Mycat 学习小结
Mycat 是什么
Mycat 是一个彻底开源的面向企业应用开发的大数据库集群,支持事务,ACID,是可以替代Mysql 的加强版数据库 。Mycat被视为 Mysql 集群的企业级数据库,用来替代昂贵的 Oracle 集群。它是融合了内存缓存技术、HDFS大数据的新型SQL server,是结合了传统数据库和新型分布式数据仓库的新一代企业级数据库产品,是一个数据库中间件。
为什么需要分布式数据库
- 透明性:用户不关心数据的逻辑分区和对应物理位置,即对应用的透明性
- 数据冗余性: 分布式节点存在冗余数据,提高可靠性
- 易于拓展:能够方便的通过水平/垂直拓展提高系统整体性能
- 自治性:各节点的数据由本地DBMS管理
Mycat类似产品
- Amoeba:一个以Mysql为底层数据存储,对应用提供Mysql 协议接口的Proxy。
- Cobar:阿里对Amoeba的改进版,存在一些问题,从2013停止维护
- Heisenberg:也源于Cobar
- Atlas :360团队研发的数据库中间件,也是基于Mysql协议,但用户少
- Mango:轻量级急速数据层访问框架
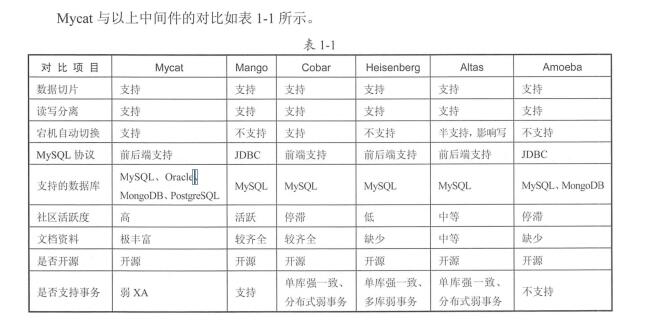
Mycat的优势 可以从上图看出来如下
- 高可用性与Mysql读写分离 :当数据库服务器宕机,如果设置了writehost备用服务器,则会自动切换。高可用性也是建立在底层数据库的主从备份功能的开启;而对于读写分离,也是十分灵活,可以保证 增删改 以及建立存储过程在 主写数据库服务器,而根据(balance参数的设置)可以指定读请求到底发往那个(读 or 写)服务器,例如要求刚插入数据就要被查出来的时候,可以指定读请求发往刚刚写入数据的写服务器,来满足特殊需求。
- 业务数据分级存储:可以将不同重要等级的数据 存储在不同类型的数据库(oracle,mysql,mongodb)
- 支持水平和垂直分片
- 数据库路由器:基于Mysql实例的连接池复用机制,可以让每个应用共享一个Mysql实例的所有连接池
- 支持缓存配置(不用去数据库缓存,中间件缓存,支持ehcache,mapdb,leveldb)
- 前后端使用了AIO/NIO技术
- 使用ER分表策略
Mycat关键名词
- 逻辑库:应用看到的数据库是一个整体的数据库
- 逻辑表:类似于逻辑库的概念,应用所看到的表对象
- 分片表:经过切分的表
- 非分片表
- ER表 :子表的记录与其所关联的父表的记录存放在同一个数据分片上,避免跨库查询
- 全局表:每个数据节点都有的字典表,一般表中数据量不大,也很少修改
- 分片节点(dataNode):表分片后所在的数据库
- 节点主机(dataHost):分片节点最后物理上的位置信息
Mycat学习过程中的几个记录
- 在实现分库分表的情况下,数据库自增主键如何保证是全局唯一的,Mycat提供了两种解决思路:(1)本地文件方式:即本地记录Id的增减情况,速度快,但会从在宕机后重启,ID又会从配置文件的初始值重新开始
,即出现重复(2)数据库方式记录主键自增情况 - Mycat 分片规则十分灵活,足足有十几种,(相比Mongdb的分片规则,没法指定分片规则)
- Mycat把自己包装成 Mysql的服务器端,可以通过Mysql命令行登录方式(9066管理端口)进行登录管理
- Mycat 控制后台数据库 读写分离 和 负载均衡 由 balance属性决定,但是需要注意的是需要底层数据库 开启主从复制
- Mycat 主从切换,是通过心跳反应监听,自动切换,需要注意的是readHost是从属于writeHost,一旦writeHost故障,对应readHost也会失效。而且原来主写节点失效了,恢复上线后,会作为备用写节点工作
- Mycat 中的注解机制十分有意思(1)通过balance 注解指定负载均衡(2)通过master/slave注解指定语句在主/从哪个服务器上执行(3)SQL注解更加强大,通过注解语句指定在哪台具体机子上执行(注解语句中要求含有分片键)(4)schema 和DataNode注解(5)catlet注解用于跨库查询
- Mycat 当前版本的事务是弱XA事务,也就是二阶段提交,一般情况下,和传统式事务性能差不多
- Mycat 跨库Join的实现(1)全局表(每个节点都有数据备份)(2)E-R分片(3)catlet-HBT:自己去自定义查询细节(4)shareJoIn:(两表连接的一个查询策略)
Mycat总结
Mycat是一个很好的中间件,对应用隐藏了分布式数据库的细节,但是也存在着一些弊端
- Mycat文档中要求我们尽量能不分片就不分片,1000万以内的表,不建议分片,通过合适的索引,读写分离等方式,可以很好的解决性能问题
- 分片数量尽量少,分片尽量均匀分布在多个DataHost上,因为一个查询SQL跨分片越多,则总体性能越差,虽然要好于所有数据在一个分片的结果,只在必要的时候进行扩容,增加分片数量
- 分片规则需要慎重选择,分片规则的选择,需要考虑数据的增长模式,数据的访问模式,分片关联性问题,以及分片扩容问题,最近的分片策略为范围分片,枚举分片,一致性Hash分片,这几种分片都有利于扩容
- 批量插入时,如果根据分片键发送到太多个分片,性能也会下降,比如10个分片(分片函数为%10)
- 对于如何分库分表,需要架构师对于业务十分熟悉,根据业务来具体对待问题。
- 非分片字段查询查询问题,如果Mycat不知道往哪个分片上发送查询,就会往所有分片上发送,性能下降,所以建议查询语句条件中包含分片键!
- 分页排序问题:当table表有多个分片时,语句为select * from table limit 2;返回结果依赖于每个分片的数据包达到顺序,所以不确定;当语句为select * from table order by id limit m,n;MYCAT内部为了保证数据的查询正确性,会将语句改写为select * from table order by id limit 0,m+n,可以看出当m,n很大时,在每个节点执行的话,对性能影响之大,具体参考http://blog.csdn.net/u013235478/article/details/53178657这篇博客。