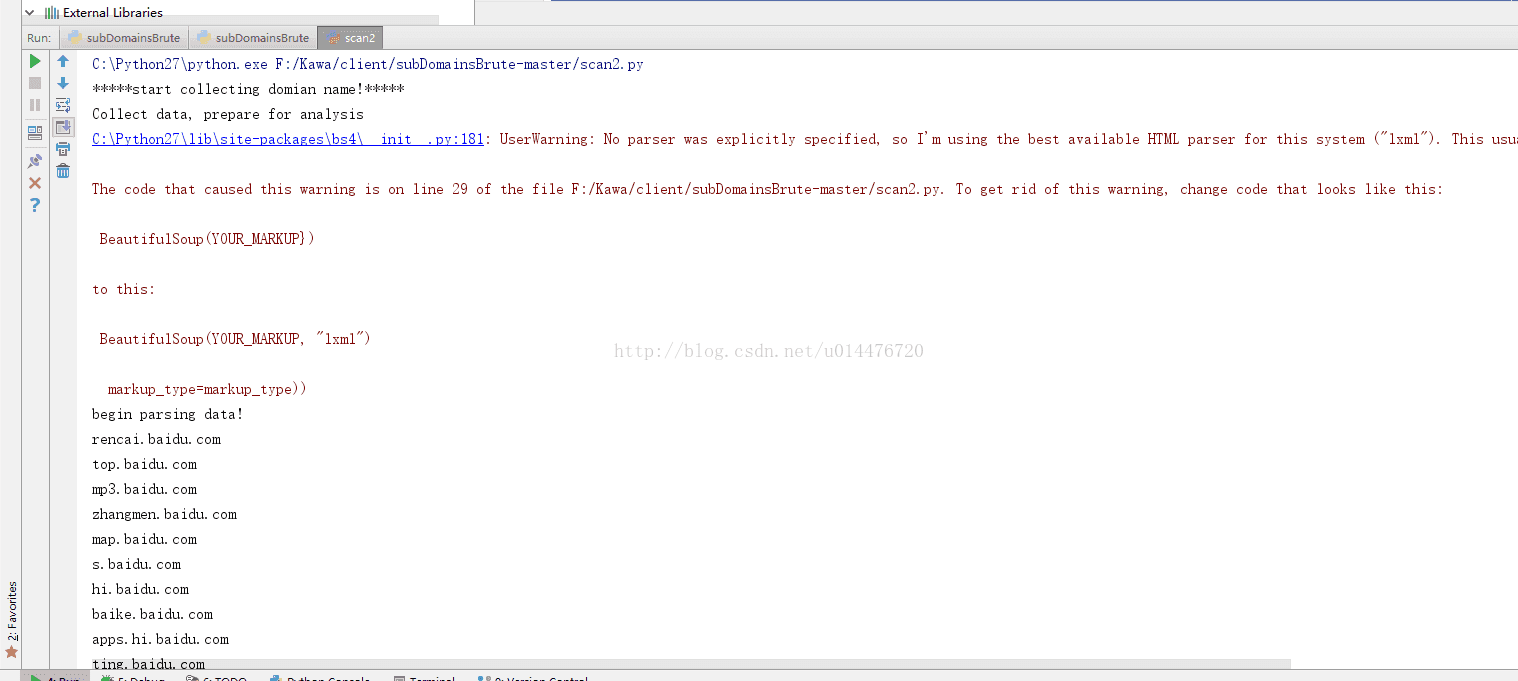
这个工具是用python写的,由于本人擅长的不是这个,只是业余,所以能用就过了,不像写其他语言那样要求精简了,下面是主要的代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import re
import urllib2
from bs4 import BeautifulSoup as bs
def scan_domain(submain):
url_360 = 'http://webscan.360.cn/sub/index/?url=%s' % submain
html = urllib2.urlopen(url_360).read()
print "Collect data, prepare for analysis "
soup = bs(html)
print "begin parsing data! "
for i in soup.find_all(name="div", attrs={"id": "sub_conlist"}):
one = i.find_all('strong')
for row in one:
res_td = r'>(.*?)</strong>'
language = '''''%s''' % row
m_td = re.findall(res_td, language)
for nn in m_td:
print unicode(nn, 'utf-8')
if __name__ == '__main__':
domain = "baidu.com"
print '*****start collecting domian name!*****'
scan_domain(domain)
print '*****collect domian name over!*****'
我都是在环境上面运行,过程有一点报错,但是不影响结果,所以我就没管了,其实过程主要还是利用了360网站安全检测,里面有收录到的都能列举出来,没收录的就查询不了