分布式系统中全局唯一ID是我们经常用到的,生成全局ID方法由很多,我们选择的时候也比较纠结。每种方式都有各自的使用场景,如果我们熟悉各种方式及优缺点,结合自身的业务,使用的时候才能更好的选择。
下面我们就一起来看一下常见的生成全局唯一ID的方法
1. 使用数据库自动增长序列实现
最常见最简单的解决方案,数据库内部可以确保生成ID的唯一性。
优点:
1)简单,代码方便,性能可以接受
2)数字ID自动排序,对分页或者需要排序的结果很有帮助
缺点:
1)依赖于数据库数据插入
2)不同数据库语法和实现不同,数据库迁移时,涉及到代码的修改,不利于扩展
2. 使用UUID实现
UUID是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的。通常平台会提供生成的API。按照开放软件基金会(OSF)制定的标准计算,用到了以太网卡地址、纳秒级时间、芯片ID码和随机数。Java标准类库中已经提供了UUID的API。
UUID.randomUUID();
优点:
1)代码简单
2)性能非常高,本地生成,没有网络消耗
3)对其他无依赖,方便扩展
4)全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对
缺点:
1)UUID没有排序,无法保证趋势递增
2)UUID往往是使用字符串存储,查询的效率比较低
3)UUID字符过长,占用空间较大,对传输效率也会有影响,不利于检索
4)不可读
5)信息不安全,基于MAC地址生成UUID的算法可能会造成MAC地址泄露
3. 使用Redis实现
使用Redis的原子操作INCR和INCRBY来实现生成全局唯一的ID。Redis Incr命令将Key中储存的数字值增一。如果Key不存在,那么Key的值会先被初始化为0,然后再执行INCR操作。如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。本操作的值限制在64位(bit)有符号数字表示之内。
工具包 jedis-2.9.0.jar
提取码:ydyj
优点:
1)灵活方便,性能比较高
2)生成的数据是有序的,对排序业务有利
缺点:
1)依赖于Redis组件,增加了系统的复杂性
2)需要编码和配置的工作量比较大
4. 使用Twitter的SnowFlake雪花算法实现
SnowFlake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。
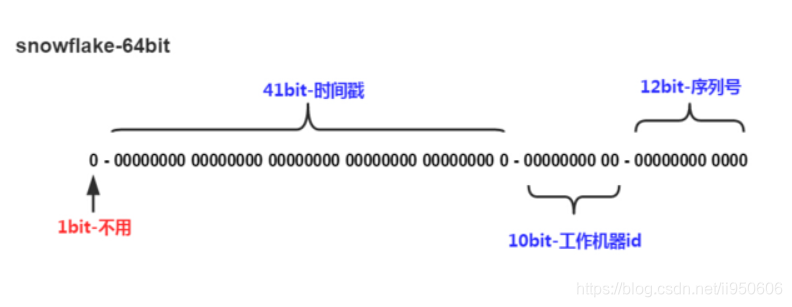
Java实现代码 SnowflakeIdWorker.java
提取码:pq6n
优点:
1)简单高效,生成速度快。
2)时间戳在高位,自增序列在低位,整个ID是趋势递增的,按照时间有序递增。
3)方便灵活,可以根据业务需求,调整bit位的划分,满足不同的需求。
缺点:
1)依赖机器的时钟,如果服务器时钟回拨,会导致重复ID生成。
2)在分布式环境上,每个服务器的时钟不可能完全同步,有时会出现不是全局递增的情况。
赠人玫瑰手留余香,若对您有帮助,来
点个赞呗!