一.需求介绍
前些天碰见个需求,摘取其中一小部分,有用户表,医院表,地区表,以医院和日期(天)的维度下,获取总数。
在数据仓库没有搭建好的情况下,从mysql库ode(源数据),处理完成导入到另一个库中,下面看图示意。
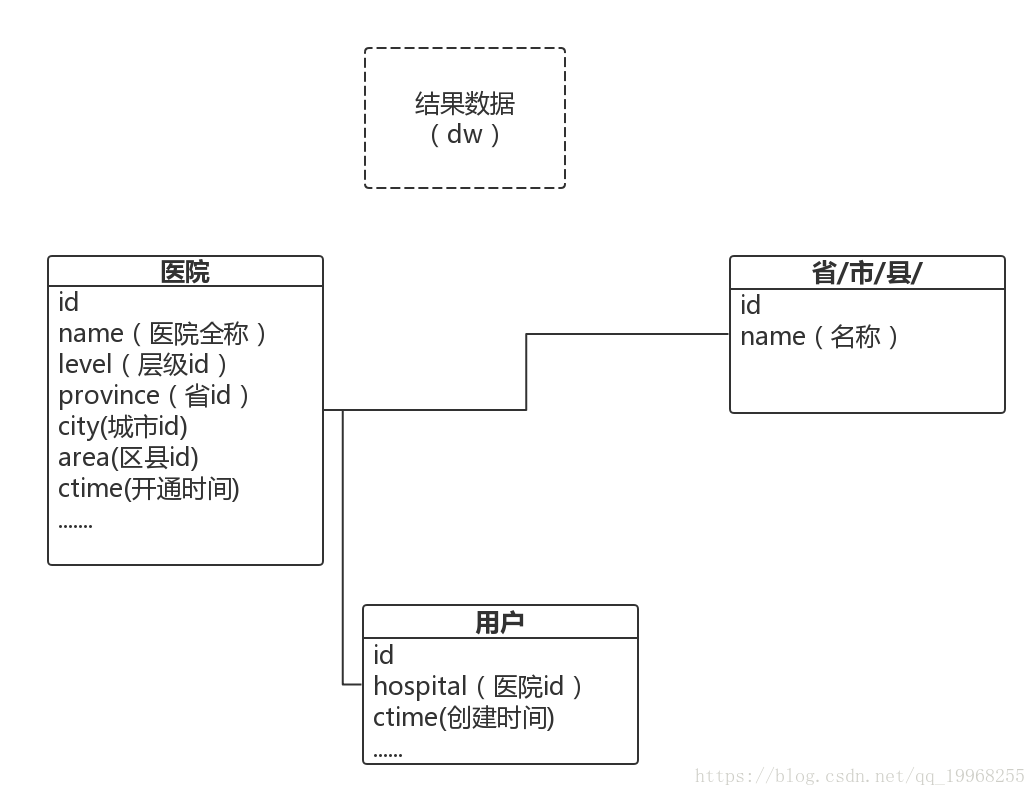
用户与医院是一对多的关系,这个是2B项目,医院分割用户,医院与地区是多对一的关系。

在源数据库处理完数据结果保存到上述表中。
二.技术介绍
Spark SQL是Spark提供的针对结构化数据处理的模块。不同于基本的Spark RDD API,SparkSQL提供的接口提供了更多的关于数据和计算执行的信息。在内部,SparkSQL使用这些额外信息完成额外的优化。这里有几种方式可以和SparkSQL相互操作,包括SQL和Dataset API。计算结果的时候使用相同的执行
实现方法:SparkSql系列--需求02