final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;//node 存储值的数据结构
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length; // 初始化长度
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);//根据hash值计算值卡槽(值所在hashmap的位置)
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) //hash值相同key地址相同 或key的值相等
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) { //p为hash值相等的链表最后一个元素
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}我们知道,对象Hash的前提是实现equals()和hashCode()两个方法,那么HashCode()的作用就是保证对象返回唯一hash值,但当两个对象计算值一样时,这就发生了碰撞冲突。如下将介绍如何处理冲突,其前提是一致性hash。
1.开放地址法
开放地执法有一个公式:Hi=(H(key)+di) MOD m i=1,2,…,k(k<=m-1) 其中,m为哈希表的表长。di 是产生冲突的时候的增量序列。如果di值可能为1,2,3,…m-1,称线性探测再散列。
(1) 如果di取1,则每次冲突之后,向后移动1个位置.如果di取值可能为1,-1,2,-2,4,-4,9,-9,16,-16,…k*k,-k*k(k<=m/2),称二次探测再散列。
(2)如果di取值可能为伪随机数列。称伪随机探测再散列。
2.再哈希法
当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。 比如上面第一次按照姓首字母进行哈希,如果产生冲突可以按照姓字母首字母第二位进行哈希,再冲突,第三位,直到不冲突为止。
3.链地址法(拉链法)
将所有关键字为同义词的记录存储在同一线性链表中。如下:
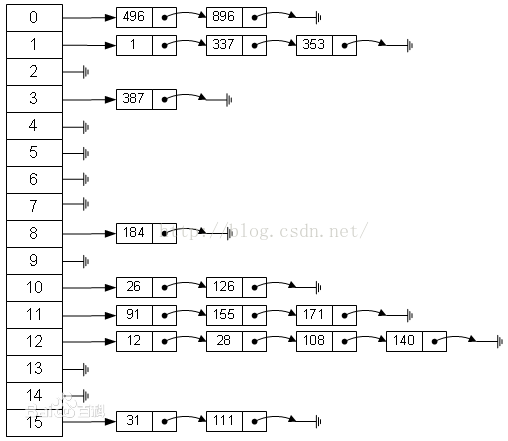
4.建立一个公共溢出区
假设哈希函数的值域为[0,m-1],则设向量HashTable[0..m-1]为基本表,另外设立存储空间向量OverTable[0..v]用以存储发生冲突的记录。