对字符串编码进行汇总和区别
编码的由来:
计算机自己能理解的“语言”是二进制数,最小的信息标识是二进制数,8个二进制位表示一个字节;而我们人类所能理解的语言文字则是一套由英文字母、汉语汉字、标点符号字符、阿拉伯数字等等很多的字符构成的字符集。如果要让计算机来按照人类的意愿进行工作,则必须把人类所使用的这些字符集转换为计算机所能理解的二进制码,这个过程就是编码,他的逆过程称为解码。
最开始计算机在美国发明使用,需要编码的字符集并不是很大,无外乎英文字母、数字和一些简单的标点符号,因此采用了一种单字节编码系统。在这套编码规则中,人们将所需字符集中的字符一一映射到128个二进制数上,这128个二进制数是最高位为0,利用剩余低7位组成00000000~01111111(0X00~0X7F)。0X00到0X1F共32个二进制数来对控制字符或通信专用字符(如LF换行、DEL删除、BS退格)编码,0X20到0X7F共96个二进制数来对阿拉伯数字、英文字母大小写和下划线、括号等符号进行编码。将这套字符集映射到0X00~0X7F二进制码的过程就称为基础ASCII编码,通过这个编码过程,计算机就将人类的语言转化为自己的语言存储了起来,反之从磁盘中读取二级制数并转化为字母数字等字符以供显示的过程就是解码了。
随着计算机被迅速推广使用,欧洲的非英语国家的人们发现这套由美国人设计的字符集不够用了,比如一些带重音的字符、希腊字母等都不在这个字符集中,于是扩充了ASCII编码规则,将原本为0的最高位改为1,因此扩展出了10000000~11111111(0X80~0XFF)这128个二进制数。
因为计算机计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。所以才要有编码的存在。
最早的计算机在设计时采用8个比特(bit)作为一个字节,所以,一个字节能表示的最大的整数就是256(二进制11111111=十进制255),如果要表示更大的整数,就必须更多的字节。比如两个字节可以表示的最大整数时65535,4个字节可以表示的最大整数时4294967295。
ASCII编码:
由于计算机是美国人发明的,因此,最早只有127个字符被编进计算机里,也就是大小写英文字母、数字和一些符号,这个编码被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。(这是十进制对应的ASCII码,如下图)
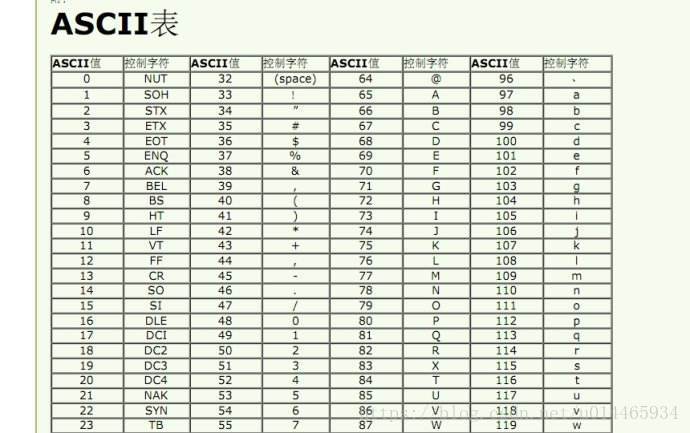
二进制/十进制对应的ASCII码:
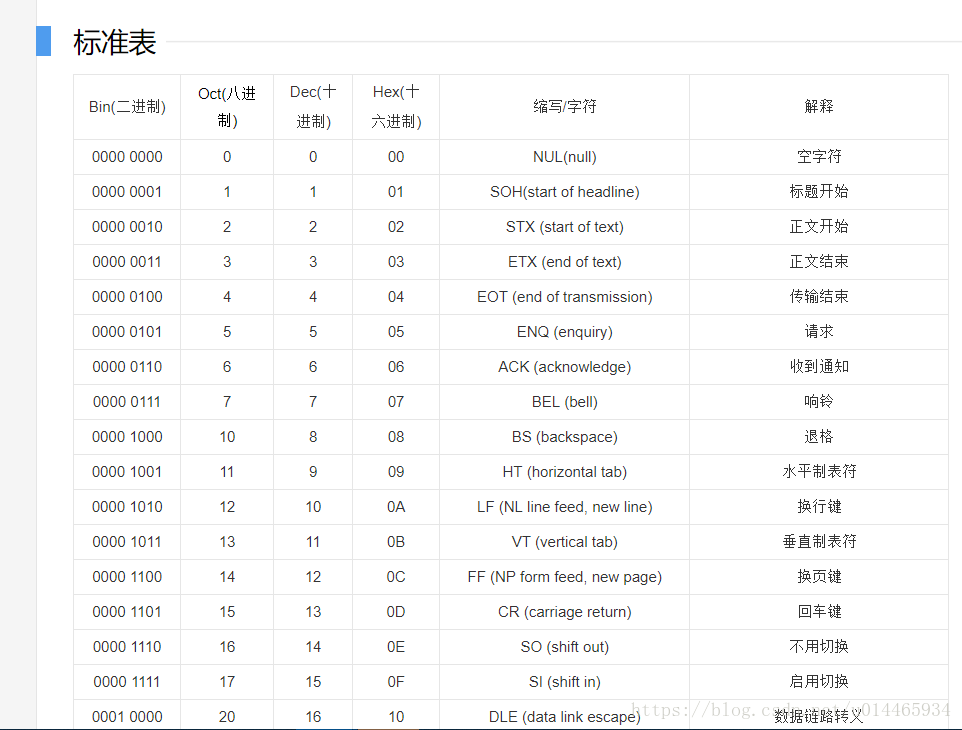
GB系列:
中国国家标准总局发布了一套《信息交换用汉字编码字符集》的国家标准,其标准号就是GB2312-1980,再后来生僻字、繁体字及日韩字也被纳入字符集,就又有了后来的GBK字符集及相应的编码规范,GBK编码规范也是向下兼容GBK2312的。
Unicode:
为了实现跨语言、跨平台的文本转换和处理需求,ISO国际标准化组织提出了Unicode的新标准,这套标准中包含了Unicode字符集和一套编码规范。Unicode字符集涵盖了世界上所有的文字和符号字符,Unicode编码方案为字符集中的每一个字符指定了统一且唯一的二进制编码,这就能彻底解决之前不同编码系统的冲突和乱码问题。
UTF-8、UTF-16编码:
既然提到了Unicode编码,那么常常与之相伴的UTF-8,UTF-16编码方案又是什么?
其实到目前为止我们都一致混淆了两个概念,即字符代码和字符编码,字符代码是特定字符在某个字符集中的序号,而字符编码是在传输、存储过程当中用于表示字符的以字节为单位的二进制序列。ASCII编码系统中,字符代码和字符编码是一致的,比如字符A,在ASCII字符集中的序号,也就是所谓的字符代码是65,存储在磁盘中的二进制比特序列是01000001(0X41,十进制也是65)。
另外的,如在GB2312编码系统中字符代码和字符编码的值也是一致的,所以无形之中我们就忽略了二者的差异性。
而在Unicode标准中,我们目前使用的是UCS-4,即字符集中每一个字符的字符代码都是用4个字节来表示,其中字符代码0~127兼容ASCII字符集,一般的通用汉字的字符代码也都集中在65535之前,使用大于65535的字符代码,即需要超过两个字节来表示的字符代码是比较少的。因此,如果仍然依旧采用字符代码和字符编码相一致的编码方式,那么英语字母、数字原本仅需一个字节编码,目前就需要4个字节进行编码,汉字原本仅需两个字节进行编码,目前也需要4个字节进行编码,这对于存储或传输资源而言是很不划算的。
因此就需要在字符代码和字符编码间进行再编码,这样就引出了UTF-8、UTF-16等编码方式。基于上述需求,UTF-8就是针对位于不同范围的字符代码转化成不同长度的字符编码,同时这种编码方式是以字节为单位,并且完全兼容ASCII编码,即0X00-0X7F的字符代码和字符编码完全一致,也是用一个字节来编码ASCII字符集,而常用汉字在Unicode中的字符代码是4E00-9FA5,在文末的对应关系中我们看到是用三个字节来进行汉字字符的编码。UTF-16同理,就是以16位二进制数为基本单位对Unicode字符集中的字符代码进行再编码,原理和UTF-8一致。因此,我们可以看出,在目前全球互联的大背景下,Unicode字符集和编码方式解决了跨语言、跨平台的交流问题,同时UTF-8等编码方式又有效的节约了存储空间和传输带宽,因而受到了极大的推广应用。

在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
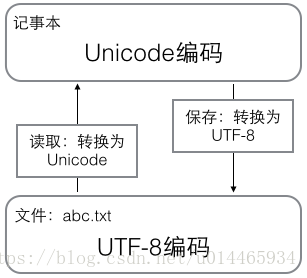
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
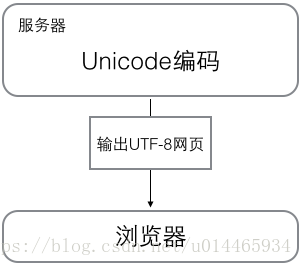
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
Python中的编码:
在python2中字节类型同字符类型区分不大,但是在python3中最重要的特性是对文本和二进制数据做了更加清晰的区分,文本总是Unicode,由字符类型表示,而二进制数据则由byte类型表示,python3不会以任意隐式方式混用字节型和字符型,也因此在python3中不能拼接字符串和字节包(python2中可以,会自动进行转换),也不能在字节包中搜索字符串,也不能将字符串传入参数为字节包的函数。
需要注意的是,在网络数据传输过程中,python2可以通过字符串(string)方式传输,但是python3只能通过二进制(bytes)方式来传输,因此要对传输文本进行转换。
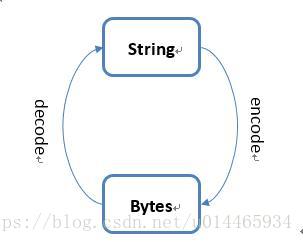
例如下面的例子:
>>>'你好'.encode('utf-8')
b'\xe4\xbd\xa0\xe5\xa5\xbd'
>>> b'\xe4\xbd\xa0\xe5\xa5\xbd'.decode('utf-8')
'你好'
>>>'你好'.encode('utf-8').decode('utf-8')
'你好'其中:
1.encode()和decode()方法中默认了编码为utf-8,但是为了避免错误,最好将编码加上。
2.encode()出来的结果的“b”代表二进制(binary)
廖雪峰Python教程字符串编码摘抄
1.在最新的Python3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言。例如:
print('包含中文的str')
包含中文的str2.对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应得字符:
ord('A')
65
ord('中')
20013
char(66)
'B'
char(25991)
'文'如果知道字符的整数编码,还可以用十六进制这么写str:
'\u4e2d\u6587'
'中文'3.由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存在磁盘上,就需要把str变为以字节为单位的bytes。
python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'要注意区分’ABC’和b’ABC’,前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)注:纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'如果bytes中包含无法解码的字节,decode()方法会报错:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8')
Traceback (most recent call last):
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 3: invalid start byte如果bytes中只有一小部分无效的字节,可以传入errors=’ignore’忽略错误的字节:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore')
'中'4.要计算str包含多少个字符,可以用len()函数:
>>> len('ABC')
3
>>> len('中文')
2len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
5.由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:
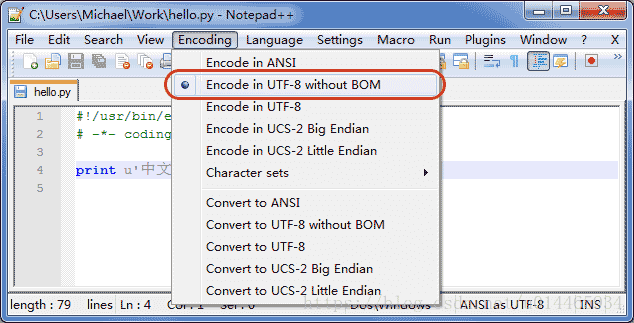
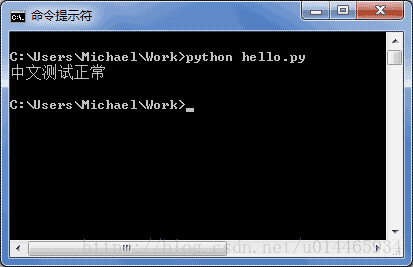
如果.py文件本身使用UTF-8编码,并且也申明了# -- coding: utf-8 --,打开命令提示符测试就可以正常显示中文:(使用UTF-8编码就是写入时使用UTF-8,声明就是说读入时使用UTF-8编码)
参考文章:
https://www.zhihu.com/question/57461614/answer/274634720
https://blog.csdn.net/wangdaiyin/article/details/78006517
https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001431664106267f12e9bef7ee14cf6a8776a479bdec9b9000
https://blog.csdn.net/emma__wang/article/details/79183679