这篇文章主要来源经理问我的一个问题:数据库建立索引为什么会加快查询速度
参考了:https://blog.csdn.net/m0_38128121/article/details/79663261
首先明白为什么索引会增加速度,DB在执行一条Sql语句的时候,默认的方式是根据搜索条件进行全表扫描,遇到匹配条件的就加入搜索结果集合。如果我们对某一字段增加索引,查询时就会先去索引列表中一次定位到特定值的行数,大大减少遍历匹配的行数,所以能明显增加查询的速度。
MySQL官方对于索引的定义为:索引是帮助MySQL高效获取数据的数据结构。即可以理解为:索引是数据结构。
我们知道,数据库查询是数据库最主要的功能之一,我们都希望查询数据的速度尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找,当然这种时间复杂度为O(n)的算法在数据量很大时显然是糟糕的,于是有了二分查找、二叉树查找等。但是二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树,但是数据本身的组织结构不可能完全满足各种数据结构。所以,在数据之外,数据库系统还维护者满足特定查找算法的数据结构,这些数据结构以某种方式引用数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
B-Tree和B+Tree
目前大部分数据库系统及文件系统都采用B-Tree和B+Tree作为索引结构。
索引
索引的目的:提高查询效率
原理:通过不断的缩小想要获得数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是我们总是通过同一种查找方式来锁定数据。
数据结构:B+树
图解B+树与查找过程: 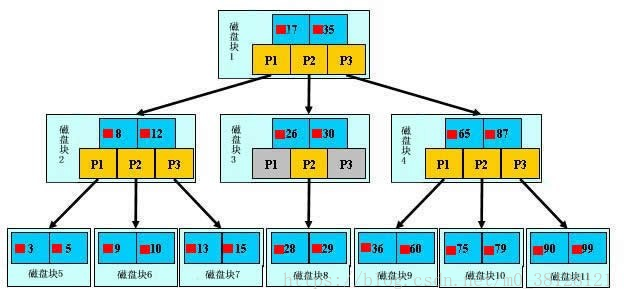
如上图,是一颗b+树,关于b+树的定义可以参见B+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
b+树的查找过程
b+树的查找过程
如图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
b+树性质
通过上面的分析,我们知道IO次数取决于b+数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
添加索引的话,首先去索引列表中查询,而我们的索引列表是B类树的数据结构,查询的时间复杂度为O(log2N),定位到特定值得行就会非常快,所以其查询速度就会非常快。
为什么说B+-tree比B 树更适合实际应用中操作系统的文件索引和数据库索引?
1) B+-tree的磁盘读写代价更低
B+-tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
- 1添加索引的话,首先去索引列表中查询,而我们的索引列表是B类树的数据结构,查询的时间复杂度为O(log2N),定位到特定值得行就会非常快,所以其查询速度就会非常快。
2) B+-tree的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
读者点评
fanyy1991(csdn用户名)道:个人觉得这两个原因都不是主要原因。数据库索引采用B+树的主要原因是 B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
上述那个问题转载自:从B树、B+树、B*树谈到R 树
那么在任何时候都应该加索引么?这里有几个反例:1、如果每次都需要取到所有表记录,无论如何都必须进行全表扫描了,那么是否加索引也没有意义了。2、对非唯一的字段,例如“性别”这种大量重复值的字段,增加索引也没有什么意义。3、对于记录比较少的表,增加索引不会带来速度的优化反而浪费了存储空间,因为索引是需要存储空间的,而且有个致命缺点是对于update/insert/delete的每次执行,字段的索引都必须重新计算更新。
那么在什么时候适合加上索引呢?我们看一个Mysql手册中举的例子,这里有一条sql语句:
SELECT c.companyID, c.companyName FROM Companies c, User u WHERE c.companyID = u.fk_companyID AND c.numEmployees >= 0 AND c.companyName LIKE '%i%' AND u.groupID IN (SELECT g.groupID FROM Groups g WHERE g.groupLabel = 'Executive')
这条语句涉及3个表的联接,并且包括了许多搜索条件比如大小比较,Like匹配等。在没有索引的情况下Mysql需要执行的扫描行数是 77721876行。而我们通过在companyID和groupLabel两个字段上加上索引之后,扫描的行数只需要134行。在Mysql中可以通过 Explain Select来查看扫描次数。可以看出来在这种联表和复杂搜索条件的情况下,索引带来的性能提升远比它所占据的磁盘空间要重要得多。
那么索引是如何实现的呢?大多数DB厂商实现索引都是基于一种数据结构——B树。oracle实现索引的数据结构是B*树。具体关于B树、B+树、B*树的讲解可以查看另一篇博文:树
可以看到在这棵B树搜索英文字母复杂度只为o(m),在数据量比较大的情况下,这样的结构可以大大增加查询速度。然而有另外一种数据结构查询的虚度比B树更快——散列表。Hash表的定义是这样的:设所有可能出现的关键字集合为u,实际发生存储的关键字记为k,而|k|比|u|小很多。散列方法是通过散列函数h将u映射到表T[0,m-1]的下标上,这样u中的关键字为变量,以h为函数运算结果即为相应结点的存储地址。从而达到可以在o(1)的时间内完成查找。
然而散列表有一个缺陷,那就是散列冲突,即两个关键字通过散列函数计算出了相同的结果。设m和n分别表示散列表的长度和填满的结点数,n/m为散列表的填装因子,因子越大,表示散列冲突的机会越大。
因为有这样的缺陷,所以数据库不会使用散列表来做为索引的默认实现,Mysql宣称会根据执行查询格式尝试将基于磁盘的B树索引转变为和合适的散列索引以追求进一步提高搜索速度。我想其它数据库厂商也会有类似的策略,毕竟在数据库战场上,搜索速度和管理安全一样是非常重要的竞争点。
- 那么在任何时候都应该加索引么?这里有几个反例:
- 1、如果每次都需要取到所有表记录,无论如何都必须进行全表扫描了,那么是否加索引也没有意义了。
- 2、对非唯一的字段,例如“性别”这种大量重复值的字段,增加索引也没有什么意义。
- 3、对于记录比较少的表,增加索引不会带来速度的优化反而浪费了存储空间,因为索引是需要存储空间的,而且有个致命缺点是对于update/insert/delete的每次执行,字段的索引都必须重新计算更新。 那么在什么时候适合加上索引呢?我们看一个Mysql手册中举的例子,这里有一条sql语句: SELECT c.companyID, c.companyName FROM Companies c, User u WHERE c.companyID = u.fk_companyID AND c.numEmployees >= 0 AND c.companyName LIKE '%i%' AND u.groupID IN (SELECT g.groupID FROM Groups g WHERE g.groupLabel = 'Executive') 这条语句涉及3个表的联接,并且包括了许多搜索条件比如大小比较,Like匹配等。在没有索引的情况下Mysql需要执行的扫描行数是 77721876行。而我们通过在companyID和groupLabel两个字段上加上索引之后,扫描的行数只需要134行。在Mysql中可以通过 Explain Select来查看扫描次数。可以看出来在这种联表和复杂搜索条件的情况下,索引带来的性能提升远比它所占据的磁盘空间要重要得多。 那么索引是如何实现的呢?大多数DB厂商实现索引都是基于一种数据结构——B树。oracle实现索引的数据结构是B*树。具体关于B树、B+树、B*树的讲解可以查看另一篇博文:树 可以看到在这棵B树搜索英文字母复杂度只为o(m),在数据量比较大的情况下,这样的结构可以大大增加查询速度。然而有另外一种数据结构查询的虚度比B树更快——散列表。Hash表的定义是这样的:设所有可能出现的关键字集合为u,实际发生存储的关键字记为k,而|k|比|u|小很多。散列方法是通过散列函数h将u映射到表T[0,m-1]的下标上,这样u中的关键字为变量,以h为函数运算结果即为相应结点的存储地址。从而达到可以在o(1)的时间内完成查找。 然而散列表有一个缺陷,那就是散列冲突,即两个关键字通过散列函数计算出了相同的结果。设m和n分别表示散列表的长度和填满的结点数,n/m为散列表的填装因子,因子越大,表示散列冲突的机会越大。 因为有这样的缺陷,所以数据库不会使用散列表来做为索引的默认实现,Mysql宣称会根据执行查询格式尝试将基于磁盘的B树索引转变为和合适的散列索引以追求进一步提高搜索速度。我想其它数据库厂商也会有类似的策略,毕竟在数据库战场上,搜索速度和管理安全一样是非常重要的竞争点。
基本概念介绍:
索引
使用索引可快速访问数据库表中的特定信息。索引是对数据库表中一列或多列的值进行排序的一种结构,例如 employee 表的姓(lname)列。如果要按姓查找特定职员,与必须搜索表中的所有行相比,索引会帮助您更快地获得该信息。
索引提供指向存储在表的指定列中的数据值的指针,然后根据您指定的排序顺序对这些指针排序。数据库使用索引的方式与您使用书籍中的索引的方式很相似:它搜索索引以找到特定值,然后顺指针找到包含该值的行。
在数据库关系图中,您可以在选定表的“索引/键”属性页中创建、编辑或删除每个索引类型。当保存索引所附加到的表,或保存该表所在的关系图时,索引将保存在数据库中。有关详细信息,请参见创建索引。
注意;并非所有的数据库都以相同的方式使用索引。有关更多信息,请参见数据库服务器注意事项,或者查阅数据库文档。
作为通用规则,只有当经常查询索引列中的数据时,才需要在表上创建索引。索引占用磁盘空间,并且降低添加、删除和更新行的速度。在多数情况下,索引用于数据检索的速度优势大大超过它的。
索引列
可以基于数据库表中的单列或多列创建索引。多列索引使您可以区分其中一列可能有相同值的行。
如果经常同时搜索两列或多列或按两列或多列排序时,索引也很有帮助。例如,如果经常在同一查询中为姓和名两列设置判据,那么在这两列上创建多列索引将很有意义。
确定索引的有效性:
检查查询的 WHERE 和 JOIN 子句。在任一子句中包括的每一列都是索引可以选择的对象。
对新索引进行试验以检查它对运行查询性能的影响。
考虑已在表上创建的索引数量。最好避免在单个表上有很多索引。
检查已在表上创建的索引的定义。最好避免包含共享列的重叠索引。
检查某列中唯一数据值的数量,并将该数量与表中的行数进行比较。比较的结果就是该列的可选择性,这有助于确定该列是否适合建立索引,如果适合,确定索引的类型。
索引类型
根据数据库的功能,可以在数据库设计器中创建三种索引:唯一索引、主键索引和聚集索引。有关数据库所支持的索引功能的详细信息,请参见数据库文档。
提示:尽管唯一索引有助于定位信息,但为获得最佳性能结果,建议改用主键或唯一约束。
唯一索引
唯一索引是不允许其中任何两行具有相同索引值的索引。
当现有数据中存在重复的键值时,大多数数据库不允许将新创建的唯一索引与表一起保存。数据库还可能防止添加将在表中创建重复键值的新数据。例如,如果在 employee 表中职员的姓 (lname) 上创建了唯一索引,则任何两个员工都不能同姓。
主键索引
数据库表经常有一列或列组合,其值唯一标识表中的每一行。该列称为表的主键。
在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。
聚集索引
在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引。
如果某索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配。与非聚集索引相比,聚集索引通常提供更快的数据访问速度。
建立方式和注意事项
最普通的情况,是为出现在where子句的字段建一个索引。为方便讲述,我们先建立一个如下的表。
CREATE TABLE mytable (
id serial primary key,
category_id int not null default 0,
user_id int not null default 0,
adddate int not null default 0
);
如果你在查询时常用类似以下的语句:
SELECT * FROM mytable WHERE category_id=1;
最直接的应对之道,是为category_id建立一个简单的索引:
CREATE INDEX mytable_categoryid
ON mytable (category_id);
OK.如果你有不止一个选择条件呢?例如:
SELECT * FROM mytable WHERE category_id=1 AND user_id=2;
你的第一反应可能是,再给user_id建立一个索引。不好,这不是一个最佳的方法。你可以建立多重的索引。
CREATE INDEX mytable_categoryid_userid ON mytable (category_id,user_id);
注意到我在命名时的习惯了吗?我使用”表名字段1名字段2名”的方式。你很快就会知道我为什么这样做了。
现在你已经为适当的字段建立了索引,不过,还是有点不放心吧,你可能会问,数据库会真正用到这些索引吗?测试一下就OK,对于大多数的数据库来说,这是很容易的,只要使用EXPLAIN命令:
EXPLAIN
SELECT * FROM mytable
WHERE category_id=1 AND user_id=2;
This is what Postgres 7.1 returns (exactly as I expected)
NOTICE: QUERY PLAN:
Index Scan using mytable_categoryid_userid on
mytable (cost=0.00..2.02 rows=1 width=16)
EXPLAIN
以上是postgres的数据,可以看到该数据库在查询的时候使用了一个索引(一个好开始),而且它使用的是我创建的第二个索引。看到我上面命名的好处了吧,你马上知道它使用适当的索引了。
接着,来个稍微复杂一点的,如果有个ORDER BY字句呢?不管你信不信,大多数的数据库在使用order by的时候,都将会从索引中受益。
SELECT * FROM mytable
WHERE category_id=1 AND user_id=2
ORDER BY adddate DESC;
很简单,就象为where字句中的字段建立一个索引一样,也为ORDER BY的字句中的字段建立一个索引:
CREATE INDEX mytable_categoryid_userid_adddate
ON mytable (category_id,user_id,adddate);
注意: “mytable_categoryid_userid_adddate” 将会被截短为
“mytable_categoryid_userid_addda”
CREATE
EXPLAIN SELECT * FROM mytable
WHERE category_id=1 AND user_id=2
ORDER BY adddate DESC;
NOTICE: QUERY PLAN:
Sort (cost=2.03..2.03 rows=1 width=16)
-> Index Scan using mytable_categoryid_userid_addda
on mytable (cost=0.00..2.02 rows=1 width=16)
EXPLAIN
看看EXPLAIN的输出,数据库多做了一个我们没有要求的排序,这下知道性能如何受损了吧,看来我们对于数据库的自身运作是有点过于乐观了,那么,给数据库多一点提示吧。
为了跳过排序这一步,我们并不需要其它另外的索引,只要将查询语句稍微改一下。这里用的是postgres,我们将给该数据库一个额外的提示–在 ORDER BY语句中,加入where语句中的字段。这只是一个技术上的处理,并不是必须的,因为实际上在另外两个字段上,并不会有任何的排序操作,不过如果加入,postgres将会知道哪些是它应该做的。
EXPLAIN SELECT * FROM mytable
WHERE category_id=1 AND user_id=2
ORDER BY category_id DESC,user_id DESC,adddate DESC;
NOTICE: QUERY PLAN:
Index Scan Backward using
mytable_categoryid_userid_addda on mytable
(cost=0.00..2.02 rows=1 width=16)
EXPLAIN
现在使用我们料想的索引了,而且它还挺聪明,知道可以从索引后面开始读,从而避免了任何的排序。
以上说得细了一点,不过如果你的数据库非常巨大,并且每日的页面请求达上百万算,我想你会获益良多的。不过,如果你要做更为复杂的查询呢,例如将多张表结合起来查询,特别是where限制字句中的字段是来自不止一个表格时,应该怎样处理呢?我通常都尽量避免这种做法,因为这样数据库要将各个表中的东西都结合起来,然后再排除那些不合适的行,搞不好开销会很大。
如果不能避免,你应该查看每张要结合起来的表,并且使用以上的策略来建立索引,然后再用EXPLAIN命令验证一下是否使用了你料想中的索引。如果是的话,就OK。不是的话,你可能要建立临时的表来将他们结合在一起,并且使用适当的索引。
要注意的是,建立太多的索引将会影响更新和插入的速度,因为它需要同样更新每个索引文件。对于一个经常需要更新和插入的表格,就没有必要为一个很少使用的where字句单独建立索引了,对于比较小的表,排序的开销不会很大,也没有必要建立另外的索引。
以上介绍的只是一些十分基本的东西,其实里面的学问也不少,单凭EXPLAIN我们是不能判定该方法是否就是最优化的,每个数据库都有自己的一些优化器,虽然可能还不太完善,但是它们都会在查询时对比过哪种方式较快,在某些情况下,建立索引的话也未必会快,例如索引放在一个不连续的存储空间时,这会增加读磁盘的负担,因此,哪个是最优,应该通过实际的使用环境来检验。
在刚开始的时候,如果表不大,没有必要作索引,我的意见是在需要的时候才作索引,也可用一些命令来优化表,例如MySQL可用”OPTIMIZE TABLE”。
综上所述,在如何为数据库建立恰当的索引方面,你应该有一些基本的概念了。