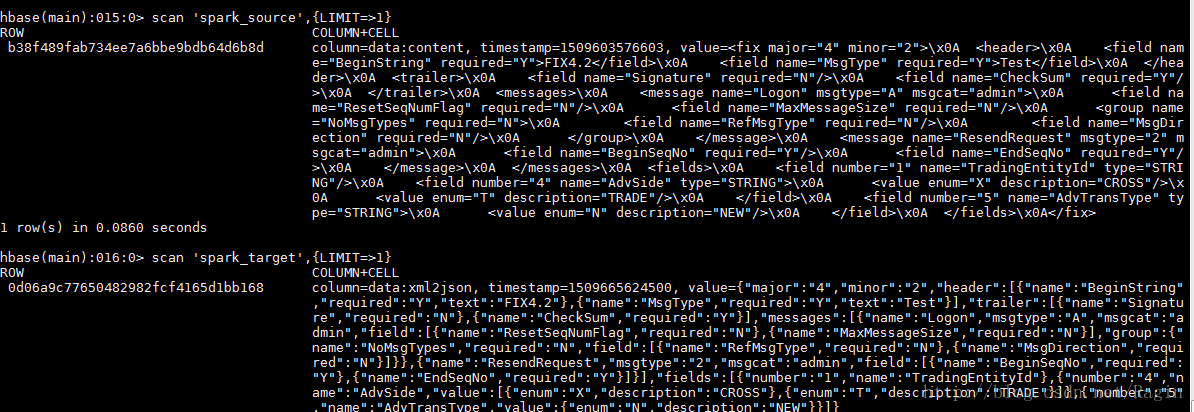
刚学习spark和scala, 写了个小demo练习。
功能:spark从hbase中读取xml字符串数据,解析成json后写回到hbase中
因为刚入门,所以还未研究spark streaming用法。所以以下代码就用最简单的spark直接操作hbase。
pom文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.syher</groupId>
<artifactId>spark</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<inceptionYear>2008</inceptionYear>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<properties>
<scala.version>2.7.0</scala.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/net.sf.json-lib/json-lib -->
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.4</version>
<classifier>jdk15</classifier>
</dependency>
<dependency>
<groupId>xom</groupId>
<artifactId>xom</artifactId>
<version>1.1</version>
<scope>compile</scope>
<optional>true</optional>
</dependency>
</dependencies>
<!-- 不加这段, ImmutableBytesWritable序列化会出问题-->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>xerces</groupId>
<artifactId>xercesImpl</artifactId>
<version>2.11.0</version>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>Batch</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
</project>
xml2json.scala
package com.syher
import java.util.UUID
import com.tool.{HBaseTool, Xml2Json, XmlTool}
import net.sf.json.xml.XMLSerializer
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapred.TableOutputFormat
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapred.JobConf
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by shenyuhang on 2017/11/6.
*/
object HBaseDemo {
def main(args: Array[String]) {
xml2json
}
def xml2json(): Unit = {
val sparkConf = new SparkConf().setAppName("HBaseDemo").setMaster("local")
val sparkContext = new SparkContext(sparkConf)
var conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "master1")
conf.set("hbase.zookeeper.property.clientPort", "2181")
//读取数据RDD
conf.set(TableInputFormat.INPUT_TABLE, "spark_source")
var hbaseRDD = sparkContext.newAPIHadoopRDD(conf, classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
// 检查hbase是否存在,不存在就创建
//代码略。
//设置写入job
val jobConf = new JobConf(conf)
jobConf.setOutputFormat(classOf[TableOutputFormat])
jobConf.set(TableOutputFormat.OUTPUT_TABLE, "spark_target")
//数据处理
hbaseRDD.map { item =>
var kvs = item._2.raw
var data = kvs.map(kv => {
new XMLSerializer().read(new String(kv.getValue)).toString().replaceAll("[#@]", "")
})
data(0)
}.map { str =>
val put = new Put(Bytes.toBytes(UUID.randomUUID().toString.replace("-", "")))
put.add(Bytes.toBytes("data"), Bytes.toBytes("xml2json"), Bytes.toBytes(str))
(new ImmutableBytesWritable, put)
}.saveAsHadoopDataset(jobConf)
}
}
运行结果: