环境:solr:7.4.0,centos:6,7都能跑
solr7.4.0内置jetty服务器,可以直接运行,不要再弄个tomcat画蛇添足!
下载
linux系统找个位置,随便哪里,只要你喜欢就行(假设为/test)
执行:wget http://mirrors.shuosc.org/apache/lucene/solr/7.4.0/solr-7.4.0.tgz (上海大学开源镜像站,不能用的话去官网下载)
下载好tar -zxvf解压到当前目录
cd /test/solr-7.4.0
执行启动命令 ./bin/solr start -force 懂英文的就知道是否成功了,顺变提一下,停止服务命令为./bin/solr stop -all;
成功之后浏览器输入yourip:8983/solr 此时会出来solr主页,入下图

点击Core Admin,点击Add Core添加自己的Core(我的理解是一个操作数据库的实例,可以添加多个,连接不通的库不同的表)name和instanceDir随便写(假设为test_core,下面引用),你喜欢就行;这时候点add core确定时会报错,别担心,test_core文件已经存在,位置为/test/solr-7.4.0/server/solr/test_core
进入/test/solr-7.4.0/server/solr/configsets/_default此目录里面有个conf目录
cp -r conf /test/solr-7.4.0/server/solr/test_core
复制过去,再点击add core确定按钮就行了;
进入/test/solr-7.4.0/dist,把solr-dataimporthandler-extras-7.4.0.jar和solr-dataimporthandler-7.4.0.jar复制到
/test/solr-7.4.0/server/solr-webapp/webapp/WEB-INF/lib下面,再找个数据库驱动jar例如mysql驱动(mysql-connector-java-5.1.45.jar)放在此位置
下面来配置刚刚复制过来的conf
修改conf目录下的solrconfig.xml,找个位置添加
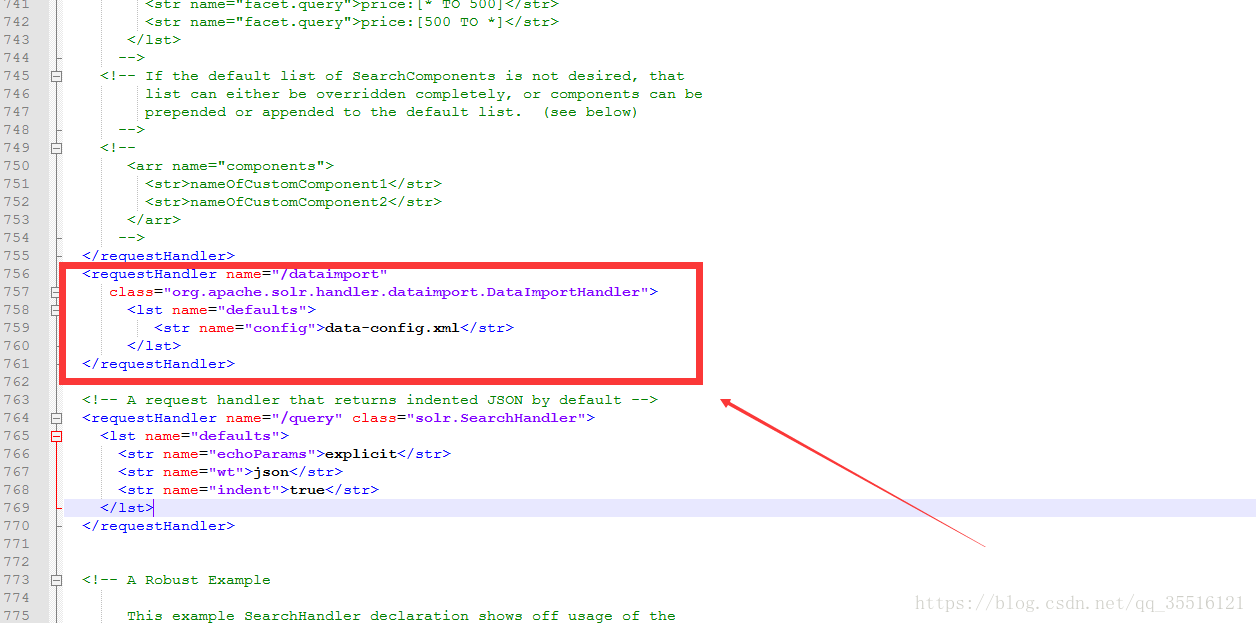
<requestHandler name="/dataimport"
class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>conf目录下再创建data-config.xml文件,写入代码如下
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://192.168.20.197:3306/hairuide"
user="root"
password="root123" />
<document>
<entity name="FileList" PK="id"
query="select * from filelist where isDel='0'"
deltaImportQuery="select * from filelist WHERE id = '${dih.delta.id}'"
deltaQuery="SELECT id FROM filelist where createTime > '${dataimporter.last_index_time}'"
deletedPkQuery="select id from filelist where isDel = '1'"
>
<field column="id" name="id" />
<field column="fileName" name="fileName" />
<field column="fileUrl" name="fileUrl" />
<field column="createTime" name="createTime" />
<field column="isDel" name="isDel" />
</entity>
</document>
</dataConfig>dataSource没什么说的,entity中name属性为表明,pk为表主键,query为全查询,deltaImportQuery为增量更新,配合deltaQuery使用,deletePkQuery为软删除的时候做的更新;field中的column对应数据库中的字段,name对应java实体类中的字段
修改conf目录下的managed-schema
加入
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="fileName" type="string" indexed="true" stored="true" />
<field name="fileUrl" type="string" indexed="true" stored="true" />
<field name="createTime" type="string" indexed="true" stored="true" />
<field name="isDel" type="string" indexed="true" stored="true" />保留
<field name="_version_" type="plong" indexed="false" stored="false"/>
<field name="_root_" type="string" indexed="true" stored="false" docValues="false" />
<field name="_text_" type="text_general" indexed="true" stored="false" multiValued="true"/>其中_root_中type要和id的type一致,不然会报错(我的数据库中id为varchar类型,这边type就是string,id为int类型据说type也可以写成string,据说此文件中存在<uniqueKey>id</uniqueKey>,若数据库中主键为id,可以不加入id的field)
时间配置,solr默认时间为utc和中国标准时间相差8小时,解决:把bin下的solr文件拉出来查找UTC改为UTC+8
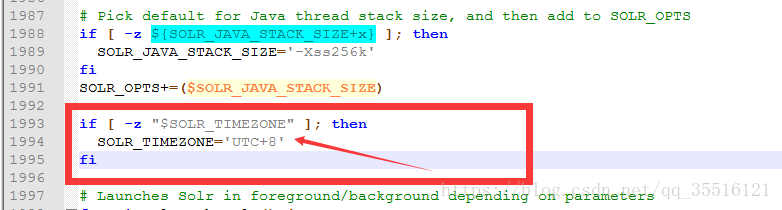
时间记录在/test/solr-7.4.0/server/solr/test_core/conf目录的dataimport.properties里
配置完成;
执行./bin/stop -all 接着执行./bin/start -force
服务启动成功,进入solr主页,点击core selector,选择你建的test_core,点击dataimport点击execute执行
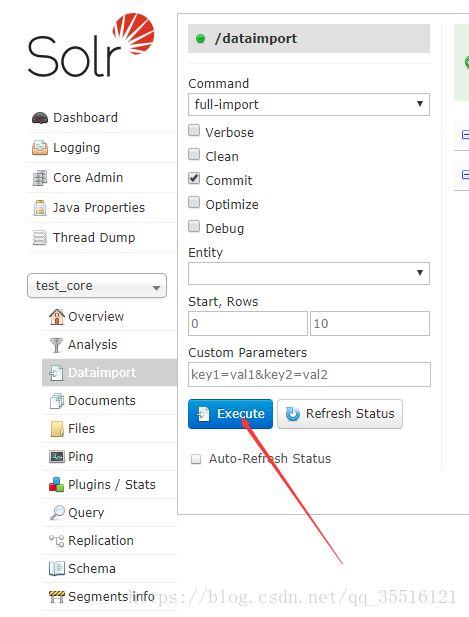
成功就能看到效果(Query可以查询),失败请转向本页面的logging(这个前端咋是用angular js,现在不都用react了吗)
数据库添加删除或者修改,把此Command选择delta-import执行再点击Query查询,就能看到更改的效果了
这里我们F12抓住delta-import请求,经过分析,写个定时器执行此增量更新
添加jar依赖
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-solr</artifactId>
</dependency>springboot启动类加注解
@EnableScheduling更新方法如下:每五秒执行一次
@Scheduled(cron = "0/5 * * * * *")
public void updateSolr(){
MultiValueMap<String, Object> postParameters = new LinkedMultiValueMap<>();
postParameters.add("command", "delta-import");
postParameters.add("verbose", "false");
postParameters.add("clean", "false");
postParameters.add("commit", "true");
postParameters.add("core", "test_core");
postParameters.add("name", "dataimport");
HttpHeaders headers = new HttpHeaders();
headers.add("Content-Type", "application/x-www-form-urlencoded");
HttpEntity<MultiValueMap<String, Object>> r = new HttpEntity<>(postParameters, headers);
String time = String.valueOf(new Date().getTime());
String url = "http://192.168.20.197:8983/solr/test_core/dataimport?_=" + time + "&indent=on&wt=json";
String responseMessage = restTemplate.postForObject(url, r, String.class);
logger.info("更新solr索引:返回值:{}",responseMessage);
}实体类:
@SolrDocument
public class FileList implements Serializable {
@Id
@Field
private String id; //主键需要加两个注解
@Field
private String fileName; //普通的属性加Field注解即可
@Field
private String fileUrl;
@Field
private String createTime;
@Field
private String isDel;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getFileName() {
return fileName;
}
public void setFileName(String fileName) {
this.fileName = fileName;
}
public String getFileUrl() {
return fileUrl;
}
public void setFileUrl(String fileUrl) {
this.fileUrl = fileUrl;
}
public String getCreateTime() {
return createTime;
}
public void setCreateTime(String createTime) {
this.createTime = createTime;
}
public String getIsDel() {
return isDel;
}
public void setIsDel(String isDel) {
this.isDel = isDel;
}
}查询数据:
HttpSolrClient solrClient = new HttpSolrClient.Builder("http://192.168.20.197:8983/solr/test_core").build();
SolrQuery query = new SolrQuery();
query.setSort("createTime", SolrQuery.ORDER.asc); //设置排序参数及排序规则
String pageNo = "1"; //第几页
String pageSize = "10"; //每页多少数据
if (NumberUtils.isDigits(pageNo) && NumberUtils.isDigits(pageSize)) {
int startPage = Integer.valueOf(pageNo);
int pageNum = Integer.valueOf(pageSize);
query.setStart((startPage - 1) * pageNum);//起始页,这里一定要注意,不能直接把pageNo赋值给start,start表示从第一个数据开始,第一条从0开始。
query.setRows(pageNum);//每页显示数量
}
StringBuilder buffer = new StringBuilder();
String fileName = ""; //查询条件
if (!StringUtils.isEmpty(fileName)) {
buffer.append("fileName:" + fileName); //如果你的fileName字段在/conf/manage-schema文件中定义的类型是text_ik,即已经分词了,那么这里可以这么写,如果你定义的是string类型,即没有分词,那这句话的append中的内容需要写成这样buffer.append("fileName:*"+fileName+"*"),这是solr的查询规则,没有分词最好是加上模糊查询符号"*"
query.set("q", buffer.toString());
} else {
query.set("q", "*:*"); //没有传入参数则全部查询
}
QueryResponse rsp = null;
try {
rsp = solrClient.query(query);
} catch (Exception e) {
e.printStackTrace();
}
SolrDocumentList results = rsp.getResults();
System.out.println(results.getNumFound());//查询总条数,该总条数是符合该条件下的总条数,并不是pageSize的数量。
List<FileList> fbfList = rsp.getBeans(FileList.class);//该方法将返回结果转换为对象,很方便。
logger.info("查询总条数为:{},第一条的文件名:{}",results.getNumFound(),fbfList.get(0).getFileName());cron表达式设置
●星号(*):可用在所有字段中,表示对应时间域的每一个时刻,例如,*在分钟字段时,表示“每分钟”;
●问号(?):该字符只在日期和星期字段中使用,它通常指定为“无意义的值”,相当于点位符;
●减号(-):表达一个范围,如在小时字段中使用“10-12”,则表示从10到12点,即10,11,12;
●逗号(,):表达一个列表值,如在星期字段中使用“MON,WED,FRI”,则表示星期一,星期三和星期五;
●斜杠(/):x/y表达一个等步长序列,x为起始值,y为增量步长值。如在分钟字段中使用0/15,则表示为0,15,30和45秒,而5/15在分钟字段中表示5,20,35,50,你也可以使用*/y,它等同于0/y;
●L:该字符只在日期和星期字段中使用,代表“Last”的意思,但它在两个字段中意思不同。L在日期字段中,表示这个月份的最后一天,如一月的31号,非闰年二月的28号;如果L用在星期中,则表示星期六,等同于7。但是,如果L出现在星期字段里,而且在前面有一个数值X,则表示“这个月的最后X天”,例如,6L表示该月的最后星期五;
●W:该字符只能出现在日期字段里,是对前导日期的修饰,表示离该日期最近的工作日。例如15W表示离该月15号最近的工作日,如果该月15号是星期六,则匹配14号星期五;如果15日是星期日,则匹配16号星期一;如果15号是星期二,那结果就是15号星期二。但必须注意关联的匹配日期不能够跨月,如你指定1W,如果1号是星期六,结果匹配的是3号星期一,而非上个月最后的那天。W字符串只能指定单一日期,而不能指定日期范围;
●LW组合:在日期字段可以组合使用LW,它的意思是当月的最后一个工作日;
●井号(#):该字符只能在星期字段中使用,表示当月某个工作日。如6#3表示当月的第三个星期五(6表示星期五,#3表示当前的第三个),而4#5表示当月的第五个星期三,假设当月没有第五个星期三,忽略不触发;
● C:该字符只在日期和星期字段中使用,代表“Calendar”的意思。它的意思是计划所关联的日期,如果日期没有被关联,则相当于日历中所有日期。例如5C在日期字段中就相当于日历5日以后的第一天。1C在星期字段中相当于星期日后的第一天。
Cron表达式对特殊字符的大小写不敏感,对代表星期的缩写英文大小写也不敏感。
表2下面给出一些完整的Cron表示式的实例:
CRON表达式 含义
"0 0 12 * * ?" 每天中午十二点触发
"0 15 10 ? * *" 每天早上10:15触发
"0 15 10 * * ?" 每天早上10:15触发
"0 15 10 * * ? *" 每天早上10:15触发
"0 15 10 * * ? 2005" 2005年的每天早上10:15触发
"0 * 14 * * ?" 每天从下午2点开始到2点59分每分钟一次触发
"0 0/5 14 * * ?" 每天从下午2点开始到2:55分结束每5分钟一次触发
"0 0/5 14,18 * * ?" 每天的下午2点至2:55和6点至6点55分两个时间段内每5分钟一次触发
"0 0-5 14 * * ?" 每天14:00至14:05每分钟一次触发
"0 10,44 14 ? 3 WED" 三月的每周三的14:10和14:44触发
"0 15 10 ? * MON-FRI" 每个周一、周二、周三、周四、周五的10:15触发
欢迎学习交流,邮箱:[email protected]