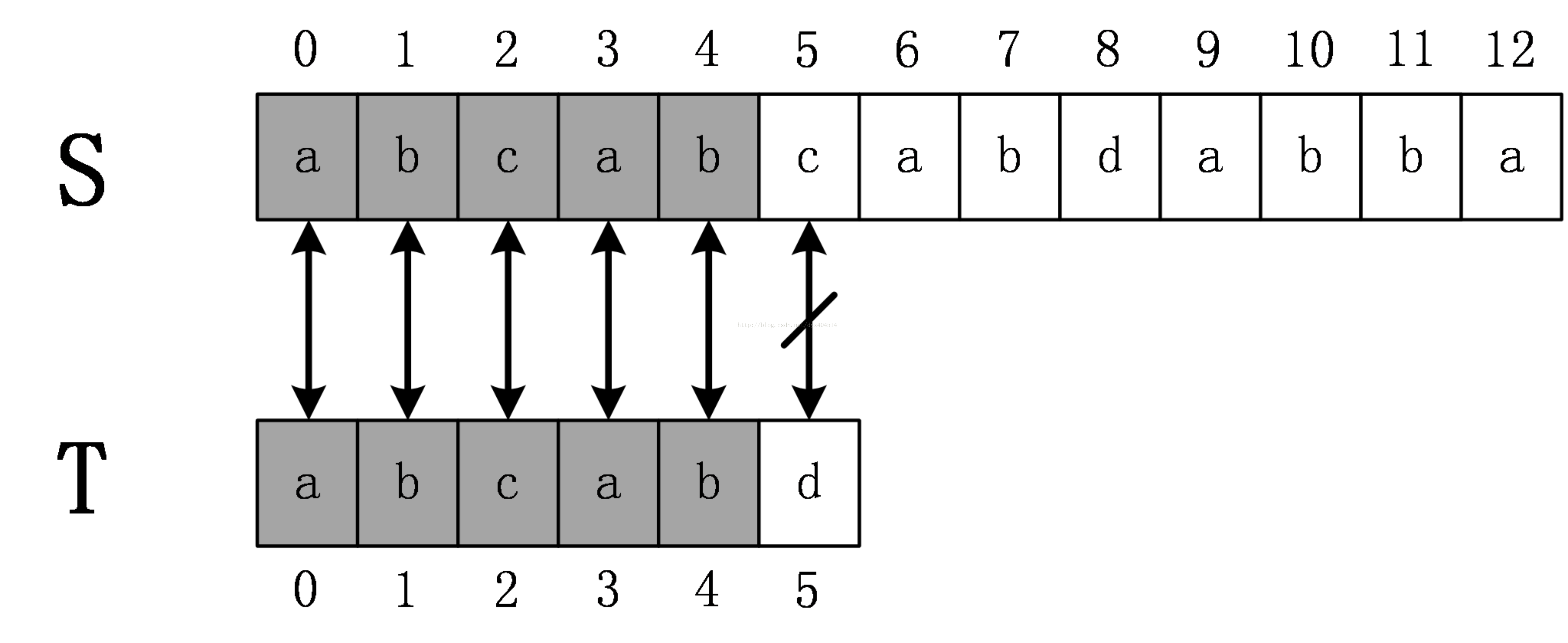
还是前面的例子,原始串S=abcabcabdabba,模式串为abcabd。当第一次匹配到T[5]!=S[5]时,KMP算法并不将T的下表回溯到0,而是回溯到2,S下标继续从S[5]开始匹配,直到匹配完成。
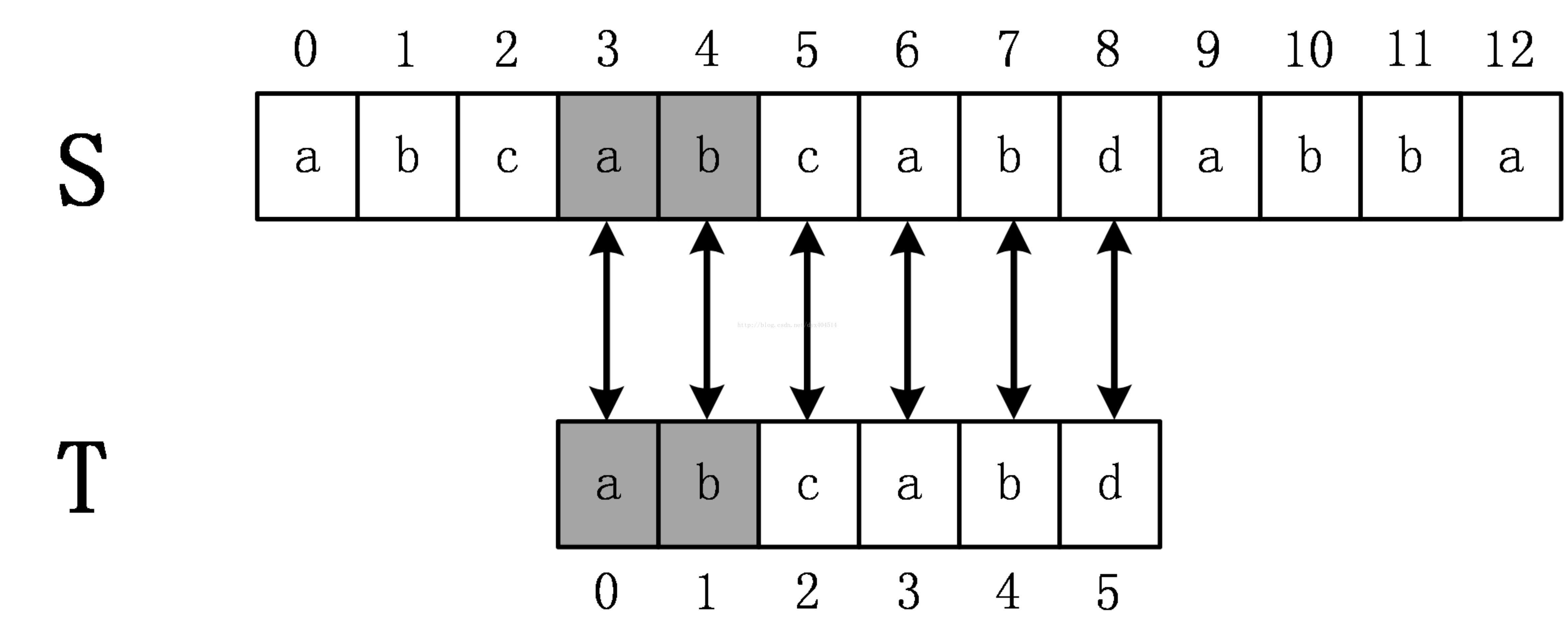
那么为什么KMP算法会知道将T的下标回溯到2呢?前面提到,KMP算法在匹配过程中将维护一些信息来帮助跳过不必要的检测,这个信息就是KMP算法的重点 --next数组。(也叫fail数组,前缀数组)。
1:next数组
(1)next数组的定义:
设模式串T[0,m-1],(长度为m),那么next[i]表示既是是串T[0,i-1]的后缀又是串T[0,i-1]的前缀的串最长长度(不妨叫做前后缀),注意这里的前缀和后缀不包括串T[0,i-1]本身。
如上面的例子,T=abcabd,那么next[5]表示既是abcab的前缀又是abcab的后缀的串的最长长度,显然应该是2,即串ab。注意到前面的例子中,当发生失配时T回溯到下表2,和next[5]数组是一致的,这当然不是个巧合,事实上,KMP算法就是通过next数组来计算发生失配时模式串应该回溯到的位置。
(2)next数组的计算:
这里介绍一下next数组的计算方法。
设模式串T[0,m-1],长度为m,由next数组的定义,可知next[0]=next[1]=0,(因为这里的串的后缀,前缀不包括该串本身)。
接下来,假设我们从左到右依次计算next数组,在某一时刻,已经得到了next[0]~next[i],现在要计算next[i+1],设j=next[i],由于知道了next[i],所以我们知道T[0,j-1]=T[i-j,i-1],现在比较T[j]和T[i],如果相等,由next数组的定义,可以直接得出next[i+1]=j+1。
如果不相等,那么我们知道next[i+1]<j+1,所以要将j减小到一个合适的位置po,使得po满足:
1)T[0,po-1]=T[i-po,i-1]。
2)T[po]=T[i]。
3)po是满足条件(1),(2)的最大值。
4)0<=po<j(显然成立)。
如何求得这个po值呢?事实上,并不能直接求出po值,只能一步一步接近这个po,寻找当前位置j的下一个可能位置。如果只要满足条件(1),那么j就是一个,那么下一个满足条件(1)的位置是什么呢?,由next数组的定义,容易得到是next[j]=k,这时候只要判断一下T[k]是否等于T[i],即可判断是否满足条件(2),如果还不相等,继续减小到next[k]再判断,直到找到一个位置P,使得P同时满足条件(1)和条件(2)。我们可以得到P一定是满足条件(1),(2)的最大值,因为如果存在一个位置x使得满足条件(1),(2),(4)并且x>po,那么在回溯到P之前就能找到位置x,否则和next数组的定义不符。在得到位置po之后,容易得到next[i+1]=po+1。那么next[i+1]就计算完毕,由数学归纳法,可知我们可以求的所有的next[i]。(0<=i<m)
注意:在回溯过程中可能有一种情况,就是找不到合适的po满足上述4个条件,这说明T[0,i]的最长前后缀串长度为0,直接将next[i+1]赋值为0,即可。
void getnext(char *b) //b为子串
{
int i=0,j=-1;
int len=strlen(b);
nex[0]=-1;
while(i<len)
{
if(j==-1||b[i]==b[j])
{
nex[++i]=++j;
}
else
j=nex[j];
}
}以上是计算next数组的代码实现。是不是非常简短呢。
2.KMP匹配过程
有了next数组,我们就可以通过next数组跳过不必要的检测,加快字符串匹配的速度了。那么为什么通过next数组可以保证匹配不会漏掉可匹配的位置呢?
首先,假设发生失配时T的下标在i,那么表示T[0,i-1]与原始串S[l,r]匹配,设next[i]=j,根据KMP算法,可以知道要将T回溯到下标j再继续进行匹配,根据next[i]的定义,可以得到T[0,j-1]和S[r-j+1,r]匹配,同时可知对于任何j<y<i,T[0,y]不和S[r-y,r]匹配,这样就可以保证匹配过程中不会漏掉可匹配的位置。
同next数组的计算,在一般情况下,可能回溯到next[i]后再次发生失配,这时只要继续回溯到next[j],如果不行再继续回溯,最后回溯到next[0],如果还不匹配,这时说明原始串的当前位置和T的开始位置不同,只要将原始串的当前位置+1,继续匹配即可。
下面给出KMP算法匹配过程的代码:
int kmp(char *a,char *b) //return值为子串开始的位置
{
int i=0,j=0;
getnext(b);
int lena=strlen(a); //a为主串
int lenb=strlen(b); //b为子串
while(i<lena)
{
if(j==-1||a[i]==b[j])
i++,j++;
else
j=nex[j];
if(j==lenb)
return i-j+1;
}
return -1; //匹配不成功
}3.时间复杂度分析
前面说到,KMP算法的时间复杂度是线性的,但这从代码中并不容易得到,很多读者可能会想,如果每次匹配都要回溯很多次,是不是会使算法的时间复杂度退化到非线性呢?
其实不然,我们对代码中的几个变量进行讨论,首先是kmp函数,显然决定kmp函数时间复杂度的变量只有两个,i和j,其中i只增加了len次,是O(len)的,下面讨论j,因为由next数组的定义我们知道next[j]<j,所以在回溯的时候j至少减去了1,并且j保证是个非负数。另外,由代码可知j最多增加了len次,且每次只增加了1。简单来说,j每次增加只能增加1,每次减小至少减去1,并且保证j是个非负数,那么可知j减小的次数一定不能超过增加的次数。所以,回溯的次数不会超过len。综上所述,kmp函数的时间复杂度为O(len)。同理,对于计算next数组同样用类似的方法证明它的时间复杂度为O(len),这里不再赘述。对于长度为n的原始串S,和长度为m的模式串T,KMP算法的时间复杂度为O(n+m)。
三:拓展KMP算法简介
拓展kmp是对KMP算法的扩展,它解决如下问题:
定义母串S,和子串T,设S的长度为n,T的长度为m,求T与S的每一个后缀的最长公共前缀,也就是说,设extend数组,extend[i]表示T与S[i,n-1]的最长公共前缀,要求出所有extend[i](0<=i<n)。
注意到,如果有一个位置extend[i]=m,则表示T在S中出现,而且是在位置i出现,这就是标准的KMP问题,所以说拓展kmp是对KMP算法的扩展,所以一般将它称为扩展KMP算法。
下面举一个例子,S=”aaaabaa”,T=”aaaaa”,首先,计算extend[0]时,需要进行5次匹配,直到发生失配。
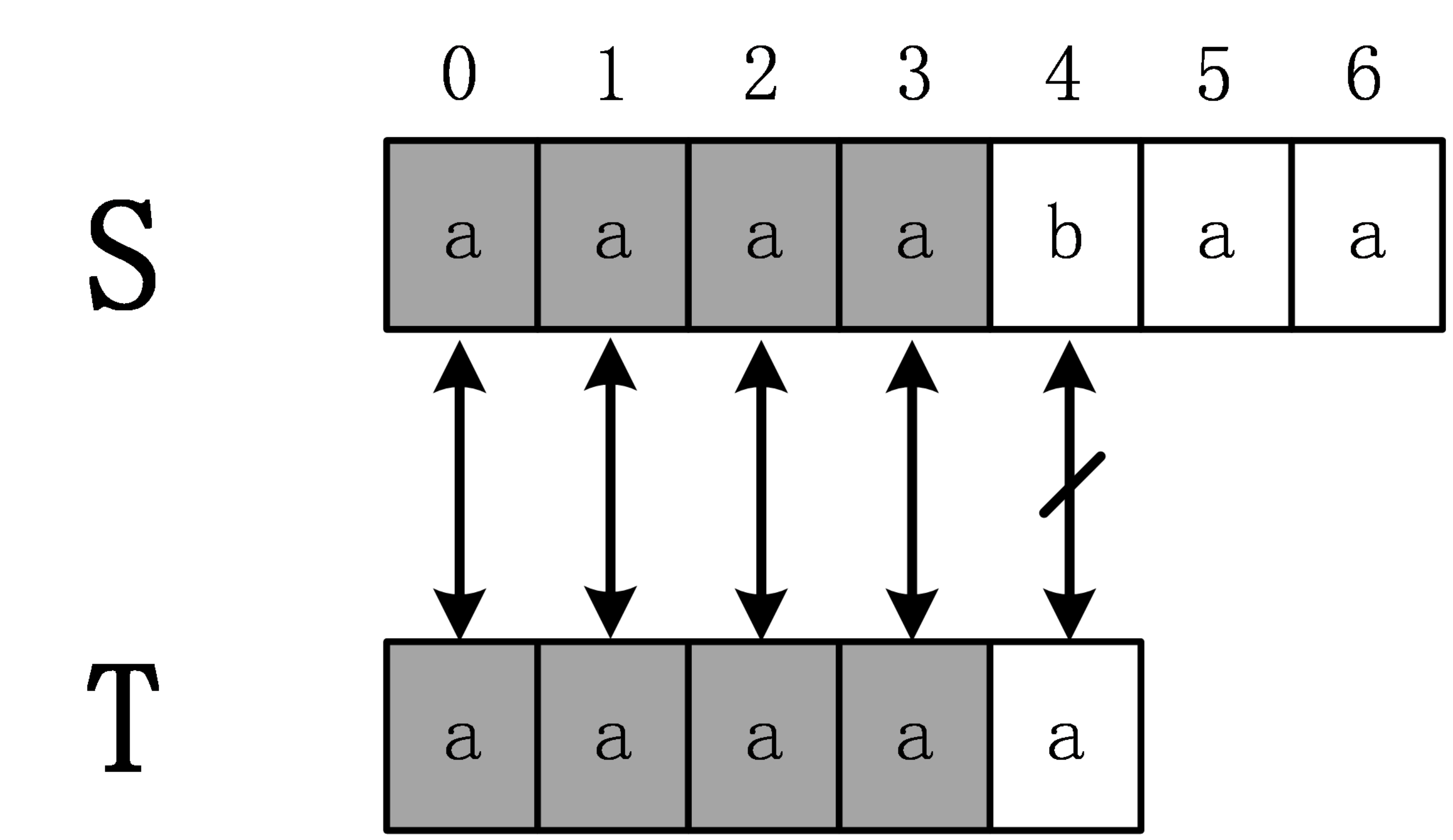
从而得知extend[0]=4,下面计算extend[1],在计算extend[1]时,是否还需要像计算extend[0]时从头开始匹配呢?答案是否定的,因为通过计算extend[0]=4,从而可以得出S[0,3]=T[0,3],进一步可以得到 S[1,3]=T[1,3],计算extend[1]时,事实上是从S[1]开始匹配,设辅助数组next[i]表示T[i,m-1]和T的最长公共前缀长度。在这个例子中,next[1]=4,即T[0,3]=T[1,4],进一步得到T[1,3]=T[0,2],所以S[1,3]=T[0,2],所以在计算extend[1]时,通过extend[0]的计算,已经知道S[1,3]=T[0,2],所以前面3个字符已经不需要匹配,直接匹配S[4]和T[3]即可,这时一次就发生失配,所以extend[1]=3。这个例子很有代表性,有兴趣的读者可以继续计算完剩下的extend数组。
1. 拓展kmp算法一般步骤
通过上面的例子,事实上已经体现了拓展kmp算法的思想,下面来描述拓展kmp算法的一般步骤。
首先我们从左到右依次计算extend数组,在某一时刻,设extend[0...k]已经计算完毕,并且之前匹配过程中所达到的最远位置为P,所谓最远位置,严格来说就是i+extend[i]-1的最大值(0<=i<=k),并且设取这个最大值的位置为po,如在上一个例子中,计算extend[1]时,P=3,po=0。

现在要计算extend[k+1],根据extend数组的定义,可以推断出S[po,P]=T[0,P-po],从而得到 S[k+1,P]=T[k-po+1,P-po],令len=next[k-po+1],(回忆下next数组的定义),分两种情况讨论:
第一种情况:k+len<P
如下图所示:
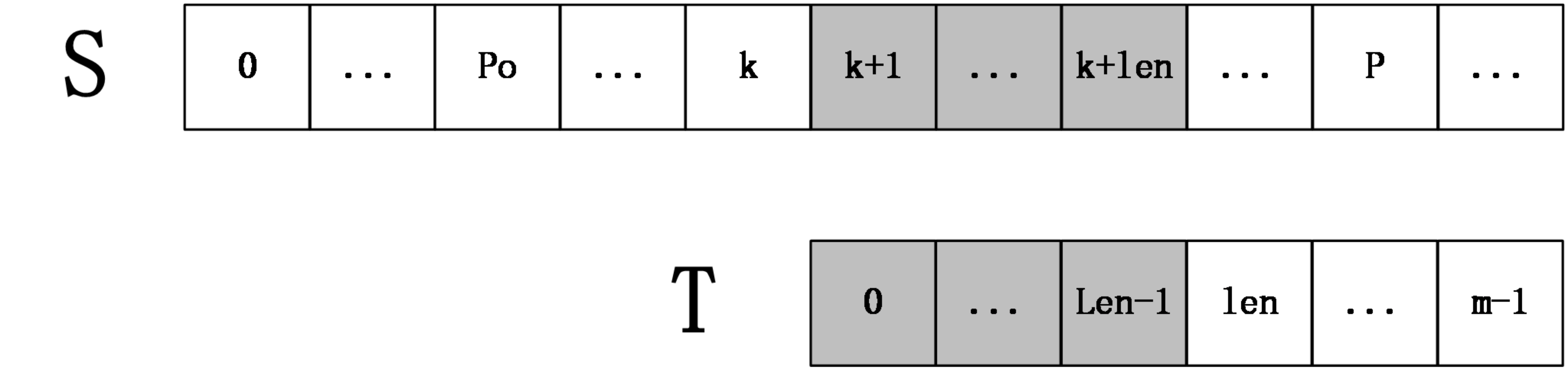
上图中,S[k+1,k+len]=T[0,len-1],然后S[k+len+1]一定不等于T[len],因为如果它们相等,则有S[k+1,k+len+1]=T[k+po+1,k+po+len+1]=T[0,len],那么next[k+po+1]=len+1,这和next数组的定义不符(next[i]表示T[i,m-1]和T的最长公共前缀长度),所以在这种情况下,不用进行任何匹配,就知道extend[k+1]=len。
第二种情况: k+len>=P(其实稍加分析可以发现k+len必定小于等于P)
如下图:
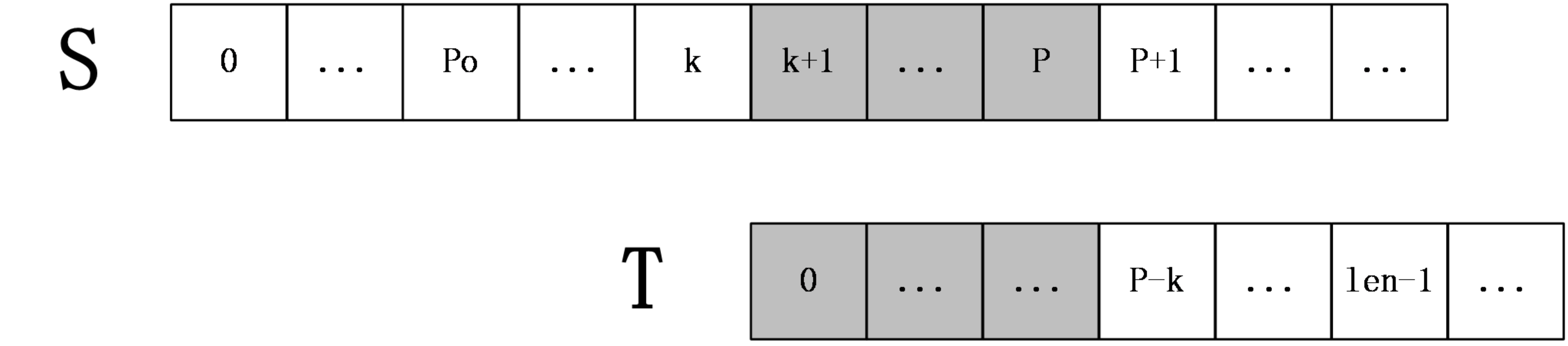
上图中,S[p+1]之后的字符都是未知的,也就是还未进行过匹配的字符串,所以在这种情况下,就要从S[P+1]和T[P-k+1]开始一一匹配,直到发生失配为止,当匹配完成后,如果得到的extend[k+1]+(k+1)大于P则要更新未知P和po。
至此,拓展kmp算法的过程已经描述完成,细心地读者可能会发现,next数组是如何计算还没有进行说明,事实上,计算next数组的过程和计算extend[i]的过程完全一样,将它看成是以T为母串,T为字串的特殊的拓展kmp算法匹配就可以了,计算过程中的next数组全是已经计算过的,所以按照上述介绍的算法计算next数组即可,这里不再赘述。
2. 时间复杂度分析
下面来分析一下算法的时间复杂度,通过上面的算法介绍可以知道,对于第一种情况,无需做任何匹配即可计算出extend[i],对于第二种情况,都是从未被匹配的位置开始匹配,匹配过的位置不再匹配,也就是说对于母串的每一个位置,都只匹配了一次,所以算法总体时间复杂度是O(n)的,同时为了计算辅助数组next[i]需要先对字串T进行一次拓展kmp算法处理,所以拓展kmp算法的总体复杂度为O(n+m)的。其中n为母串的长度,m为子串的长度。
下面是拓展kmp算法的关键部分代码实现
void getnext(char *b)
{
int len=strlen(b);
nex[0]=len;
int pos,r; //记录匹配成功的字符串的最远位置r以及对应的起始位置pos
for(int i=1,j=-1;i<len;i++,j--)
{
if(j<0||i+nex[i-pos]>=r)
{
if(j<0)
{
r=i,j=0;
}
while(r<len&&b[r]==b[j])
{
r++,j++;
}
nex[i]=j;
pos=i;
}
else
nex[i]=nex[i-pos];
}
}
void getextend(char *a,char *b)
{
getnext(b);
int pos,r;
int lena=strlen(a);
int lenb=strlen(b);
for(int i=0,j=-1;i<lena;i++,j--)
{
if(j<0||i+nex[i-pos]>=r)
{
if(j<0)
{
r=i,j=0;
}
while(r<lena&&j<lenb&&a[r]==b[j])
{
r++,j++;
}
extend[i]=j;
pos=i;
}
else
extend[i]=extend[i-pos];
}
}