6、图的秘密
导航图的每一个节点通常表示一个区域位置或对象,一个边有一个开销,代表了节点间的距离,这样的图叫做欧几里得图
角色扮演游戏常用基于单元网格设计导航图,每一个单元代表一种不同的地形,如草地、公路,根据不同地形单元格的权重也不同,这样计算出的路径会尽量走公路而不是泥地。
比如一个秘密行动游戏,他的边的权值由角色在其上发出的声音决定,比如沿着地毯的边的权值较小,沿着地板的边权值较大,这样计算的路径是两个房间之间最安静的路径。
一、深度优先搜索(Depth First Search)DFS
DFS用堆栈实现搜索算法
二、DFS优化:一些图可能比较深,DFS很容易在错误路径上陷得很深,甚至永久被卡住,通过限制的搜索深度可以防止这种情况发生,这叫做限制深度的搜索。
限制深度搜索的缺点:如果设置搜索深度为10,算法可能找不到一个解决方案,如果深度设置太高,可能卡死。
DFS的第二种优化:迭代加深深度优先搜索,它是广度优先搜索的基础,先把搜索深度设为1,再设为2,再设为3,然后不断进行下去直到搜索完成。
当然也可以给迭代加深深度优先搜索设置的截止点为一个时间限制,当时间用完时,算法会终止,无论已经搜索到一个怎样的深度。
三、广度优先搜索(Breadth First Search)BFS:
算法使用一个先进先出的队列

算法思想:
从节点5开始,因为节点5的边连接的点仍然是自己,该边出队,所有节点5的相邻边被加入队列中,也即5-6,5-4,5-2入队
然后5-6出队,6的邻边节点都访问过,所以邻边没有加入队列
接着5-4出队,4-3入队
5-2出队,2-1入队
。。。
缺点:如果搜索图非常大且分支很高,那么BFS会浪费大量内存,效率很低
问:非递归形式的深度优先搜索为何要用栈,而广度优先却使用了队列?
因为深度优先需要无路可走时按照来路往回退,正好是后进先出,
广度优先则需要保证先访问顶点的未访问邻接点先访问,恰好就是先进先出
四、基于开销的图搜索
最短路径树:给出一个图和一个源节点,最短路径数(short path tree)SPT是图G的一颗子树,代表了源节点到任意节点的最短路径
迪杰斯特拉算法(Dijkstra Algorithm):该算法每一次构造最短路径树的一条边。这个算法过程的最后得到的SPT将包含图中每一个节点到起点的最短路径。如果算法提供一个目标点,那么找到目标点就终止。算法终止时,生成的SPT包含从起点到终点的最短路径,也会包含到达每一个节点的最短路径
该算法使用队列来实现
迪杰斯特拉算法缺点;和BFS一样,该算法也在起点周围检查了太多的边,如果在搜索中能得到提示,就能促使沿正确的方向前行。
如果估计一下该点距离目标点的开销,将这个信息考虑进去,该算法效率大大提升,这个估计值叫做启发因子,这种启发搜索算法叫做A*算法
A*算法:和迪杰斯特拉算法几乎一样,唯一区别是对搜索边界的点的开销进行计算,F是开销,G是到达一个点的累计开销,H是启发因子,给出节点到目标节点的估计距离,因此 F=G+H。
伪代码:开销Cost=E(到达E点的累计开销)+E.Cost(该点的开销)+CostToTarget(到达目标点的开销)
通过启发因子H,被修正的开销会指引搜索逼近目标点,而不是在各个方向上发散搜索,因此,搜索的加速是迪杰斯特拉和A*的主要区别。
注意:如果在A*算法中将启发因子值设为0,那么搜索结果和Dijikstra算法一样。
A*算法的优化:
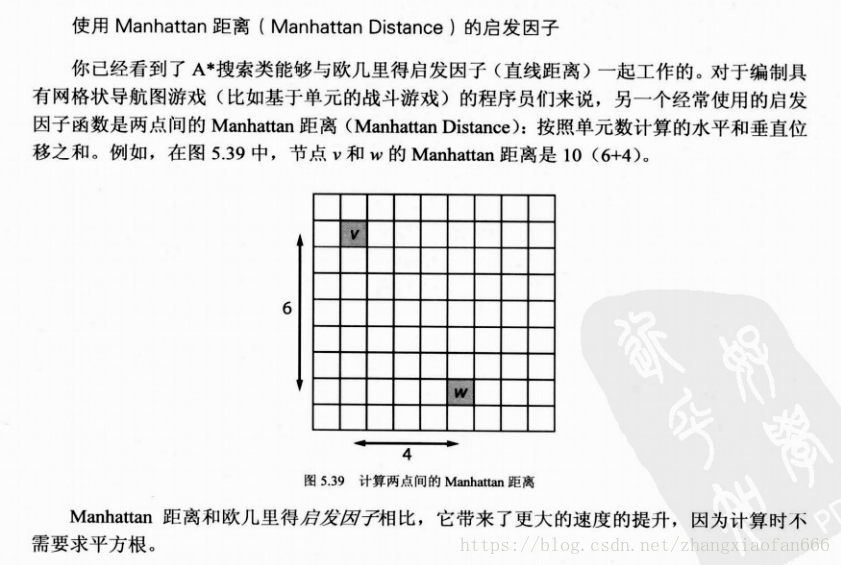
对于路径规划如果时间复杂度为n的平方,每次节点数目加倍,搜索花费的时间会增加4倍,可以使用空间分割技术得到提高,对于超过几百个节点的导航图,空间分割能使搜索极大的提高
如果你的游戏环境是静态的,一个减轻cpu负载的好方法是使用预先计算好的查询表,这样就可以非常快的确定路径,利用迪杰斯特拉算法为图中每个节点创建最短路径树SPT,它以目标节点为根,包含到达每个节点的最短路径,这些信息提取出来,存储在一个二维数组中
七、AI
消耗CPU的优化:


