人们时常把索引比作是书本的目录,是一种用来提高数据库查询效率的方法,通过在指定字段上创建索引来提高查询效率;那么为什么使用索引可以提高效率,以及如何添加,删除和查询索引,查询创建的索引是否真正起作用,注意事项等,一一说明:
索引的定义:对数据库中某一列或者多列(创建索引时指定)中的值进行排序并与表中结构一一映射的数据结构;索引生成的具体数据结构,有可能各不相同;这属于索引的具体实现;不在此做讨论,具体类型查看将会在之后说到;
索引的高效率主要体现在两点;
1)数据一般情况都是有顺序的,减少了查询扫描的行数;
2)索引数据结构一般采用各种二叉树的升级版来生成,这样的话查询比较更高效,二分比较法;
B树索引:已B树为数据结构而创建的索引,B树的特点是每个叶子节点到树根节点的距离都是相等的;B树结构如下图;
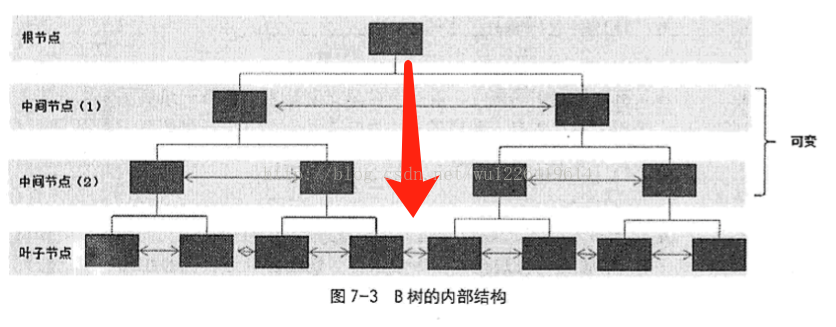
红色箭头表示,根到叶子节点的距离,判断一次距离+1;
索引的创建:
create index 索引名称 on 表名(列名,。。。);//其中列名可以是单一列或者多列;
如表结构如下:
CREATE TABLE IF NOT EXISTS `vip_broadcastor` ( `id` int NOT NULL AUTO_INCREMENT, `employ_id` char(32) NULL COMMENT '关联的员工信息表id', `code` VARCHAR(50) NULL COMMENT '播主编码', `room_id` int NULL COMMENT '播间ID', `online_time` int NULL CoMMENT '在线时长', `created_time` datetime DEFAULT NULL COMMENT '创建时间', `creator_id` char(32) NULL COMMENT '创建人customerId', `status` tinyint(4) DEFAULT '0' COMMENT '是否启用,停用(0--启用,1--停用)', `modify_time` datetime DEFAULT NULL COMMENT '修改时间', `notes` VARCHAR(150) NULL COMMENT '一句话简介', `introduction` VARCHAR(500) NULL COMMENT '备注', `type` int DEFAULT 0 COMMENT '用户类型(0--分析师,1--主持人,2--嘉宾)', `orders` int NULL COMMENT '排序', `big_photo` VARCHAR(150) NULL COMMENT '大图,分析师的小图在employee中存储', PRIMARY KEY (`id`) );
对该表做查询如下:
select * from vip_broadcastor where employ_id ='D0290BB581054CE7A94404E807BA3CC0';
如果没有索引,该查询执行全表扫描,可以通过explain语句查询执行过程展示;
EXPLAIN select * from vip_broadcastor where employ_id='D0290BB581054CE7A94404E807BA3CC0';
如下图:
从图中的rows中可以看出共计扫描22行,是因为我表中只有22行数据;
如果要给employ_id创建索引,则语句如下:
create index v_b_e on vip_broadcastor(employ_id);
之后再次执行上述查询语句并展示具体结果如下:
EXPLAIN select * from vip_broadcastor where employ_id='D0290BB581054CE7A94404E807BA3CC0';
从结果图中可以看出该次查询执行的行数rows为2行,效率提高了10倍多;
上述展示了索引的创建,以及查询所走的索引(possible_keys,key)和查询所走的列数(rows);
索引的维护:
查询当前表中全部的索引:
show index from vip_broadcastor;
结果如下图:

从结果图中可以看出当前表中索引数为2,包括主键索引数据库自动创建和手动创建v_b_e索引,其中Column_name 表示了索引创建的列,而index_type表示了索引底层实现的数据结构;
删除索引:
既然创建了索引,就应该去删除掉已经不再使用的索引:
命令如下:
drop index 索引名称 on 索引所在表名;
如删除前期创建的索引:drop index v_b_e on vip_broadcastor;
索引失效的场合总结:
索引创建了,但是不一定生效,有些查询语句会使得索引失效;常用的主要包括如下几种:
1)使用like%模糊查询的时候,包括‘%aaa’和‘%aaa%’,则不会走索引,但是‘aaa%’可以走索引;
2)查询语句中使用了is not null 或者 <>不等于比较运算符也会导致索引失效;
3)对索引列使用了运算/函数的场合使得索引失效;如year(create_time)='2017';
4) 如果索引为复合索引,如果创建索引的第一列没有保护在where条件语句中,则查询不会走索引;
只要查询中包含了索引的列,或者复合索引中的第一列,并且不在上述四种情况,则查询会走索引,
比方查询如下语句:
EXPLAIN select * from vip_broadcastor where employ_id ='67930DFA68B94CA88A54C415224AE23E' and room_id='27';
展示结果如下图:

从结果图中可以看出,查询确实走了索引;
另外:普通索引中存储的是排序后的与数据表中数据一一对应的指针数组,即索引的叶子节点中保存了当前记录在数据库表中的具体位置信息;通过索引
可以定位到数据信息。而丛生索引:随数据库创建而生成的主键索引,其叶子节点中存储的就是数据本身,而不是指针,所以对于查询来说;
通过主键查询一定是最快的,比通过其他索引,而通过其他普通索引的查询效率要高于全表扫描的自然查询;
总结:索引的创建也许由数据库维护人员而来,但是业务的查询效率,确实一个开发人员必须要关心的,而你的查询语句是否缺一个索引,或者是你的查询
有没有走自己本应该走的索引来提高效率,我们可以通过自己来搞定,而不是询问其他相关人员。