本部分是根据书籍“利用python进行数据分析”的笔记
本部分学习pandas入门
本部分学习pandas入门
本部分所有的后续学习都需要导入以下库
from pandas import Series,DataFrame
import numpy as np
import pandas as pd1. pandas的数据结构介绍 pandas主要有两个数据结构:Series和DataFrame
Series是一种类似于一维数组的对象,它由一组数据(例如numpy中的list tuple 数据类)以及与之相关的数据标签组成。仅仅由一组数据也可产生最简单的Series
1.1创建Series数据结构,并进行可视化。
obj=Series([4.5,7.2,-5.3,3.6],index=['d','b','a','c'])
print(obj)
##注意:刚开始的时候没有加index,就一直报错;后来加了index就正确输出了,可能是版本的问题;如果使用python3,只默认一定要加index
out:
d 4.5
b 7.2
a -5.3
c 3.6
dtype: float64#1.2可以通过以下命令获取该数据的values和index属性值
obj.values
out:
array([ 4.5, 7.2, -5.3, 3.6])
obj.index
out:
Index(['d', 'b', 'a', 'c'], dtype='object')
#1.3可以通过索引的方式选取series中单个或者一组值,也可进行修改对应的values
obj['a']=88 #single
obj[['c','a','d']] #获取一组有序值
out:
c 3.6
a 88.0
d 4.5
dtype: float64
#1.4Numpy数组运算(如根据布尔型数组进行过滤、标量乘法、应用数学函数等)都会保留索引和值之间的链接
a1=obj[obj>0]
a2=obj*2
a3=np.exp(obj)
print('a1:')
print(a1)
print('a2:')
print(a2)
print('a3:')
print(a3)
out:
a1:
d 4.5
b 7.2
a 88.0
c 3.6
dtype: float64
a2:
d 9.0
b 14.4
a 176.0
c 7.2
dtype: float64
a3:
d 9.001713e+01
b 1.339431e+03
a 1.651636e+38
c 3.659823e+01
dtype: float64
#1.5可以将series看成是一个定长的有序字典,因为其是索引值到数据值的一个映射。它可以用在许多原本需要字典参数的函数中
'b' in obj
out:
True
#1.6 因为series中的参数可以是一个列表。也可以是一个字典或者元组等,即可以直接通过创建字典来创建series
sdata={'Ohio':35000,'Texas':71000,'Oregon':16000,'Utah':5000}
obj3=Series(sdata)
print(obj3) ###如果只传入一个字典,则结果series中的索引就是原字典中的键
out:
Ohio 35000
Oregon 16000
Texas 71000
Utah 5000
dtype: int64
states=['California','Ohio','Texas','Oregon']
obj4=Series(sdata,index=states)
print(obj4) ##在此处:sdata中跟states索引相匹配的那3个值会被找出来,并放到相应的位置上;California在sadta中没找到,所以为NAN
out:
California NaN
Ohio 35000.0
Texas 71000.0
Oregon 16000.0
dtype: float64
#1.7isnull notnull函数用于检测是否有缺失值
b1=obj4.isnull() #或者pd.isnull(obj4)
b2=obj4.notnull()#或者pd.notnull(obj4)
print('b1:')
print(b1)
print('b2:')
print(b2)
out:
b1:
California True
Ohio False
Texas False
Oregon False
dtype: bool
b2:
California False
Ohio True
Texas True
Oregon True
dtype: bool
#1.8Series会在算术运算中自动对齐不同索引的数据
print('obj3:')
print(obj3)
print('obj4:')
print(obj4)
print(obj3+obj4) ##该运算首先根据两个的索引值分别进行填充(NAN),再对应索引值的values进行加法运算
out:
obj3:
Ohio 35000
Oregon 16000
Texas 71000
Utah 5000
dtype: int64
obj4:
California NaN
Ohio 35000.0
Texas 71000.0
Oregon 16000.0
dtype: float64
California NaN
Ohio 70000.0
Oregon 32000.0
Texas 142000.0
Utah NaN
dtype: float64
#1.9通过name属性给series和index进行命名
obj4.name='population'
obj4.index.name='state'
print(obj4)
out:
state
California NaN
Ohio 35000.0
Texas 71000.0
Oregon 16000.0
Name: population, dtype: float64
#1.10 series的索引还可通过赋值进行修改。但是注意要同长度
obj.index=['Bob','Steve','Jeff','Roy']
print(obj)
out:
Bob 4.5
Steve 7.2
Jeff 88.0
Roy 3.6
dtype: float64
#1.11使用method的ffill可以实现前向值填充,效果如下
obj11=Series(['blue','purple','yellow'],index=[0,2,4])
obj11.reindex(range(6),method='ffill')
out:
0 blue
1 blue
2 purple
3 purple
4 yellow
5 yellow
dtype: object2 DataFrame是一个表格性型的数据结构(二维的),既有行索引,又有列索引
#2.1创建一个DataFrame:最常用的的方法就是直接传入一个等长列表或者numpy数组组成的字典
data={'state':['Ohio','Ohio','Ohio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]}
frame=DataFrame(data)
print(frame)#在DataFrame中列title(columns)是最外面的键,如果没有指定顺序,则会直接默认有序排列;而且如果没有给行索引(index),则会默认0,1,2
out:
pop state year
0 1.5 Ohio 2000
1 1.7 Ohio 2001
2 3.6 Ohio 2002
3 2.4 Nevada 2001
4 2.9 Nevada 2002#2.2##重新定义了列索引(columns)的顺序和行索引(index)
frame=DataFrame(data,columns=['year','state','pop'],index=['a','b','c','d','e'])
frame #2.3对于dataframe使用reindex可以同时修改行列索引,如果仅传入一个序列那么如下
frame2=DataFrame(np.arange(9).reshape((3,3)),index=['a','c','d'],
columns=['ohio','Texas','california'])
frame2
out:(表格图片太大,就直接以数组的形式展示)
ohio Texas california
a 0 1 2
c 3 4 5
d 6 7 8
frame3=frame2.reindex(['a','b','c','d'])
frame3 ##因为frame2中的index中没有b,所以在生成时自动默认设置为NaN
out:
ohio Texas california
a 0.0 1.0 2.0
b NaN NaN NaN
c 3.0 4.0 5.0
d 6.0 7.0 8.0
#2.4使用colunms重新索引列(因为原frame2中没有'Texax','Utah',所以值为NaN)
states=['Texax','Utah','california']
frame2.reindex(columns=states)
out:
Texax Utah california
a NaN NaN 2
c NaN NaN 5
d NaN NaN 8
#2.5同时插入行列,但是插值只能按行应用;同时对行 列进行重新索引 而插值只能引用到行
frame2.reindex(index=['a','b','c','d'],method='ffill',
columns=states) #用到了向前填充
out:
Texax Utah california
a NaN NaN 2
b NaN NaN 2
c NaN NaN 5
d NaN NaN 8
#2.6 丢弃制定轴上的项
#2.6.1 drop方法返回一个指定轴上删除了指定值的新对象,删除列c
#丢弃指定轴的项
obj=Series(np.arange(5.),index=['a','b','c','d','e'])
new_obj=obj.drop('c')
print('obj:')
print(obj)
print('new_obj:')
print(new_obj)
out:
obj:
a 0.0
b 1.0
c 2.0
d 3.0
e 4.0
dtype: float64
new_obj:
a 0.0
b 1.0
d 3.0
e 4.0
dtype: float64
#2.6.2 删除两个 b c
obj.drop(['b','c'])
out:
a 0.0
d 3.0
e 4.0
dtype: float64
#2.6.3 对于dataframe可以删除任意轴上的索引
#对于DataFrame可以删除任意轴的索引
data = DataFrame(np.arange(16).reshape((4,4)),
index=['ohio','colorado','utah','new york'],
columns=['one','two','three','four'])
data
data.drop(['colorado','ohio']) #删除两个
out:(两个一起展示)
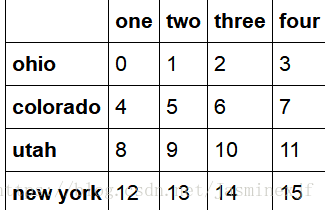
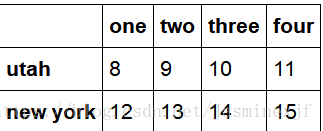
#2.7 索引,选取和过滤
#2.7.1 Series中的索引类似与Numpy,但是不只是整数,索引字符
obj=Series(np.arange(4.),index=['a','b','c','d'])
print(obj)
obj['b']#1.0
out:
a 0.0
b 1.0
c 2.0
d 3.0
dtype: float64
1.0
#2.7.2 按照整数,范围
obj[2:4]# 2 3 ##不包含末端
out:
c 2.0
d 3.0
dtype: float64
#2.7.3 利用标签的切片运算和普通depython切片不同,其包含末端
obj['b':'c']#b c 1 2
out:
b 1.0
c 2.0
dtype: float64
#2.7.4对dataframe进行索引就是获取一个或者多个列
data=DataFrame(np.arange(16).reshape(4,4),
index=['ohio','colorado','mike','jason'],
columns=['one','two','three','four'])
data
out:
one two three four
ohio 0 1 2 3
colorado 4 5 6 7
mike 8 9 10 11
jason 12 13 14 15
data['two']#一列
out:
ohio 1
colorado 5
mike 9
jason 13
Name: two, dtype: int32
data[['three','one']]#多列
out:
three one
ohio 2 0
colorado 6 4
mike 10 8
jason 14 12
#2.7.5 直接选取行标签前两行
data[:2] #选取的是前面两行
one two three four
ohio 0 1 2 3
colorado 4 5 6 7
#2.7.6 选取第三列大于5的值
data[data['three']>5]
out:
one two three four
colorado 4 5 6 7
mike 8 9 10 11
jason 12 13 14 15
#2.7.7 为了能在dataframe的行上进行标签索引引入字段ix
data.ix['colorado',['two','three']]
out:
two 5
three 6
Name: colorado, dtype: int32
#选取第4 1 2列 而且行为colorado jason
data.ix[['colorado','jason'],['four','one','two']]
out:
four one two
colorado 7 4 5
jason 15 12 13
#2.7.8 输出整行 输出行mike
data.ix[2]
out:
one 8
two 9
three 10
four 11
Name: mike, dtype: int32#2.8 算数运算和数据对齐
#2.8.1 Series的加法
s1=Series([7.3,-2.5,3.4,1.5],index=['a','c','d','e'])
s2=Series([-2.1,3.6,-1.5,4,3.1],index=['a','c','e','f','g'])
print('s1:')
print(s1)
print('s2:')
print(s2)
s1+s2
out:
s1:
a 7.3
c -2.5
d 3.4
e 1.5
dtype: float64
s2:
a -2.1
c 3.6
e -1.5
f 4.0
g 3.1
dtype: float64
Out[77]:
a 5.2
c 1.1
d NaN
e 0.0
f NaN
g NaN
dtype: float64
#2.8.2 对于dataframe的加法,对齐会同时发生在行和列中,如下例子
df1=DataFrame(np.arange(9.).reshape((3,3)),columns=list('bcd'),index=['utah','ohio','colorado'])
df2=DataFrame(np.arange(12.).reshape((4,3)),columns=list('bde'),index=['utah','ohio','colorado','oragen'])
df1
df2
df1+df2 ###首先对于行索引和列索引进行求并集,然后再根据并的索引值,对应相加。如果dfi没有某索引值,则对其进行Nan的填充
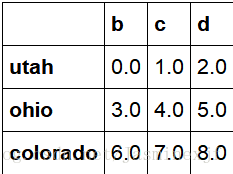
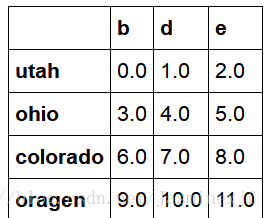
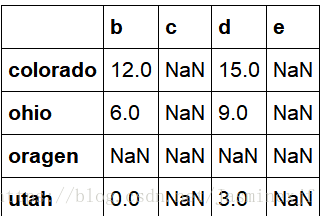
#2.8.3 在算术方法中填充值。比如说两个dataframe相加,其中一个没有相应索引的时候填充为0(避免出现Nan的情况)
df1=DataFrame(np.arange(12.).reshape((3,4)),columns=list('abcd'))
df2=DataFrame(np.arange(20.).reshape((4,5)),columns=list('abcde'))
df1+df2(左表)
#具体实施方法如下; #使用df1的add方法 传入df2以及一个fill_value参数(即没有某索引时,不会用Nan进行填充,而是用0进行填充)
df1.add(df2,fill_value=0)(右表)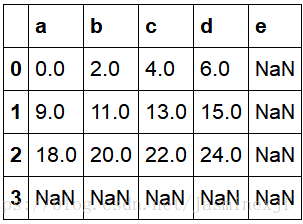
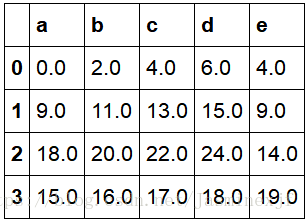
#2.9 DataFrame和Series之间的运算----->广播,也就是如果第一个数值-1,那么这个列都会减1
#2.9.1 看一看一个二维数组和一行之间的差
arr=np.arange(12.).reshape((3,4))
arr
out:
array([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]])
arr[0]
out:
array([0., 1., 2., 3.])
arr-arr[0] #元arr中对应行的元素减去arr[0]相应位置的元
out:
array([[0., 0., 0., 0.],
[4., 4., 4., 4.],
[8., 8., 8., 8.]])
#2.9.2 frame和series的运算
frame=DataFrame(np.arange(12.).reshape((4,3)),columns=list('bde'),
index=['utah','ohio','texas','orogen'])
series=frame.ix[0]
frame
out:
b d e
utah 0.0 1.0 2.0
ohio 3.0 4.0 5.0
texas 6.0 7.0 8.0
orogen 9.0 10.0 11.0
series
out:
b 0.0
d 1.0
e 2.0
Name: utah, dtype: float64
frame-series ##同样是frame中每行的元素减series中对应元素
out:
b d e
utah 0.0 0.0 0.0
ohio 3.0 3.0 3.0
texas 6.0 6.0 6.0
orogen 9.0 9.0 9.0