import numpy as np
import pandas as pd
from pandas import Series, DataFrame
# 打开文件
f = open('city_weather.csv')
df = pd.read_csv(f)
df
Out[7]:
date city temperature wind
0 03/01/2016 BJ 8 5
1 17/01/2016 BJ 12 2
2 31/01/2016 BJ 19 2
3 14/02/2016 BJ -3 3
4 28/02/2016 BJ 19 2
5 13/03/2016 BJ 5 3
6 27/03/2016 SH -4 4
7 10/04/2016 SH 19 3
8 24/04/2016 SH 20 3
9 08/05/2016 SH 17 3
10 22/05/2016 SH 4 2
11 05/06/2016 SH -10 4
12 19/06/2016 SH 0 5
13 03/07/2016 SH -9 5
14 17/07/2016 GZ 10 2
15 31/07/2016 GZ -1 5
16 14/08/2016 GZ 1 5
17 28/08/2016 GZ 25 4
18 11/09/2016 SZ 20 1
19 25/09/2016 SZ -10 4
# 进行分组
g = df.groupby(df['city'])
g
Out[9]: <pandas.core.groupby.DataFrameGroupBy object at 0x0000026486F22BA8>
g.groups
Out[10]:
{'BJ': Int64Index([0, 1, 2, 3, 4, 5], dtype='int64'),
'GZ': Int64Index([14, 15, 16, 17], dtype='int64'),
'SH': Int64Index([6, 7, 8, 9, 10, 11, 12, 13], dtype='int64'),
'SZ': Int64Index([18, 19], dtype='int64')}
# 获取某一个组
g.get_group('BJ')
Out[11]:
date city temperature wind
0 03/01/2016 BJ 8 5
1 17/01/2016 BJ 12 2
2 31/01/2016 BJ 19 2
3 14/02/2016 BJ -3 3
4 28/02/2016 BJ 19 2
5 13/03/2016 BJ 5 3
# 对某一个组进行处理
df_bj = g.get_group('BJ')
df_bj.mean()
Out[14]:
temperature 10.000000
wind 2.833333
dtype: float64
df_bj.describe()
Out[15]:
temperature wind
count 6.000000 6.000000
mean 10.000000 2.833333
std 8.532292 1.169045
min -3.000000 2.000000
25% 5.750000 2.000000
50% 10.000000 2.500000
75% 17.250000 3.000000
max 19.000000 5.000000
# 查看整个groupby
g.mean()
Out[16]:
temperature wind
city
BJ 10.000 2.833333
GZ 8.750 4.000000
SH 4.625 3.625000
SZ 5.000 2.500000
g.describe()
Out[17]:
temperature wind \
count mean std min 25% 50% 75% max count
city
BJ 6.0 10.000 8.532292 -3.0 5.75 10.0 17.25 19.0 6.0
GZ 4.0 8.750 11.842719 -1.0 0.50 5.5 13.75 25.0 4.0
SH 8.0 4.625 12.489281 -10.0 -5.25 2.0 17.50 20.0 8.0
SZ 2.0 5.000 21.213203 -10.0 -2.50 5.0 12.50 20.0 2.0
mean std min 25% 50% 75% max
city
BJ 2.833333 1.169045 2.0 2.00 2.5 3.00 5.0
GZ 4.000000 1.414214 2.0 3.50 4.5 5.00 5.0
SH 3.625000 1.060660 2.0 3.00 3.5 4.25 5.0
SZ 2.500000 2.121320 1.0 1.75 2.5 3.25 4.0
# groupby可转换为列表,列表中为元组,元组中第一个值为分组名,第二个值为dataframe
list(g)
Out[18]:
[('BJ', date city temperature wind
0 03/01/2016 BJ 8 5
1 17/01/2016 BJ 12 2
2 31/01/2016 BJ 19 2
3 14/02/2016 BJ -3 3
4 28/02/2016 BJ 19 2
5 13/03/2016 BJ 5 3),
('GZ', date city temperature wind
14 17/07/2016 GZ 10 2
15 31/07/2016 GZ -1 5
16 14/08/2016 GZ 1 5
17 28/08/2016 GZ 25 4),
('SH', date city temperature wind
6 27/03/2016 SH -4 4
7 10/04/2016 SH 19 3
8 24/04/2016 SH 20 3
9 08/05/2016 SH 17 3
10 22/05/2016 SH 4 2
11 05/06/2016 SH -10 4
12 19/06/2016 SH 0 5
13 03/07/2016 SH -9 5),
('SZ', date city temperature wind
18 11/09/2016 SZ 20 1
19 25/09/2016 SZ -10 4)]
# 可以装换为字典
dict(list(g))
Out[19]:
{'BJ': date city temperature wind
0 03/01/2016 BJ 8 5
1 17/01/2016 BJ 12 2
2 31/01/2016 BJ 19 2
3 14/02/2016 BJ -3 3
4 28/02/2016 BJ 19 2
5 13/03/2016 BJ 5 3,
'GZ': date city temperature wind
14 17/07/2016 GZ 10 2
15 31/07/2016 GZ -1 5
16 14/08/2016 GZ 1 5
17 28/08/2016 GZ 25 4,
'SH': date city temperature wind
6 27/03/2016 SH -4 4
7 10/04/2016 SH 19 3
8 24/04/2016 SH 20 3
9 08/05/2016 SH 17 3
10 22/05/2016 SH 4 2
11 05/06/2016 SH -10 4
12 19/06/2016 SH 0 5
13 03/07/2016 SH -9 5,
'SZ': date city temperature wind
18 11/09/2016 SZ 20 1
19 25/09/2016 SZ -10 4}
# 打印groupby的中每个组的两个参数,name和dataframe
for name, group_df in g:
print(name)
print(group_df)
BJ
date city temperature wind
0 03/01/2016 BJ 8 5
1 17/01/2016 BJ 12 2
2 31/01/2016 BJ 19 2
3 14/02/2016 BJ -3 3
4 28/02/2016 BJ 19 2
5 13/03/2016 BJ 5 3
GZ
date city temperature wind
14 17/07/2016 GZ 10 2
15 31/07/2016 GZ -1 5
16 14/08/2016 GZ 1 5
17 28/08/2016 GZ 25 4
SH
date city temperature wind
6 27/03/2016 SH -4 4
7 10/04/2016 SH 19 3
8 24/04/2016 SH 20 3
9 08/05/2016 SH 17 3
10 22/05/2016 SH 4 2
11 05/06/2016 SH -10 4
12 19/06/2016 SH 0 5
13 03/07/2016 SH -9 5
SZ
date city temperature wind
18 11/09/2016 SZ 20 1
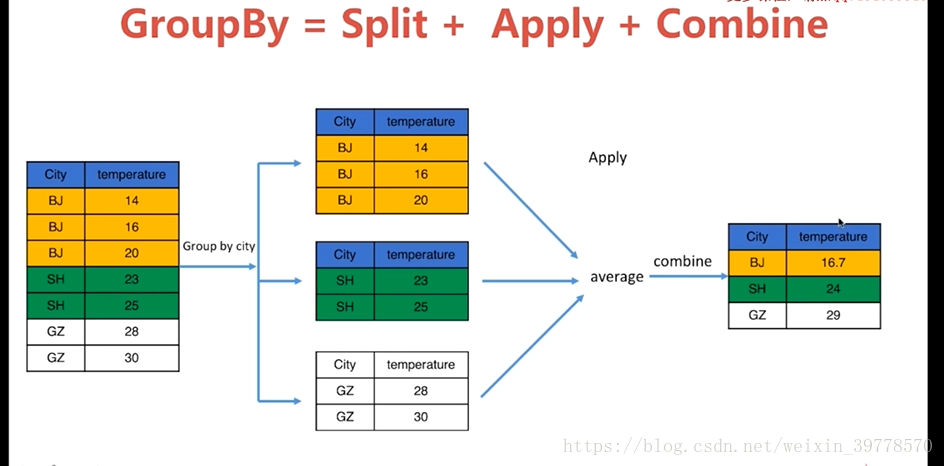
19 25/09/2016 SZ -10 4Pandas玩转数据(十一) -- 数据分组技术Groupby
猜你喜欢
转载自blog.csdn.net/weixin_39778570/article/details/81117881
今日推荐
周排行