目录
不使用数据库作为 Broker
Broker 的选择大致有消息队列和数据库两种,这里建议尽量避免使用数据库作为 Broker,除非你的业务系统足够简单。在并发量很高的复杂系统中,大量 Workers 访问数据库的行为会使得操作系统磁盘 I/O 一直处于高峰值状态,非常影响系统性能。如果数据库 Broker 同时还兼顾着后端业务的话,那么应用程序也很容易被拖垮。
反观选择消息队列,例如 RabbitMQ,就不存在以上的问题。首先 RabbitMQ 的队列存放到内存中,速度快且不占用磁盘 I/O。再一个就是 RabbitMQ 会主动将任务推送给 Worker,所以 Worker 无需频繁的去轮询队列,避免无谓的资源浪费。
不要过分关注任务结果
Task.delay/Task.apply_async 返回的 AsyncResult 对象用于关联任务的执行结果,前提是启用了 Result Backend。不过任务结果的传递同样需要成本,所以 Celery 默认会将其 Disabled。
- 全局开启返回任务结果,默认为关闭:
app.conf.task_ignore_result = False- 局部关闭返回任务结果:
@app.task(ignore_result=True)
def add(...):如果你仅希望返回并持久化任务执行失败的异常结果,以便于后续的调查分析,那么你可以在使用数据库作为 Result Backend 的同时应用下列配置:
# Only store task errors in the result backend.
app.conf.task_ignore_result = True
app.conf.task_store_errors_even_if_ignored = True实现优先级任务
所谓事有轻重缓急,任务如是。例如,用户的验证码短信比较紧急,应及时发送,而宣传短信则可以延后再发,以此提供更好的用户体验。
实现任务优先级最简单的思路就是,首先将任务进行合理分类,一般的我们会将实时任务、高频率任务、短时间任务划分为高优先级任务;而定时任务、低频率任务、长时间任务则为低优先级任务。然后再为处理高优先级任务的队列分配更多的 Worker。
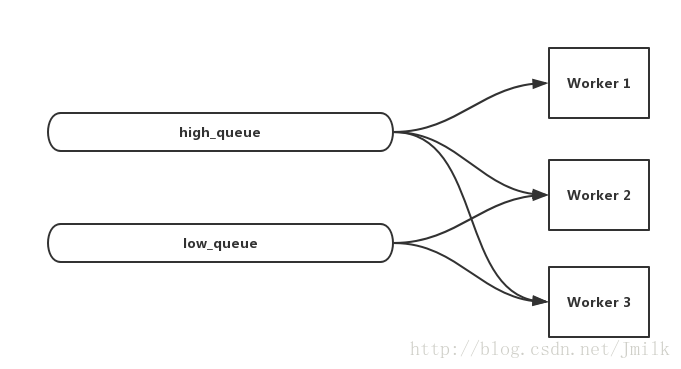
不过这种简单粗暴的方式还存在一个问题,当高优先级任务被消费完后,相应的Workers 就会空闲下来,非常浪费系统资源。那么改善的方法就是,「在高优先级任务队列始终拥有更多 Worker 的前提下,当这些 Worker 空闲时,也可以用于处理低优先级的任务」。利用 Worker 多队列订阅特性即可实现这个效果,例如,现在有 high_queue、low_queue 以及 worker_1、2、3。那么就可以让 worker_1、2、3 均订阅 high_queue 的同时,也让 worker_2、3 订阅 low_queue。
应用 Worker 并发池的动态扩展
Celery Worker 支持下列四种并发方式。

- celery.concurrency.solo (Single-threaded execution pool)
- celery.concurrency.prefork (Multiprocessing)
- celery.concurrency.eventlet
- celery.concurrency.gevent
通过配置项 worker_pool 指定,默认为 prefork:
# Single-threaded execution pool
app.conf.worker_pool = 'solo'同时还可以通过配置项 worker_concurrency 来指定并发池的 size,默认为运行环境的 CPU 数量:
app.conf.worker_concurrency = 10回到正题,当我们选择使用 prefork/gevent 并发方式时,建议应用 Worker 并发池的 autoscale 自动适配功能,在 celery CLI 中使用 --autoscale 选项来指定并发池的上下限。例如:
celery worker -A proj --autoscale=6,3但需要注意的是,无论是 Worker 的数量还是并发池的数量都并非越多越好,毕竟其自身的存在就需要消耗系统资源。但有一个原则是,当你的任务为 I/O 密集型时,可以适量增大并发池的 size;如果你的任务为 CPU 密集型时,默认 size 不失为一个保险的选择。总而言之,最佳配比需要结合自身实际情况不断的尝试得出。
应用任务预取数
Prefetch 预取数是继承至 RabbitMQ 的原语,即为 Worker 一次从队列中获取的任务消息的数量。任务的执行时间有长有短,我们应该为短时间任务设置更大的任务预取数,以降低获取任务带来的资源消耗。
通过配置项 worker_prefetch_multiplier 来指定全局预取数乘子,默认为 4。当设置为 1 时,表示 disable 预取功能;当设置为 0 时,表示 Worker 会尽可能多的获取任务。
# prefetch_count = worker_prefetch_multiplier * concurrent_processes_count
app.conf.worker_prefetch_multiplier = 10如果你的任务既有长任务,又有短任务,那么这里建议你应用分开配置的 Worker 。以文件上传为例,上传小文件(小于 1MB)的数量要远大于上传大文件(大于 20MB)的数量。那么小文件上传任务就属于高频短任务,而大文件上传任务则是低频长任务。分别实现 queue_small/worker_small_1、2 以及 queue_big/worker_big 来处理,同时应该为 worker_small_1、2 设置更大的 Prefetch。
- 设定不同的 celeryconfig 配置文件
# filename: big_prefetch.py
CELERYD_PREFETCH_MULTIPLIER = 10
# filename: small_prefetch.py
CELERYD_PREFETCH_MULTIPLIER = 100- 使用 celery CLI 的 –config 选项分别为 worker 指定不同的 celeryconfig
celery worker -A proj -Q queue_small --config big_prefetch -n worker_small_1
celery worker -A proj -Q queue_small --config small_prefetch -n worker_small_2
celery worker -A proj -Q queue_big --config big_prefetch -n worker_big 保持任务的幂等性
Celery 虽然提供了任务异常重试,但却无法保证任务的事务性,即不提供任务状态的回滚能力。所以为了让任务更易于部署和重试,应该尽量将一个长任务拆解为多个符合幂等性的短任务。
幂等(idempotent)是一个数学概念,常见于抽象代数。幂等性函数的特征为「如果接受到相同的实参,那么无论重复执行多少次,都能得到相同的结果」。例如,get_user_name() 和 set_true() 均属幂等函数。
可见幂等性任务结合任务异常重试,能够非常有效的提高任务执行的健壮性。
应用任务超时限制
避免某些任务一直处于非正常的进行中状态,阻塞队列中的其他任务。应该为任务执行设置超时时间。如果任务超时未完成,则会将 Worker 杀死,并启动新的 Worker 来替代。
- 全局设置任务超时时间:
app.conf.task_time_limit = 1800- 局部设置任务超时时间
@app.task(time_limit=1800)
def add(...):善用任务工作流
Celery 支持 group/chain/chord/chunks/map/starmap 等多种工作流原语,基本可以覆盖大部分复杂的任务组合需求,善用任务工作流能够更好的应用 Celery 优秀的并发特性。例如,如果下一步任务需要等待上一步任务的执行结果,那么不应该单纯的应用 get 方法来实现同步子任务,而是应该使用 chain 任务链。
合理应用 ack_late 机制
使用 RabbitMQ 充当 Broker,可以应用 RabbitMQ 的 ACK 机制来保证任务有效传递。但在任务执行要求非常严格的场景中,「有效传递」显然是不够的,「有效执行」才可以。
为了支持「有效执行」,Celery 在 ACK 的基础上提供了 ack_late 机制。即只有当任务完成(成功/失败)后,再向 Broker 回传 ACK。而代价就是消息队列的性能会降低,毕竟任务消息占用队列资源的时间变长了。
通常的,对于一些以小时为单位的长时间任务,我会建议实现一次只保留一项任务的 ack late 方式。
app.conf.task_acks_late = True
app.conf.worker_prefetch_multiplier = 1- 局部开启 ack_late:
@app.task(ack_late=True)
def add(...):传递 ORM 对象的唯一标识
有时候任务执行需要对象的参与,此时建议传递对象的唯一标识,而非直接将对象序列化后再传递。例如,不要尝试将数据库的 ORM 对象作为任务消息传递,而是传递 ORM 对象的主键 id。当任务执行到需要使用 ORM 对象时,再通过 id 从数据库实时获取,避免 ORM 对象因为队列阻塞导致与数据库实时记录不一致的情况。
预防内存泄漏
同一个 Worker 在执行了大量任务后,会有几率出现内存泄漏的情况。这里建议全局设置 Worker 最大的任务执行数,Worker 在完成了最大的任务执行数后就主动退出。
app.conf.worker_max_tasks_per_child = 100合理安排定时任务的调度计划
定时任务的调度计划要经过科学合理的设计,一般的,我们建议遵守以下几点原则:
- 与系统管理员和数据库管理员沟通,确保你预期的调度时间不会与他们的定时任务冲突。
- 将定时调度任务分散到各个时间点执行,均衡负载。
- 要考虑执行定时任务对生产业务系统的影响,尽可能在业务低峰期执行。
启用任务监控
Flower 是 Celery 官方推荐的实时监控工具,用于监控 Tasks 和 Workers 的运行状态。Flower 提供了下列功能:
- 查看 Task 清单、历史记录、参数、开始时间、执行状态等
- 撤销、终止任务
- 查看 Worker 清单、状态
- 远程开启、关闭、重启 Worker 进程
- 提供 HTTP API,方便集成到运维系统
相比查看日志,Flower 的 Web 界面会显得更加友好。