原文地址:https://blog.csdn.net/jungle_pig/article/details/71172985
前言:本文重点在第4部分,Android中Base64算法的使用,主要是介绍android.util.Base64类,其他为对Base64原理的讲解,不关心原理的小伙伴,可直接阅读第4部分
1.何为Base64?
Base64并不是一种加密算法,而是一种转码算法。它把字节序列按照映射表转码为便于传输的64个可见字符,降低数据出错率。这也是它的名字的由来,即“基于64个字符”之意。通常我们在将数据加密后,经过Base64转码后再进行传输。按照Base64算法转码后的字节,通过逆运算可以得到原始字节,至于原始字节代表的含义,并不关心,也就是说,可以转码的数据并不限于文本,但转码结果均是64个可打印字符组成的序列(末尾可能出现1或2个“=”字符,其含义后续说明)。
2.Base64映射表
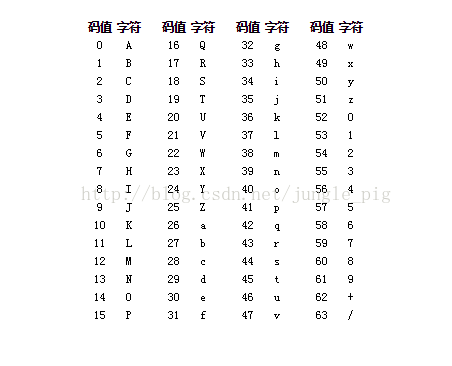
3.Base64转码规则
Base64转码把3个8位字节(3*8=24)转化为4个6位区块(4*6=24,因为Base64算法的最大映射值为63,用6个比特位即可表示),之后在每个6位区块的前面补两个0,形成一个8位字节。 如果剩余字节数不足3个,则用0填充(该字节映射为字符'=',所以转码后结尾可能有一或两个'='字符)。
按照上述规则处理后,按照映射表,求出每个字节的对应的Base64字符,例如,假设第一个字节的位序列为00000011,也就是3,根据映射表3对应'D',所以这个字节转码后用字符D表示。
注意:在转码成Base64字符后,这些字符序列是按照ASCII字符集存储,‘D’对应的ASCII码值为68,所以存为01000100,而不是3(00000011),很多初学者以为映射表中的码值就是转码后字符的字节值,这是不对的,映射表中的码值是对“分区块”处理后的每个字节映射转换Base64字符时所用。顺便附上ASCII表(打印字符部分):
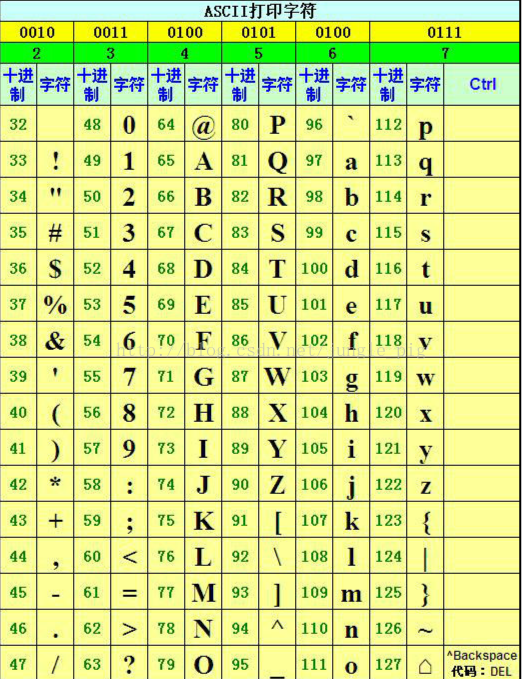
数据还原时,先把Base64字符按照ASCII字符集转换成字节,然后进行“分区处理”的逆运算,得到原始字节。
4.☆Android中的使用
终于到了本文重点了,理解原理固然如有神助,运用才是硬道理。我看到很多android小伙伴都自行编写Base64处理类,或者网上找个现成的Base64工具类,其实大可不必。Android内置了Base64的处理。有的小伙伴担心自己的后台不是Java后台,其实Base64是一种算法,是与语言不相关的,每种语言都会有自己对应的实现,得到的结果是一致的。有时前端和后台解码后的数据之所以不一致,并非语言不通所致,而是一些Base64处理规则没有保持一致,比如,若结尾有‘=’字符,是否略去,等等。当然这些后续也会提到,闲话少叙,直接上代码。
android.util 包下的Base64类提供了一些静态方法:
(1)public static byte[] encode(byte[] input, int flags);
将字节数组进行转码,得到转码后的字节数组(Base64字符对应的ASCII字节值)。
(2)public static byte[] encode(String str, int flags);
将一个字符串进行转码,该方法等价于Base64.encode(str.getBytes(),flags);
(3)public static String encodeToString(byte[] input, int flags) ;
将字节数组转码成Base64字符。我们看一下它的实现:
- public static String encodeToString(byte[] input, int flags) {
- try {
- return new String(encode(input, flags), "US-ASCII");
- } catch (UnsupportedEncodingException e) {
- // US-ASCII is guaranteed to be available.
- throw new AssertionError(e);
- }
- }
该方法实际上是将上一个方法的结果转成字符,我们看到它转换成字符时,传入的字符集的确是ASCII,这也印证了前面的说法。
(4)public static byte[] decode(byte[] input, int flags);
将转码后的字节还原成原始字节。
(5)public static byte[] decode(String str, int flags);
将Base64字符序列还原成原始字节。看一看它的实现:
- public static byte[] decode(String str, int flags) {
- return decode(str.getBytes(), flags);
- }
博主很久以前看到实现的时候比较疑惑,按照我前面的说法,不应该先按ASCII字符集转成字节值吗,后来才明白,原来UTF-8、GBK、gb2312、ISO_8859_1字符集中,这64个字符的对应的字节值以及所占用的字节数与ASCII完全一样。所以str.getBytes()与str.getBytes("US-ASCII")等效。我们打印下来看看。
先写段测试代码:
我用Base64在线转码工具得到 “我爱你android”的转码字符序列:5oiR54ix5L2gYW5kcm9pZA==
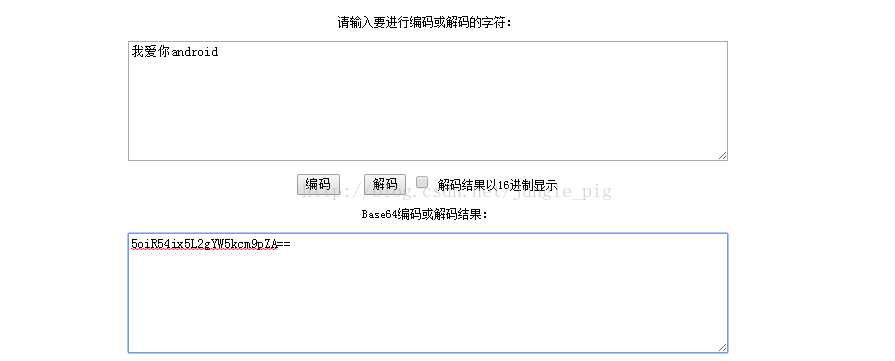
咱们以此字符串作为测试,看看不同字符集对应的字节值和占用字节数:
- private static final String TAG = "朱志强";
- @Override
- protected void onCreate(Bundle savedInstanceState) {
- super.onCreate(savedInstanceState);
- setContentView(R.layout.activity_main);
- String testStr = "5oiR54ix5L2gYW5kcm9pZA==";
- Log.d(TAG,"测试字符串为:" + testStr);
- try {
- Log.d(TAG,"UTF-8: 字节总数->" + testStr.getBytes().length + "\n 字节值-"
- + Arrays.toString(testStr.getBytes()));
- Log.d(TAG,"GBK: 字节总数->" + testStr.getBytes("GBK").length + "\n 字节值-"
- + Arrays.toString(testStr.getBytes("GBK")));
- Log.d(TAG,"gb2312: 字节总数->" + testStr.getBytes("gb2312").length + "\n 字节值-"
- + Arrays.toString(testStr.getBytes("gb2312")));
- Log.d(TAG,"ISO_8859_1: 字节总数->" + testStr.getBytes("ISO_8859_1").length + "\n 字节值-"
- + Arrays.toString(testStr.getBytes("ISO_8859_1")));
- Log.d(TAG,"US-ASCII: 字节总数->" + testStr.getBytes("US-ASCII").length + "\n 字节值-"
- + Arrays.toString(testStr.getBytes("US-ASCII")));
- Log.d(TAG,"Unicode: 字节总数->" + testStr.getBytes("Unicode").length + "\n 字节值-"
- + Arrays.toString(testStr.getBytes("Unicode")));
- } catch (UnsupportedEncodingException e) {
- e.printStackTrace();
- }
- }
输出的结果为:
- 朱志强: 测试字符串为:5oiR54ix5L2gYW5kcm9pZA==
- 朱志强: UTF-8: 字节总数->24
- 字节值-[53, 111, 105, 82, 53, 52, 105, 120, 53, 76, 50, 103, 89, 87, 53, 107, 99, 109, 57, 112, 90, 65, 61, 61]
- 朱志强: GBK: 字节总数->24
- 字节值-[53, 111, 105, 82, 53, 52, 105, 120, 53, 76, 50, 103, 89, 87, 53, 107, 99, 109, 57, 112, 90, 65, 61, 61]
- 朱志强: gb2312: 字节总数->24
- 字节值-[53, 111, 105, 82, 53, 52, 105, 120, 53, 76, 50, 103, 89, 87, 53, 107, 99, 109, 57, 112, 90, 65, 61, 61]
- 朱志强: ISO_8859_1: 字节总数->24
- 字节值-[53, 111, 105, 82, 53, 52, 105, 120, 53, 76, 50, 103, 89, 87, 53, 107, 99, 109, 57, 112, 90, 65, 61, 61]
- 朱志强: US-ASCII: 字节总数->24
- 字节值-[53, 111, 105, 82, 53, 52, 105, 120, 53, 76, 50, 103, 89, 87, 53, 107, 99, 109, 57, 112, 90, 65, 61, 61]
- 朱志强: Unicode: 字节总数->50
- 字节值-[-1, -2, 53, 0, 111, 0, 105, 0, 82, 0, 53, 0, 52, 0, 105, 0, 120, 0, 53, 0, 76, 0, 50, 0, 103, 0, 89, 0,
- 87, 0, 53, 0, 107, 0, 99, 0, 109, 0, 57, 0, 112, 0, 90, 0, 65, 0, 61, 0, 61, 0]
可以看到,结果与之前所说一致,同时也看到Unicode却不具备这种情况。Java代码中字符串默认以Unicode编码,咱们看一下Java中类似的代码是如何处理的:这里说明一点,Java中的Base64位于java.util包下,Android剔除了该类,后者的Base64类位于android.util包下。
- Base64.getDecoder().decode("5oiR54ix5L2gYW5kcm9pZA==");
- public byte[] decode(String src) {
- return decode(src.getBytes(StandardCharsets.ISO_8859_1));
- }
可以看到,它并没有像Android一样直接调用src.getBytes(),Unicode与ASCII对这64个字符编码的字节值和占用字节数并不一样,而是传入字符集ISO_8859-1,效果与ASCII等价。
5.flag参数的含义
Android中的四个静态方法都有一个int型flags参数,它们的值可以是如下几种:
(1)DEFAULT 这个参数是默认,使用默认的方法来加密
(2)NO_PADDING 这个参数是略去加密字符串最后的”=”
(3)NO_WRAP 这个参数意思是略去所有的换行符(设置后CRLF就没用了)
(4)CRLF 这个参数看起来比较眼熟,它就是Win风格的换行符,意思就是使用CR LF这一对作为一行的结尾而不是Unix风格的LF
(5)URL_SAFE 这个参数意思是加密时不使用对URL和文件名有特殊意义的字符来作为加密字符,具体就是以-和_取代+和/