原文地址:https://blog.csdn.net/jiutianhe/article/details/40111791
1. 用Mahout实现协同过滤userCF
Mahout协同过滤UserCF深度算法剖析,请参考文章:用R解析Mahout用户推荐协同过滤算法(UserCF)
实现步骤:(1)准备数据文件: item.csv;(2)编写Java程序:UserCF.java;(3)运行程序
(1)数据文件:datafile/item.csv(数据解读:每一行有三列,第一列是用户ID,第二列是物品ID,第三列是用户对物品的打分)
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0(2)Java程序:UserCF.java
Mahout协同过滤的数据流,调用过程(摘自:Mahout in Action)。
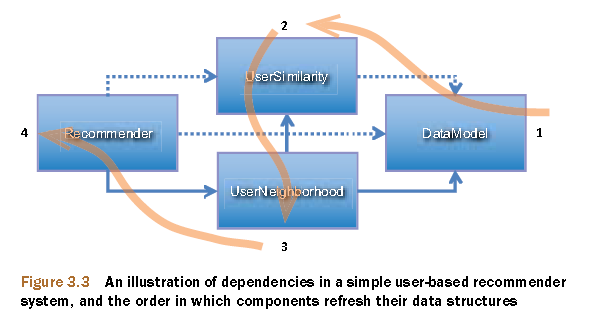
新建JAVA类:org.conan.mymahout.recommendation.UserCF.java
package org.conan.mymahout.recommendation;
import java.io.File;
import java.io.IOException;
import java.util.List;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.impl.model.file.FileDataModel;
import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood;
import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender;
import org.apache.mahout.cf.taste.impl.similarity.EuclideanDistanceSimilarity;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.cf.taste.recommender.Recommender;
import org.apache.mahout.cf.taste.similarity.UserSimilarity;
public class UserCF {
final static int NEIGHBORHOOD_NUM = 2;
final static int RECOMMENDER_NUM = 3;
public static void main(String[] args) throws IOException, TasteException {
String file = "datafile/item.csv";
DataModel model = new FileDataModel(new File(file));
UserSimilarity user = new EuclideanDistanceSimilarity(model);
NearestNUserNeighborhood neighbor = new NearestNUserNeighborhood(NEIGHBORHOOD_NUM, user, model);
Recommender r = new GenericUserBasedRecommender(model, neighbor, user);
LongPrimitiveIterator iter = model.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = r.recommend(uid, RECOMMENDER_NUM);
System.out.printf("uid:%s", uid);
for (RecommendedItem ritem : list) {
System.out.printf("(%s,%f)", ritem.getItemID(), ritem.getValue());
}
System.out.println();
}
}
}(3)运行程序,控制台输出:
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
uid:1(104,4.274336)(106,4.000000)
uid:2(105,4.055916)
uid:3(103,3.360987)(102,2.773169)
uid:4(102,3.000000)
uid:52. 用Mahout实现kmeans
- 1. 准备数据文件: randomData.csv
- 2. Java程序:Kmeans.java
- 3. 运行Java程序
- 4. mahout结果解读
- 5. 用R语言实现Kmeans算法
- 6. 比较Mahout和R的结果
(1)准备数据文件:datafile/randomData.csv(部分数据摘要,随机生成)
-0.883033363823402,-3.31967192630249
-2.39312626419456,3.34726861118871
2.66976353341256,1.85144276077058
-1.09922906899594,-6.06261735207489
-4.36361936997216,1.90509905380532
-0.00351835125495037,-0.610105996559153
-2.9962958796338,-3.60959839525735
-3.27529418132066,0.0230099799641799
2.17665594420569,6.77290756817957
-2.47862038335637,2.53431833167278
5.53654901906814,2.65089785582474
5.66257474538338,6.86783609641077
-0.558946883114376,1.22332819416237
5.11728525486132,3.74663871584768
1.91240516693351,2.95874731384062
-2.49747101306535,2.05006504756875
3.98781883213459,1.00780938946366(2)Java程序:Kmeans.java,Mahout中kmeans方法的算法实现过程如下图(摘自:Mahout in Action)
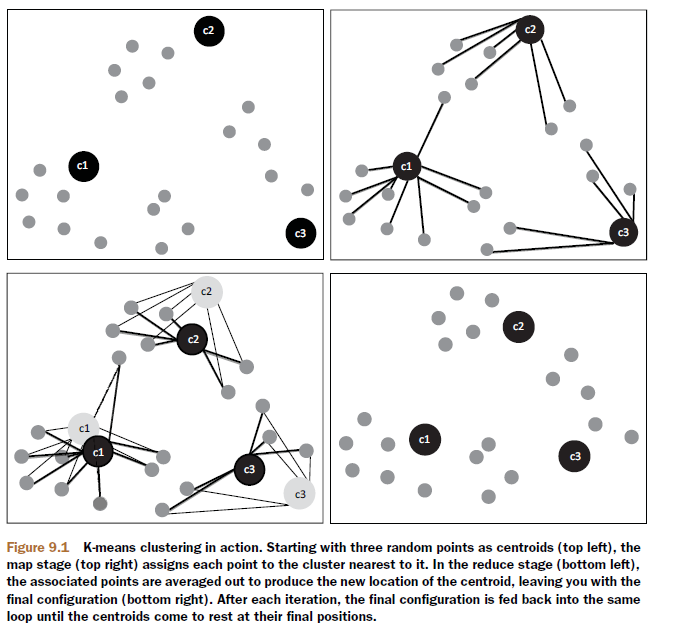
新建JAVA类:org.conan.mymahout.cluster06.Kmeans.java
package org.conan.mymahout.cluster06;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.mahout.clustering.kmeans.Cluster;
import org.apache.mahout.clustering.kmeans.KMeansClusterer;
import org.apache.mahout.common.distance.EuclideanDistanceMeasure;
import org.apache.mahout.math.Vector;
public class Kmeans {
public static void main(String[] args) throws IOException {
List sampleData = MathUtil.readFileToVector("datafile/randomData.csv");
int k = 3;
double threshold = 0.01;
List randomPoints = MathUtil.chooseRandomPoints(sampleData, k);
for (Vector vector : randomPoints) {
System.out.println("Init Point center: " + vector);
}
List clusters = new ArrayList();
for (int i = 0; i < k; i++) {
clusters.add(new Cluster(randomPoints.get(i), i, new EuclideanDistanceMeasure()));
}
List<List> finalClusters = KMeansClusterer.clusterPoints(sampleData, clusters, new EuclideanDistanceMeasure(), k, threshold);
for (Cluster cluster : finalClusters.get(finalClusters.size() - 1)) {
System.out.println("Cluster id: " + cluster.getId() + " center: " + cluster.getCenter().asFormatString());
}
}
}(3)运行Java程序,控制台输出如下,其中, Init Point center表示,kmeans算法初始时的设置的3个中心点;Cluster center表示,聚类后找到3个中心点。
Init Point center: {0:-0.162693685149196,1:2.19951550286862}
Init Point center: {0:-0.0409782183083317,1:2.09376666042057}
Init Point center: {0:0.158401778474687,1:2.37208412905273}
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
Cluster id: 0 center: {0:-2.686856800552941,1:1.8939462954763795}
Cluster id: 1 center: {0:0.6334255423230666,1:0.49472852972602105}
Cluster id: 2 center: {0:3.334520309711998,1:3.2758355898247653}(4)用R语言实现Kmeans算法:接下来为了让结果更直观,我们再用R语言,进行kmeans实验,操作相同的数据。
> y<-read.csv(file="randomData.csv",sep=",",header=FALSE)
> cl<-kmeans(y,3,iter.max = 10, nstart = 25)
> cl$centers
V1 V2
1 -0.4323971 2.2852949
2 0.9023786 -0.7011153
3 4.3725463 2.4622609
# 生成聚类中心的图形
> plot(y, col=c("black","blue","green")[cl$cluster])
> points(cl$centers, col="red", pch = 19)
# 画出Mahout聚类的中心
> mahout<-matrix(c(-2.686856800552941,1.8939462954763795,0.6334255423230666,0.49472852972602105,3.334520309711998,3.2758355898247653),ncol=2,byrow=TRUE)
> points(mahout, col="violetred", pch = 19)聚类的效果图: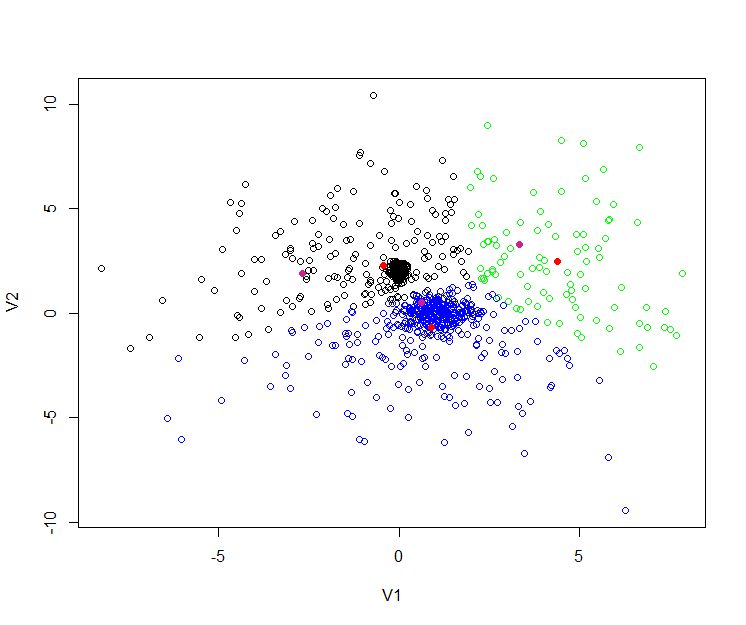
(5)比较Mahout和R的结果
从上图中,我们看到有 黑,蓝,绿,三种颜色的空心点,这些点就是原始的数据。
3个红色实点,是R语言kmeans后生成的3个中心。
3个紫色实点,是Mahout的kmeans后生成的3个中心。
R语言和Mahout生成的点,并不是重合的,原因有几点:
(1)距离算法不一样:Mahout中用的是欧氏距离,R语言中默认是”Hartigan and Wong”;
(2)初始化的中心不同;
(3)最大迭代次数也是不同的;
(4)点合并时,判断的”阈值(threshold)”是不一样的。