TF-IDF算法
TF-IDF(词频-逆文档频率)算法是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。该算法在数据挖掘、文本处理和信息检索等领域得到了广泛的应用,如从一篇文章中找到它的关键词。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF-IDF实际上就是 TF*IDF,其中 TF(Term Frequency),表示词条在文章Document 中出现的频率;IDF(Inverse Document Frequency),其主要思想就是,如果包含某个词 Word的文档越少,则这个词的区分度就越大,也就是 IDF 越大。对于如何获取一篇文章的关键词,我们可以计算这边文章出现的所有名词的 TF-IDF,TF-IDF越大,则说明这个名词对这篇文章的区分度就越高,取 TF-IDF 值较大的几个词,就可以当做这篇文章的关键词。
计算步骤
-
计算词频(TF)
词频 = 某个词在文章中的出现次数 / 文章总次数
-
计算逆文档频率(IDF)
逆文档频率 = log(语料库的文档总数 / (包含和改词的文档数 + 1)) (10为底)
-
计算词频-逆文档频率(TF-IDF)
TF-IDF = 词频 * 逆文档频率
举例
对《中国的蜜蜂养殖》进行词频(Term Frequency,缩写为TF)统计
出现次数最多的词是----“的”、“是”、“在”----这一类最常用的词(停用词),不计入统计范畴。
发现“中国”、“蜜蜂”、“养殖”这三个词的出现次数一样多,重要性是一样的?
"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见
《中国的蜜蜂养殖》:假定该文长度为1000个词,"中国"、"蜜蜂"、"养殖"各出现20次, 则这三个词的"词频"(TF)都为0.02
假定搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数。包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张。
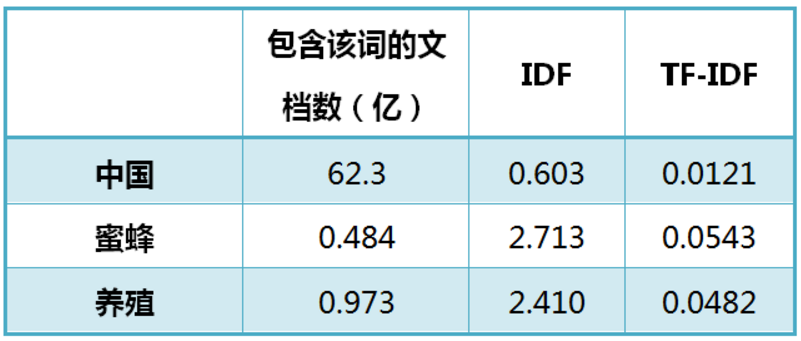
可见蜜蜂和养殖比中国在文档中更‘关键’,即更具有代表性。