序言:
1、不同编程语言读写文件的操作步骤基本上是一致,大致可以分为以下几个步骤:
(1)打开文件,获取文件描述符
(2)针对操作文件描述符进行操作——读/写
(3)关闭文件
2、值得注意的是,读写文件操作完成以后,要及时关闭(和查询数据库链接是一致),虽然当前计算机,即便你不关闭也会产生死机,但是及时关闭链接,是一个好习惯,原因分析一下:
- 文件对象会占据操作系统的资源,你不关闭,那么会出现卡顿(当然对于目前计算机来说,不会明显)
- 操作系统对同一时间能打开的文件描述符的数量是有限制的(也就是你同时打开文件的数量是有限制的)
- 如果不及时关闭文件,还可能会造成数据丢失,因为我们吧数据写入文件时,操作系统不会立刻吧数据写入磁盘,而是先把数据放到内存缓冲区,异步写入磁盘,当你关闭链接的时候,操作系统会保证把没有写入磁盘的数据全部写入到磁盘中,否则可能会丢失数据
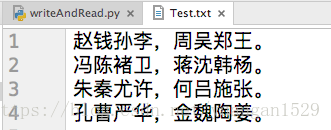
3、文本内容是:
赵钱孙李,周吴郑王。
冯陈褚卫,蒋沈韩杨。
朱秦尤许,何吕施张。
孔曹严华,金魏陶姜。
一、读写模型
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)上面写的代码,是一个打开文件的大致函数模型,open是用来打开文件的,里面有很多参数,当然我们自己写代码的时候,很多参数是没有必要写的(一般都是些前面两个参数)。
上面最重要的参数只有前两个:第一个file(指定了文件路径,其实就是一个字符串);第二个mode(模型,分为只读,只写,可读可写,,,,,,)

上面的框框是所有mode形式,一般情况下,都是直接用前面两种形式就可以了(r和w),要注意的是:
- 用w模式写的时候,会将原文本内容清空,如果你想在原文本末尾写入内容,就要用a模式
- r+会覆盖原来的内容,比如你原来的文件内容是“你好啊,朋友!”,写入“上帝”后,就会变成“上帝啊,朋友!”,用上帝覆盖住了你好
- a+增加了可读性,但是其写入内容的时候,不管你的文件指针在哪里都会在文本末尾写入
1、简单读写框架
(1)读写流程
知道了模型框架,那我们就先读一个文件:
# 第一步:(以只读模式)打开文件
f = open('song.txt', 'r', encoding='utf-8')
# 第二步:读取文件内容
print(f.read()) #将读取的文件内容打印出来,这里输出的格式和原文件内容格式一模一样(无论是换行还是空格)
# 第三步:关闭文件
f.close()注意:这里open打开之后,读取文件,直接就转换成了Unicode字符串,这里的read()方法,会一次性将文件中所有的内容全部加载到内存中,这对于大部分情况是不合理的,比如一个文件非常大,我们一次性读取出来,就会把内存全部占满,那就没有什么意义了,下面介绍几种读文件的方式:

上面介绍了几乎所有的读文件方法,还有两个与文件指针位置相关的方法:
- seek(n)————将文件指针移动到指定字节的位置,具体函数可参看:seek用法
- tell()————获取当前文件指针所在字节位置
(2)try .....finally......(better)
在实现基本功能的前提下,考虑一些可能的意外因素。因为文件读写时都有可能产生IO错误(IOError),一旦出错,后面包括f.close()在内的所有代码都不会执行了。因此我们要保证文件无论如何都能被关闭。那么可以用try...finally来实现,这实际上就是try...except..finally的简化版:
try:
f = open('txt/test.txt', 'r', encoding='utf-8')
print(f.read())
num = 10 / 0
finally: #目的是无论上面有没有错,都要将open关掉
print('>>>>>>finally')
if f: #f为真,表示上面打开了文件,所以下面要关掉
f.close()输出结果:

从上面这个图上可以看出,虽然报了错,但是最终还是输出了:》》》》finally,这就说明最后的代码块被执行了,也就是关闭了f,
(3)with,,,,(best!)
直接上代码实例:
with open('txt/test.txt', 'r', encoding='utf-8') as f: 这里是赋值给f,当with结束以后,自动关闭
print(f.read())
print(f.closed)
可以看到最后输出了true,表示f已经关闭了
为了避免忘记或者为了避免每次都要手动关闭文件,我们可以使用with语句(一种语法糖,语法糖是为了简化某些操作而设计的),with语句会在其代码块执行完毕之后自动关闭文件,就如上面写的一样。
注意:如果with代码块中出现了问题,那么这个问题就会被抛出,需要我们自己处理(会中断代码块的执行),所以建议在必要的时候,在with语句外面套上一层try。。。except来捕获和处理异常:
with open('txt/test.txt', 'r', encoding='utf-8') as f:
print(f.read())
num = 10 / 0 #代码块里面的错误之处结果显示:

对于这个结果,其实我感觉有些疑惑,根据代码应该是先将所有语句输出了,然后再显示错误才对啊,这个问题留作以后再解惑,如果有知道的读者,可以在评论回答一下,绝对重谢。
2、读实例
之前,把所有准备工作都做好了,接下来开始干货了,直接上相关代码实例。
(1)读取指定长度的内容:
with open('txt/test.txt', 'r', encoding='utf-8') as f:
print(f.read(12)) #数字12就是指定长度,与编码方式无关,就是返回12个字符输出:
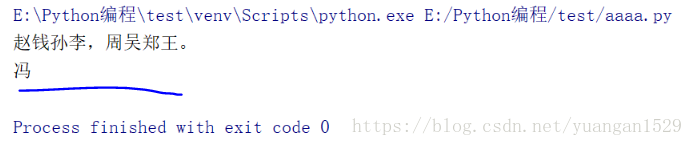
注意:在这里Python2与Python3还是有差别的,Python2中,数字12指的是字节数,这就与编码方式有关了,在一些编码方式中,一个汉字占3个字节,所以在Python2中,会输出4个汉字
(2)读取文件的一行内容:
with open('txt/test.txt', 'r', encoding='utf-8') as f:
print("输出第一行内容:"+f.readline())
print("输出第一行第一个字的内容:" + f.readline(1))输出结果:

好吧,上面显示的结果和我预期有点不一样:我之前以为是输出的也是第一行内容,没想到转到第二行去了,后来才发现,原来文本读取的时候,是有读取位置的,第一行已经读取完毕了,再次读取的时候,不会重新开始读,而是会在原有基础上进行读取。这也就是为什么上面第二个输出会显示“冯”,而不是“赵”;本来想改一下,后来想想算了,当做警醒吧。
(3)遍历文件中的每一行
第一种方法是直接一次性读取所有行到内存,然后遍历打印:
with open('txt/test.txt', 'r', encoding='utf-8') as f:
for line in f.readlines():
print(line)结果显示:

有一个问题:就是每行文档输出之间有一行空白区间,这个问题是因为读取的文件中每一行都默认有换行符,而print()方法也会输出换行,因此两个换行就会多出一个换行符(因为只需要1个就可以了),去掉空行也比较简单:
- line.rstrip()——去除字符串右边的换行符(也就是从文本的角度去除)
- print(line,end = '')————避免print方法造成的换行
输出结果显示:

看,空白行被去除了
第二种方法:通过迭代器一行行读取并打印
with open('txt/test.txt', 'r', encoding='utf-8', newline='') as f:
for line in f: #唯一的区别就在这里,迭代器上一次已经说过了,当你不用的时候,它不会读取,只有用的时候才会读取
print(line,end = '') #这次去除一波换行符显示结果和上面是一样的,同样有一行空白区域
3、文件读取的一些其他方法

4、写实例
原文本内容:
(1)简单的写入文本一句话
#写操作
with open('Test.txt', 'w', encoding='utf-8') as f: #这里定义的是w模式
print(f.write('你好'))上面定义的是最简单写操作,但是注意这里用的是w模式,操作执行的时候,首先会把原来的内容清空,然后在写入,所以原本写有4行百家姓的文本,变成了只有“你好”的文本:

(2)在原有文本后面添加内容
#写操作
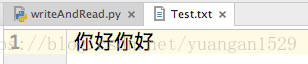
with open('Test.txt', 'a', encoding='utf-8') as f:
print(f.write('你好'))这里以a模式进行写入,结果就在“你好”之后,再次写入了“你好”(因为直接写入以后,没有进行更改,所以文本就不再是百家姓了):
(3)换行写入
第一种方法:从文本最后位置着手
因为a模式是追加在文本最后一行的内容,但是这里的最后一行,你是可以控制的,比如:

比如上面这个Test文本,只有4行,那么最后写入以后,就会在第4行后面添加,同样是上面的代码执行以后:
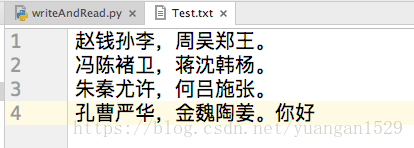
然后,你更改一下文本,让最后一行是空格:

这样,最后的位置就变成了第5行,而第5行是空白字符,如果再次执行上面的代码,你就会发现结果不一样了:
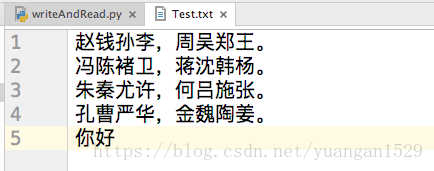
所以通过更改文件“最后位置”可以实现换行输入,这里你要深入理解文本的最后一行是指什么意思
第二种方法:从代码入手(best)
#写操作
with open('Test.txt', 'a', encoding='utf-8') as f:
print(f.write('\n'+'你好')) #直接加入换行符,简单高效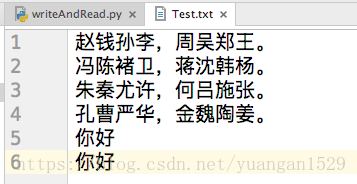
(4)在指定位置插入
#第一种方法:在第一行周前面插入666
with open('Test.txt', 'r', encoding='utf-8') as f:
lines = f.readlines() #读取文件
print("读取的文本:")
print(lines)
lines[0]=lines[0].replace("周","666周") #在第一行字符串里面的周前面加入666
s=''.join(lines)
with open('Test.txt', 'w+', encoding='utf-8') as f:
f.write(s)
del lines[:] #清空列表
print("最后的文本:")
print(lines)上面这种方法是取巧的方法,先将文本读取出来,转换成列表,然后对每一行(字符串形式)进行更改,最关键的字符串的更改那里,可以参考博客:更改字符串内容
上面这种方法的弊端就是,当文件比较大的时候,会很麻烦,当然了如果更改内容比较少(你可以针对某些内容进行修改,读取一部分内容,然后针对这一部分内容进行修改,然后在写回去)
从文中读取指定行的代码读取指定行(很简单)
#第二种方法:插入文本到指定位置
import os
with open("Test.txt","r",encoding="utf-8") as file:
content = file.read()
content_add = "我加在这里了!"
pos = content.find("周")
with open("Test.txt", "w", encoding="utf-8") as f:
if pos != -1:
content = content[:pos] +content_add+content[pos:]
f.write(content)上面这种方法,比第一种方法本质上是一样的,都是直接操作字符串,但是一个是replace操作,一个是连接操作,感觉连接操作更好些一下
(5)读取一个文件的内容,然后写入另一个文件中
with open("Test.txt","r",encoding="utf-8") as file:
content = file.read()
with open("a.txt", "w", encoding="utf-8") as f:
f.write(content)这个就比较简单了,这里不再详细细说了。
5、二进制文件读取
之前默认读取的文件都是文本文件,想要读取或者写入二进制文件,只需要将“r”改成“rb”,其他模式也是这样,只需加入一个b即可。
f = open('EDC.jpg', 'rb')
print(f.read())
# 输出 '\xff\xd8\xff\xe1\x00\x18Exif\x00\x00...' # 十六进制表示的字节大家可以看到,上面输出的一个个字符编码,简单来说,任何非标准的文本文件(对于Python2来说,标准是ASCLL,对于Python3来说,标准是Unicode),你需要用二进制读入这个文件,然后再用.decode('...')的方法来解码这个二进制文件:
f = open('DegangGuo.txt', 'rb')
# 读入郭德纲老师的作文, 但是郭老师用的是参合着错别字的繁体编码,假设叫个"DeyunCode"
# 那么你读入以后,就需要解码它
u = f.read().decode('DeyunCode')主要参考自:Python之文件读写
建议大家还是看看原网页,因为大部分原理性的东西,我没有搞过来,只搞了些使用的东西,当然自己有添加了一些东西