一、总述
线性回归算法属于监督学习的一种,主要用于模型为连续函数的数值预测。
过程总得来说就是初步建模后,通过训练集合确定模型参数,得到最终预测函数,此时输入自变量即可得到预测值。
二、基本过程
1、初步建模。确定假设函数h(x)(最终预测用)
2、建立价值函数J(θ)(也叫目标函数、损失函数等,求参数θ用)
3、求参数θ。对价值函数求偏导(即梯度),再使用梯度下降算法求出最终参数θ值
4、将参数θ值代入假设函数
三、约定符号
x:自变量,即特征值
y:因变量,即结果
h(x):假设函数
J(θ):价值函数
n:自变量个数,即特征值数量
m:训练集数据条数
α:学习速率,即梯度下降时的步长
四、具体过程
1、初步建模
根据训练集的数据特点创建假设函数,这里我们创建如下基本线性函数

这里需要说明的一点是公式的最后一步,如果把各组参数和自变量组织成矩阵,也可以利用矩阵方式计算。
我们说到矩阵,默认是指的列矩阵。这里先将参数矩阵转置行矩阵,然后就可以和X列矩阵做内积以得结果。
2、建立价值函数
为了让我们的假设函数更好的拟合实际情况,我们可以使用最小二乘法(LMS)建立价值函数,然后将训练集数据代入,然后想办法让该函数的所有结果尽可能小。
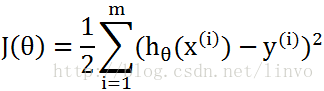
这里前面的1/2只是为了后面求导计算时方便而特地加上的。
怎么让其值尽可能小呢?
方法就是求该价值函数对θ的偏导数,再利用梯度下降算法进行收敛。
3、求参数
使用梯度下降算法,不断修正各θ的值,直到收敛。
判断是否收敛,可以用如下方法:
1、直到θ值变化不再明显(差值小于某给定值);
2、将训练集代入假设函数,判断所有假设函数值之和的变化情况,直到变化不再明显;
3、当然,特殊情况下也可以强制限制迭代次数(可用于最大循环上限,防止死循环)。
下面就是迭代中用到的公式:
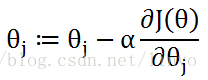
α为学习速率,即每次迭代的步长,如果太小则迭代速度过慢,如果太大则因为跨度太大无法有效找到期望的最小值,该值需要根据实际情况进行调整。
要使用代码实现的话,出现一堆导数可不成,所以要先求最右边的偏导数部分,将价值函数代入:

其实这里参数的数量和自变量的数量是一致的,也就是j=n。
所以梯度下降公式就变成了这样:
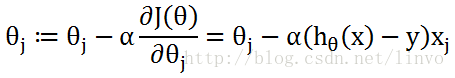
再代入训练集合的话公式就是:
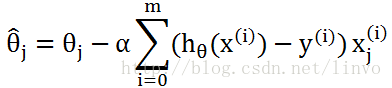
(公式左边theta上面的尖号表示这是期望值)
这就得到了传说中的批量梯度下降算法。
但该算法在训练集合非常大的情况下将会非常低效,因为每次更新theta值时都要将整个训练集的数据代入计算。
所以通常实际情况中会使用改进的增量梯度下降(随机梯度下降)算法:

该算法每次更新只会使用训练集中的一组数据。
这样虽然牺牲了每次迭代时的最优下降路线,但是从整体来看路线还是下降的,只是中间走了写弯路而已,但是效率却大大改善了。
4、得到最终预测函数
将最终的θ值代入最初的假设函数,即得到了最终的预测函数。
五、代码实现
增量梯度下降,Python代码实现:
# -*- coding:utf-8 -*-
"""
增量梯度下降
y=1+0.5x
"""
import sys
# 训练数据集
# 自变量x(x0,x1)
x = [(1,1.15),(1,1.9),(1,3.06),(1,4.66),(1,6.84),(1,7.95)]
# 假设函数 h(x) = theta0*x[0] + theta1*x[1]
# y为理想theta值下的真实函数值
y = [1.37,2.4,3.02,3.06,4.22,5.42]
# 两种终止条件
loop_max = 10000 # 最大迭代次数
epsilon = 0.0001 # 收敛精度
alpha = 0.005 # 步长
diff = 0 # 每一次试验时当前值与理想值的差距
error0 = 0 # 上一次目标函数值之和
error1 = 0 # 当前次目标函数值之和
m = len(x) # 训练数据条数
#init the parameters to zero
theta = [0,0]
count = 0
finish = 0
while count<loop_max:
count += 1
# 遍历训练数据集,不断更新theta值
for i in range(m):
# 训练集代入,计算假设函数值h(x)与真实值y的误差值
diff = (theta[0] + theta[1]*x[i][1]) - y[i]
# 求参数theta,增量梯度下降算法,每次只使用一组训练数据
theta[0] = theta[0] - alpha * diff * x[i][0]
theta[1] = theta[1] - alpha * diff * x[i][1]
# 此时已经遍历了一遍训练集,求出了此时的theta值
# 判断是否已收敛
if abs(theta[0]-error0) < epsilon and abs(theta[1]-error1) < epsilon:
print 'theta:[%f, %f]'%(theta[0],theta[1]),'error1:',error1
finish = 1
else:
error0,error1 = theta
if finish:
break
print 'FINISH count:%s' % counttheta:[1.066522, 0.515434] error1: 0.515449819658
FINISH count:564
理想的真实值θ1=1,θ2=0.5
计算出来的是θ1=1.066522,θ2=0.515434
迭代了564次
需要注意一点,实际过程中需要反复调整收敛精度和学习速率这两个参数,才可得到满意的收敛结果!
另外,如果函数有局部极值问题,则可以将θ随机初始化多次,寻找多个结果,然后从中找最优解。
正规方程法这里先不做讨论了~
-- EOF --