最近很多朋友问我,现在做java和python那个好就业?我这样回答,未来的趋势是大数据很人工智能!
由于自己是做互联网技术研发的,但是2013年6月份改变了我的技术发展方向,那时候接到一个朋友的邀请,说最近他自己公司老是被竞竞争对手在互联网对打进行攻击,经常花钱请网络人员,写一些文章、新闻、微博进行报道他们公司的坏话,让公司的品牌和名声收到很大的影响,只要在百度输入“奶粉事件”或者“xxx公司”他公司名字就排到首页,然后级就是各种负面报道和评价,骂死一片,让他很头疼。问我可不可以研发一套帮舆情监控的系统,对百度新闻、腾讯新闻、新浪新闻、微博等进行采集然后分析、只要发现对他公司负面的文章或者网友评价,就第一时间推送通知给他们公司的风险控制部门经理。于是我就开始研究了爬虫技术。从此也改变了我的技术生涯。
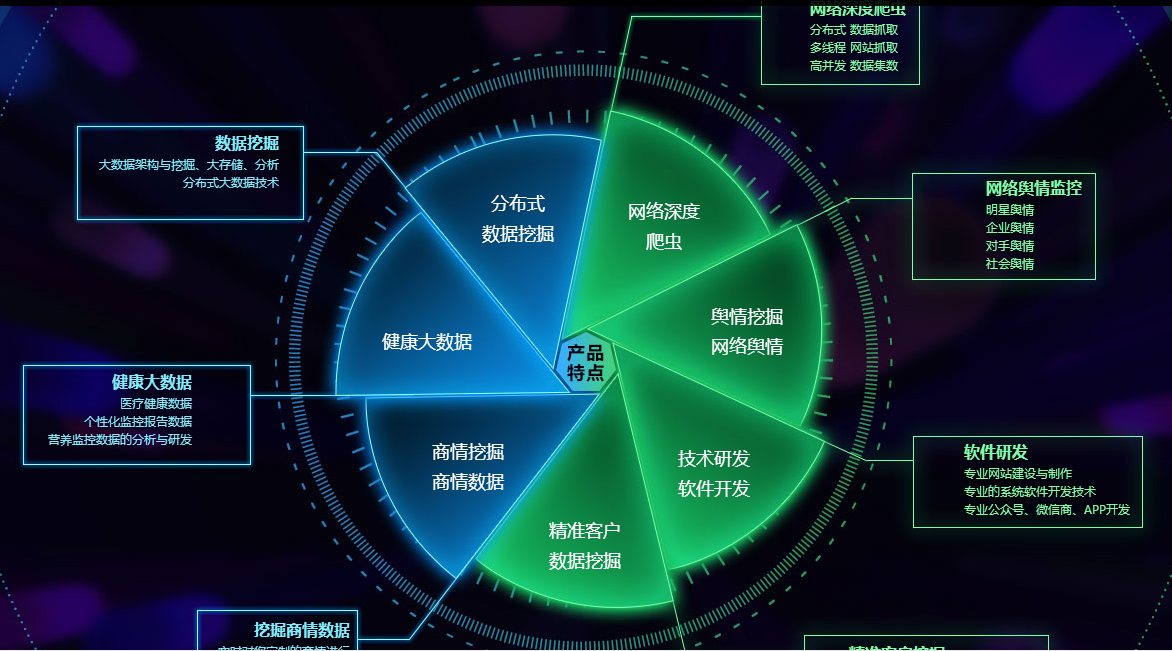
媒体舆情爬虫-千万级数据分布式存储+异步集群多线程采集
我们知道做爬虫数据采集,就是把网站上的数据采集下来然后进行数据存储、数据清洗、数据分析最后形成您的需要的标准数据。首先我们需要确定好目标网站,我们需要爬的是那个网站,同一个网站一半分为手机版和PC版本,我们还需要确定好 我们需要爬的是手机版本的数据 还是PC版本的数据,因为PC和手机版本的数据是有差别不同的,往往手机的数据比较简单,也容易爬一点。再后面就是数据的存储和检索问题,这个舆情数据是采集一个亿的数据量 然后进行分析,这些数据量怎么存储,如果用一台服务器存储 估计查询都是个问题,别说运用了。我们当时采用了5太服务器对这些数据进行分布式存储,分表分区存储。数据量非常大的时候,数据达到几十亿,我们平时搜索查询某个词 是搜不出来的,数据库肯定是卡死崩溃掉了,这个时候就不能用普通的like模糊查询了,我们得需要用搜索引擎,自己搭建一套分布式多线程搜索引擎解决海量数据的搜索问题。
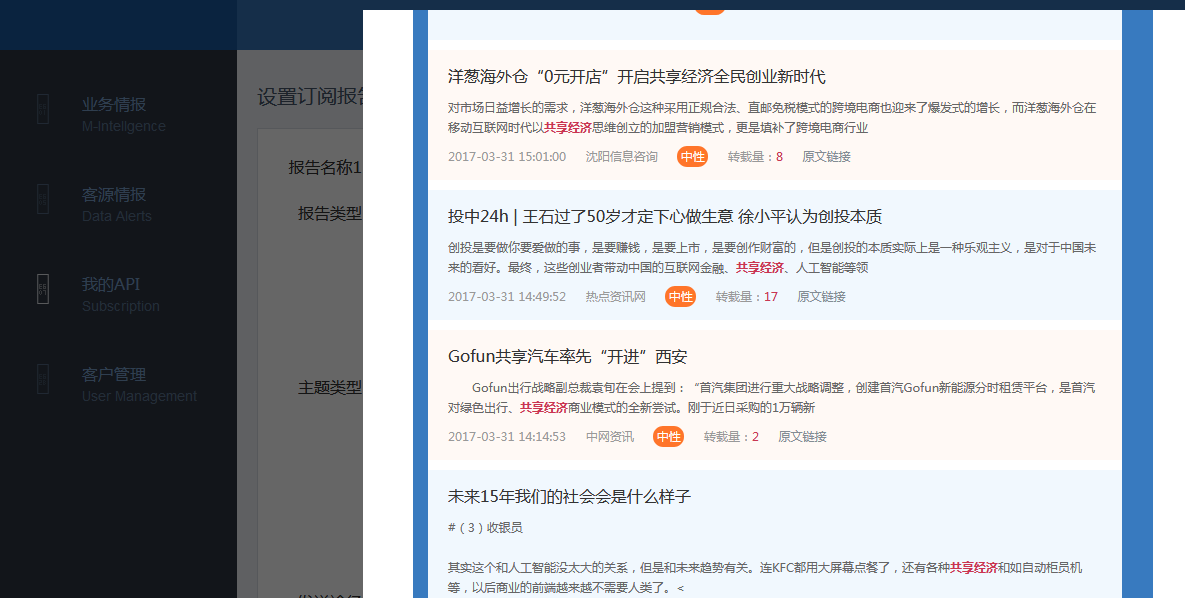
舆情爬虫监控系统
工商企业数据-企信宝-天眼查-企查查360度深度分布式爬虫
我们知道很多公司做爬工商的数据作为大项目来运作而且挣了大钱,比如 “企信宝”、“企查查”、“天眼查”等企业,都是做数据起来的,数据的价值是非常大的。第一次爬工商数据的时候 面临的第一个问题就是破解验证码,工商网站做了非常严格的安全控制,每次查询都需输入验证码,而且2017年引进了第二代极速验证码,让我们技术难度又增加了很多,工商的数据有几个亿的数据量,要把这些数据在一个月内跑完 需要足够多的服务器和代理IP ,同时还需要足够好的带宽。当时采用了10太服务器集群,把写好python爬虫部署到各个节点上,数据的时候爬起和监控,需要采用异步处理方式。减去服务器压力,提高爬虫的性能。最后采用python+phantomjs+php+分布式+多线程技术 一个月内把企信宝 的数据全部爬下来了,包括每个企业的商标数据、软著数据、法人数据、股东数据、司法风险数据、舆情数据、人才招聘数据、产品数据、信用评级数据等。这一路来 特别艰难,各种反爬技术的攻克。
爬虫的维度包括很多,比如:

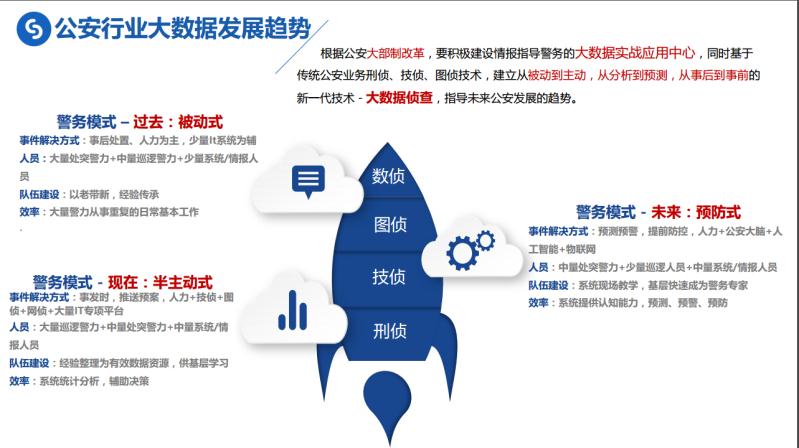
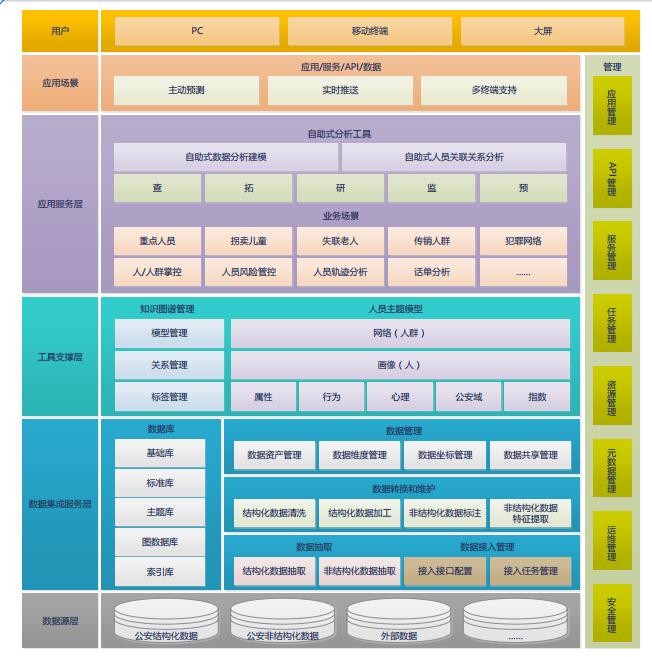
爬虫顶级颠覆-国家公安互联网反恐大数据挖掘
爬虫和黑客的区别就是,爬虫是做好事,黑客是做坏事,最近一次秘密帮助公安做了很多数据输出的接口,互联网反恐大数据挖掘分析、监控各种网络犯罪分子,做了很多数据维度的关联和挖掘。
其他爬虫:
其他各种金融客户爬虫、菁忧网题库爬虫、飞猪网爬虫、1688供应商爬虫技术各不同等。需要爬虫技术和大数据交流朋友加我qq:2779571288