在项目中,碰到需要按一定规则来生成数据库ID的主键,这样以后数据量达到一定规模是,可以很方便的通过主键id来实现分库分表,查了一些资料,将一些常用ID生成策略的方法及优缺点了解了一下。
1、数据库自增主键
优点:简单;唯一;递增;增幅固定
缺点:写性能决定每秒生成数量上限,扩展差;分布式数据库,主节点挂掉,备节点上时可能有问题(主节点写入成功,日志未同步到备节点,导致id重复)
备注:可有一个写库变成多个库同时写,如1、2、3三个库同时写,初始id分别为1、2、3,自增幅度都为3。这种方式可保证id不重复。但导致id不是绝对递增,而是整体趋势上递增;其次是写入的压力仍然很大,mysql容易成为性能瓶颈。
2、数据库批量生成id
优点:效率高;降低数据库压力
缺点:需考虑安全性问题,防止取到重复id;如果业务需求是每次只生成一个id,性能有问题
备注:利用数据库,初始化一行数据,初始值为1,取10个id,就给该值加10,调用端取返回id值的前10个数值。以上即为批量生成id思路。
3、UUID
优点:本地生成;效率高
缺点:UUID字符串过长,且无实际意义;无法保证递增趋势;建立的索引查询效率低
4、当前时间毫秒与微秒
优点:本地生成;延时低;索引性能高
缺点:1秒内请求过1000后id肯定重复,微秒同理
5、zookeeper生成id
利用zookeeper增加版本号的方式是其中一种。建立节点,每次使节点版本加1。
优点:利用zk集群解决单点问题
缺点:性能不高;id有上限,提供32位id;需要zk服务
参考代码:https://blog.csdn.net/gongzi2311/article/details/58144091
6、snowflake算法
twitter开源分布式生成id算法。
优点:基本解决了所有问题
缺点:每个节点时间可能不同,生成id是整体趋势递增的
参考代码:https://blog.csdn.net/gongzi2311/article/details/58189306
ID的生成
经过整体评估,每秒的并发量、后期可能扩展的服务器数量、数据库数量、供应商增长速度等,最终在snowflake算法的基础上做了一些修改,结构如下:
---------------------------------------------------------
| 1 | 39 | 1 | 7 | 8 | 8 |
---------------------------------------------------------
| A | B | C | D | E | F |
共64位
A:符号位(0);
B:时间差(当前时间与固定时间的差值)
2^39 = 549755813888
每年毫秒数 = 31536000000
使用年限 = 2^39 / 1000 * 60 * 60 *24 *365 = 17年
C:dataCenter(数据中心)
支持2个数据中心
D:workId(服务器)
最多可扩展到128台服务器
E:序列
每毫秒256个序列
F:供应商id
最多支持256个供应商
关于ID生成的具体算法,可以参考snowflake,几乎完全一致,只是各位数定义的长度不一样。
另外,ID生成的效率是比较高的,在单线程的条件下,生成10000个ID,用时42ms。
package com.cw.id;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class SnowflakeIdWorker {
// ==============================Fields===========================================
/** 开始时间截 (2017-11-01) */
public static final long twepoch = 1509465600000L;
public static final long workerIdBits = 7L;
public static final long datacenterIdBits = 1L;
public static final long maxWorkerId = -1L ^ (-1L << workerIdBits);
public static final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
public static final long sequenceBits = 8L;
public static final long placeHoldBits = 8L;
public static final long sequenceIdShift = placeHoldBits;
public static final long workerIdShift = sequenceBits + sequenceIdShift;
public static final long dataCenterIdShift = workerIdShift + workerIdBits;
public static final long timestampShift = dataCenterIdShift + datacenterIdBits;
public static final long sequenceMask = -1L ^ (-1L << sequenceBits);
private long workerId;
private long datacenterId;
private long sequence = 0L;
private long lastTimestamp = -1L;
//==============================Constructors=====================================
public SnowflakeIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
// ==============================Methods==========================================
/**
* 获得下一个ID (该方法是线程安全的)
* @return SnowflakeId
*/
public synchronized long nextId(long placeHolder) {
long timestamp = currentMillis();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampShift) //
| (datacenterId << dataCenterIdShift) //
| (workerId << workerIdShift) //
| (sequence << sequenceIdShift)
| (0XFF & placeHolder);
}
protected long tilNextMillis(long lastTimestamp) {
long timestamp = currentMillis();
while (timestamp <= lastTimestamp) {
timestamp = currentMillis();
}
return timestamp;
}
/**
* 返回以毫秒为单位的当前时间
* @return 当前时间(毫秒)
*/
protected long currentMillis() {
return System.currentTimeMillis();
}
//==============================Test=============================================
/** 测试 */
public static void main(String[] args) {
SnowflakeIdWorker idWorker = new SnowflakeIdWorker(1, 0);
long id = idWorker.nextId(9);
log.info("id {}, binary {}", id, Long.toBinaryString(id));
}
}
在低位的末8位,使用了0XFF & placeHolder,是为了保留placeHolder的低8位,相当于1111 1111 & placeHolder,如果placeHolder超过了8位,高于8位的数据将会舍弃,因为F位,我们只留了8位,为了避免placeHolder大于256而做的一种处理,当然 也可以像workId < maxWorkerId 一样,增加强制校验 placeHolder < 256。
ID的还原
生成id:377433879335731209
对应二进制:10100111100111010100001110100010000 0 0000001 00000000 00001001
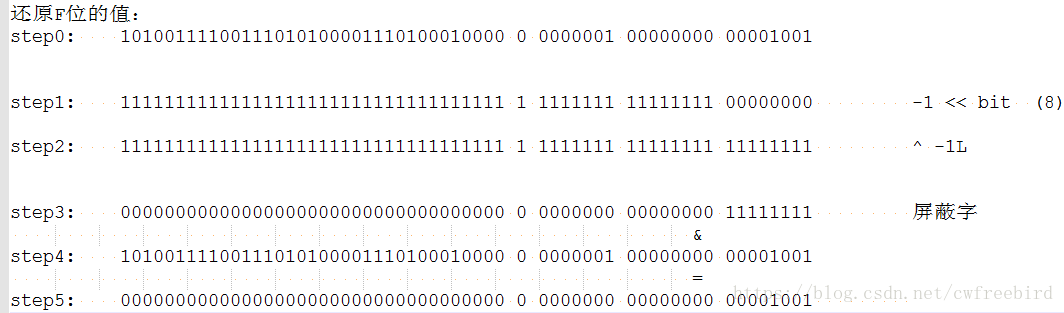
假设还原最低位(F位的值)
- step1 ~ step3 主要是为了获取F位屏蔽字 -1L ^ (-1L << 8) ,F位的长度是8
- step4 ~ step5 将上面得到的屏蔽字与待还原数值进行“与”操作,即得到了F位的值,也就是从id中还原了F位
用同样的方法,就可以还原任意位置的值,需要注意的是,使用该方法,需要将待还原值,移到最低位(最右边),因为F位正好是最低位,所以不需要移动。
假设还原最高位(B位的值,A位是固定符号位,不需要还原)

- step0-1 还原始二进制进行无符号右移,一直移到最低位,需求移动C + D + E + F的位数,即 >>> 24
- step1 ~ step3 获取B位的屏蔽字 -1L ^ (-1L << 39) , B位的长度为39位
- step4 ~ step5 将上面得到的屏蔽字与待还原数值进行“与”操作,即得到了B位的值,也就是从id中还原了B位(时间差)的值,如有需要,再加上固定的时间,即可得到生成id时的具体时间
其实,通过step0-1进行的无符号位移操作后,就已经可以得到B位的值了,无需要再与屏蔽字进行“与”操作,因为通过右移运算后,剩下的只有B位的值了,但是如果是要还原中间某位(C、D、E)就必须要借助于屏蔽字了。
@Slf4j
public class TestDemo {
private SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.sss");
@Test
public void genId() throws ParseException {
SnowflakeIdWorker idWorker = new SnowflakeIdWorker(11, 1);
long id = idWorker.nextId(9);
log.info("id {}, binary {}", id, Long.toBinaryString(id));
recoverId(id);
}
/**
* --------------------------------
* | 1 | 39 | 1 | 7 | 8 | 8 |
* --------------------------------
*/
@Test
public void parseId(){
long id = 94811676226289667L;
this.doParse(id);
}
private void doParse(Long id){
log.info("id {}, binary {}", id, Long.toBinaryString(id));
log.info(" ");
log.info("================recover start==============================");
log.info(" ");
long recoverPartnerId = id & getBitMask(SnowflakeIdWorker.placeHoldBits);
log.info("recoverPartnerId : {}, binary {}", recoverPartnerId, Long.toBinaryString(recoverPartnerId));
long sequence = id >>> SnowflakeIdWorker.sequenceIdShift;
long recoverSequence = sequence & getBitMask(SnowflakeIdWorker.placeHoldBits);
log.info("recoverSequence : {}, binary {}", recoverSequence, Long.toBinaryString(recoverSequence));
long workIdShift = id >>> SnowflakeIdWorker.workerIdShift;
long recoverWorkId = workIdShift & getBitMask(SnowflakeIdWorker.workerIdBits);
log.info("recoverWorkId : {}, binary {}", recoverWorkId, Long.toBinaryString(recoverWorkId));
long datacenterShift = id >>> SnowflakeIdWorker.dataCenterIdShift;
long recoverDatacenterId = datacenterShift & getBitMask(SnowflakeIdWorker.datacenterIdBits);
log.info("recoverDatacenterId : {}, binary {}", recoverDatacenterId, Long.toBinaryString(recoverDatacenterId));
long recoverTime = id >>> SnowflakeIdWorker.timestampShift;
log.info("recoverTime : {}, binary {}", recoverTime, Long.toBinaryString(recoverTime));
long timestamp = SnowflakeIdWorker.twepoch + recoverTime;
log.info("timestamp : {}", sdf.format(new Date(timestamp)));
}
private long getBitMask(Long bit){
return -1L ^ -1L << bit;
}
}需要依赖:
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.10</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.16</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.7.16</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>写在最后
分布式的ID生成,基本思路都差不多,在项目中,还碰到一个问题,就是如何为每台服务器分配不重复的workId,实现的方法其实有很多,但基于不同的场景,都有一些限制
1、配置环境变量,为每台服务器分配一个不重复的workId;
优点:简单,方便
缺点:难以维护,特别是服务器数量多的情况下,会是恶梦
在本项目中,由于使用了docker,服务器的配置都是统一的,运维不允许做这样特殊的配置,因此被PASS
2、使用ZK的顺序节点,来建立临时节点
优点:简单,方便,不用担心重复的问题
缺点:依赖ZK,需要牺牲一点性能
本项目中,公司没有提供各业务线自已操作的ZK生产环境,PASS
3、使用IP来分配
优点:简单,方便
缺点:需要维护IP与workId的关系,并自己保证workId的唯一
由于使用docker时,每次启动服务,IP都会变化,因此需要做一些额外的维护工作,来保证workId的不重复,且不超过最大的workId的,目前使用的是这种方法,当workId达到一定值时,重新从0开始分配。