Celery是一种分布式消息队列处理框架,由Python编写而成。该框架是一个典型的生产者-消费者模型。
一、一些术语与概念
下面,了解几个关键术语,并对应到生产者-消费者模型中的一些概念。
broker,存放消息队列的容器,Celery本身不提供这个容器,一般由RabbitMQ、redis等第三方消息队列机制提供。
tasks,一般写在一个脚本中,作用相当于生产者,用于产生消息。
worker,消费者,从broker获取消息,并进行处理。
backend,worker将消息处理的结果放在backend中,即结果存放的地方。
二、Celery框架的搭建与应用
此处,我们选择RabbitMQ作为消息队列的容器。下面是一个最简单的实例。
1. 安装Celery
# pip install celery
2.安装RabbitMQ
# echo 'deb http://www.rabbitmq.com/debian/ testing main' | sudo tee /etc/apt/sources.list.d/rabbitmq.list
# wget -O- https://www.rabbitmq.com/rabbitmq-release-signing-key.asc | sudo apt-key add -
# sudo apt-get update
# sudo apt-get install rabbitmq-server
安装完毕之后,RMQ默认是启动的。
3.编写tasks.py文件
#tasks.py
from celery import Celery
app = Celery("tasks", broker="amqp://guest@localhost//", backend="amqp://guest@localhost//")
@app.task
def say(sth):
return sth
app = Celery("AppName", broker="消息队列容器", backend="任务处理结果容器"),此处讲应用命名为tasks,消息队列容器和任务处理结果容器均为RabbitMQ。
4.在一个终端执行启动消费者的命令
celery -A tasks worker -l INFO-A 后面是应用名,-l设置log级别。
5.在另一个终端启动生产者的命令
python
>>> from tasks import say
>>> say.delay("Hello Celery!")进入Python的命令行模式,导入应用的say方法,执行。
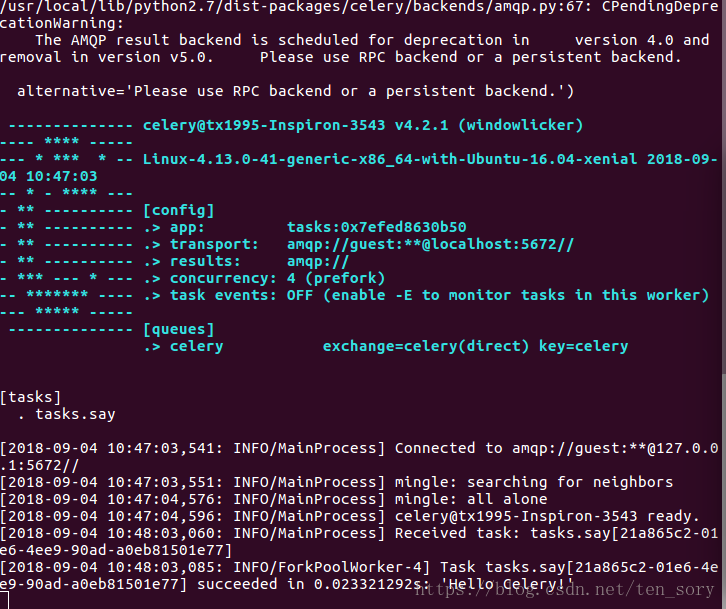
运行结果如下图:
启动消费者终端截图:
启动生产者终端截图:
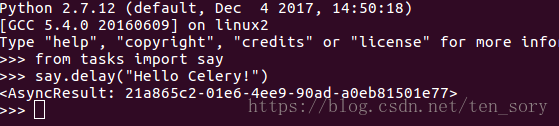
可以看到,代码通过了。