mycat学习:
官网:http://www.mycat.io/
介绍:
mycat 是一个开源分布式数据库中间件,主要解决的问题:

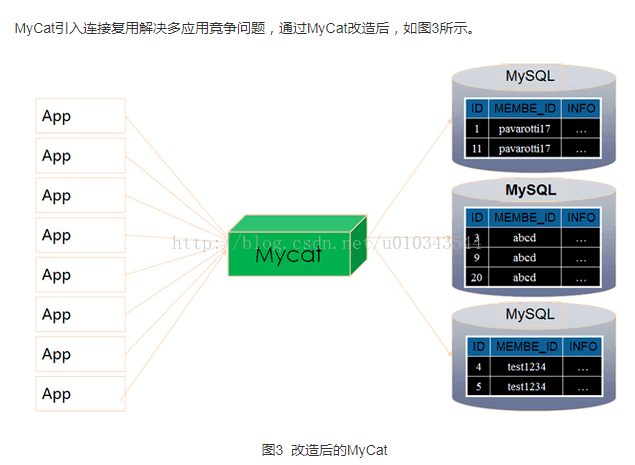
简单来说,就是分库分表的问题。mycat 相当于是一个虚拟的数据库,表面上看起来是一个数据库,实际是连接了多个数据库。
原来单库的情况下,如果要分库,配置好 mycat 之后,只需要简单修改代码的数据库连接源即可。
另外,navicat 连接数据库的工具,也可以直接连接 mycat 进行数据库的增删改查。

安装
1、下载MyCat https://github.com/MyCATApache/Mycat-download 选择合适的版本下载
2、安装JDK 需要1.7 或者以上版本 http://blog.csdn.net/linlinv3/article/details/45060705
3、解压 tar -zxvf Mycat-server-1.5.1-RELEASE-20160622153300-linux.tar.gz
其中JDK存放地址为:/home/lin/soft/jdk1.7.0_79
MyCat存放地址为:/home/lin/soft/mycat
存放地址根据个人习惯自己放。
修改配置文件:mycat/conf/wrapper.conf
wrapper.java.command=/home/lin/soft/jdk1.7.0_79/bin/javaexport MYCAT_HOME=/home/lin/soft/mycat启动mycat:
到 mycat 的 bin 目录下 :cd mycat/bin/
以下是启动停止等 mycat 的 linux 命令:
./mycat start 启动
./mycat stop 停止
./mycat console 前台运行
./mycat restart 重启服务
./mycat pause 暂停
./mycat status 查看启动状态
mycat 的日志路径:mycat/logs/wrapper.log
安装成功之后,需要以下配置 mycat 的配置文件后,可以连接多个数据库。
配置
schema.xml的配置
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100">
<!-- auto sharding by id (long) -->
<table name="tb_day_dividendhold" dataNode="match_db0,match_db1" rule="rule_firm_account" />
<table name="tb_day_entrust" dataNode="match_db0,match_db1" rule="rule_firm_account" />
<table name="tb_day_hold" dataNode="match_db0,match_db1" rule="rule_firm_account" />
<table name="tb_day_transaction" dataNode="match_db0,match_db1" rule="rule_firm_account" />
<table name="tb_history_entrust" dataNode="match_db0,match_db1" rule="rule_firm_account" />
<table name="tb_history_hold" dataNode="match_db0,match_db1" rule="rule_firm_account" />
<table name="tb_history_transaction" dataNode="match_db0,match_db1" rule="rule_firm_account" />
<table name="tb_transactionNo" dataNode="match_db0,match_db1" rule="rule_firm_account" />
</schema>
<!-- database是数据库的schema -->
<dataNode name="match_db0" dataHost="localhost1" database="match_db" />
<dataNode name="match_db1" dataHost="localhost1" database="match_db1" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat> </heartbeat>
<!-- can have multi write hosts 只是指明IP地址 -->
<writeHost host="hostM1" url="10.20.135.32:3306" user="root"
password="hundsun">
</writeHost>
</dataHost>
</mycat:schema>说明:我们数据库的 ip 是10.20.135.32:3306,服务下面的数据库有 match_db 和 match_db1 两个
dataNode 是配置数据库的
dataHost 是配置服务器的,所以只需要 ip 和端口
schema 是配置数据库中的表,怎么路由到数据库的,其中 rule 是路由的规则,在 rule.xml 中进行配置
schema 的 name 是 mycat 提供出去的数据库的名称,另外,mycat 提供出去的端口是 8066
checkSQLschema 必须是 true ,下面的路由规则才有效
主要的就这些,具体的规则,参考上面的参考文章的连接,很具体的。
rule.xml 的配置
由于我们项目使用的是枚举的规则,所以只介绍枚举的规则
其他的分片规则可参考:http://www.cnblogs.com/756623607-zhang/p/6656022.html 往下拉一点,有常用的分片规则:总共十个(基本够用)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="rule_firm_account">
<rule>
<columns>firm_account</columns>
<algorithm>func_firmaccount</algorithm>
</rule>
</tableRule>
<!-- 根据firm_account字段拆分撮合库 -->
<function name="func_firmaccount" class="io.mycat.route.function.PartitionByFileMap">
<!-- 枚举文档 -->
<property name="mapFile">sharding-by-enum.txt</property>
<!-- type默认值为0,0表示Integer,非零表示String -->
<property name="type">1</property>
<!-- defaultNode 默认节点:小于0表示不设置默认节点,大于等于0表示设置默认节点,结点为指定的值 -->
<property name="defaultNode">-1</property>
</function>
</mycat:rule>sharding-by-enum.txt配置:
0=0
1=1
# 第一个0表示firm_account的取值,后一个0表示index=0的配置的match_db0配置后的结果是配置的表,根据字段firm_account来分库
firm_account=0,是取index=0的配置的match_db0
firm_account=1,是取index=1的配置的match_db1
这里的 index 的顺序就是 schema.xml 文件中的 scema 节点下,table 节点里的 dataNode 的配置顺序
server.xml
mycat 提供出去的端口,默认是 8066
mycat 的用户信息,也在这里配置
以下为参考:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="sequnceHandlerType">2</property>
<property name="processorBufferPoolType">0</property>
<property name="handleDistributedTransactions">0</property>
<!--
off heap for merge/order/group/limit 1开启 0关闭
-->
<property name="useOffHeapForMerge">1</property>
<!--
单位为m
-->
<property name="memoryPageSize">1m</property>
<!--
单位为k
-->
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<!--
单位为m
-->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">true</property>
</system>
<user name="root">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
最后,参考一下我们项目的数据源配置:
jdbc.url=jdbc:mysql://10.20.135.32:8066/TESTDB?autoReconnect=true&allowMultiQueries=true
jdbc.username=root
jdbc.password=123456
jdbc.driverClass=com.mysql.jdbc.Driver