一、卷积神经网络的一些基本概念:
局部感受野(local receptive fields)
权值共享(Shared weights and biases)
1、局部感知野:一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。
局部连接:通过卷积操作,把全连接变成局部连接 ,因为多层网络能够抽取高阶统计特性, 即使网络为局部连接,由于格外的突触连接和额外的神经交互作用,也可以使网络在不十分严格的意义下获得一个全局关系。
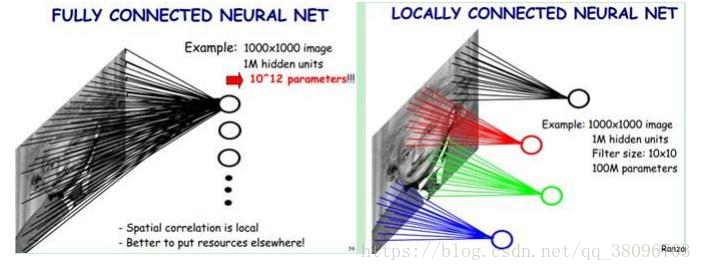
2、权值共享:我们把卷积核(下面滑动的窗口)里面那些数字叫做权重,是可以学习的。我们要学习的就是窗口里面的那些数字,而这些数字对于一幅图来说都是相同的。同样,一个卷积核(滑动窗口)都是带一个偏置的,同样的,偏置在整幅图上面也是一样的。
二、基本结构
卷积神经网络的各层中的神经元是3维排列的:宽度、高度和深度
这里先解释下:一开始的时候我们讲深度,更多的是指代的神经网络的层数,在卷积层这里我们讲深度指的是数据或者filter的第三个维度。
一般最基本的卷积神经网络的架构可以是:
[输入层-卷积层-ReLU层-池化层-全连接层]
卷积层:
肯定是卷积网络中最重要的一层啦,毕竟叫做卷积神经网络。 卷积层的参数是有一些可学习的滤波器集合(前面提到得滑动窗口)构成的。
一个卷积核在输入图上面滑动(见前面的动图)可以生成一个activation map,不同的卷积核(filter)能够得到不同的激活图,将这些激活映射在深度方向上层叠起来就生成了输出数据。
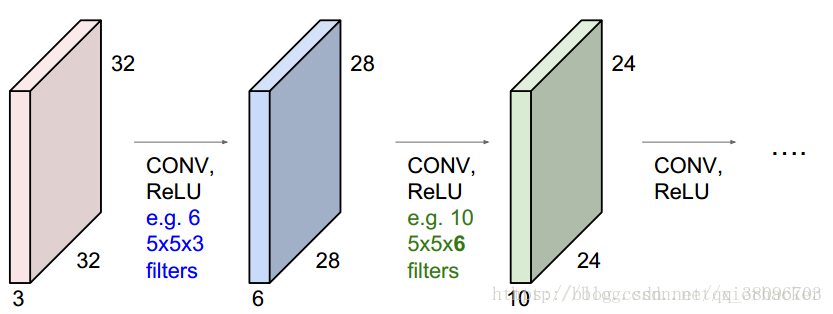
上图中,输入是32x32x3,用了6个5x5x3的滤波器,前面说过,滤波器的宽高尺寸自己定,深度为3是因为必须和输入的数据一样,用了6个滤波器,意味着接下来得到的激活图的深度是6维的。所以,接下来的激活图的尺寸为28x28x6。然后这个激活图作为输入,用了10个5x5x6的滤波器,还是那句话,滤波器的宽高尺寸自己定,但是深度为6是因为输入的深度是6,10个滤波器意味着得到的激活图的深度是6维的,即得到24x24x10.
这里给出一个通用的输出尺寸的计算公式: 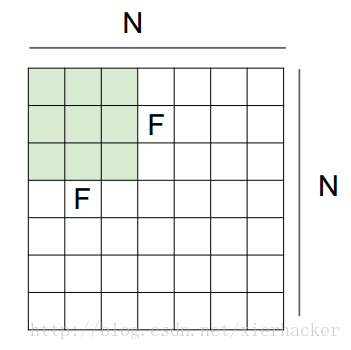
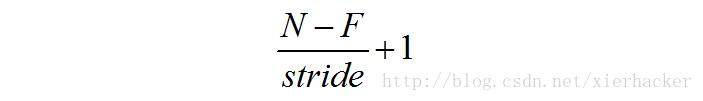
但是有一个问题,每经过一个filter,得到的激活图就会小一些,要是多经过几个,那岂不是最后什么都不见啦?
所以解决的办法就叫做零填充(zero padding),其实很简单啦,就是在输入上面填充一圈或者几圈的0,就这么简单。
那么你会发现,N变为了N+p*2 (这里p代表圈数)为什么p乘以2呢,因为加了一圈之后两侧都加了1啊。所以N+p*2 ,那么得到新的公式为: 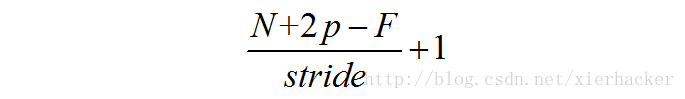
这个公式表示,相应原输入尺寸,步长,框口尺寸下面,加圈后得到的输出尺寸。
参数数量:主要是滤波器的权重和偏置。10个5*5的滤波器,一个滤波器的话就是5*5*3+1=76个,因为有10个滤波器,那么一共有10*76=760个.
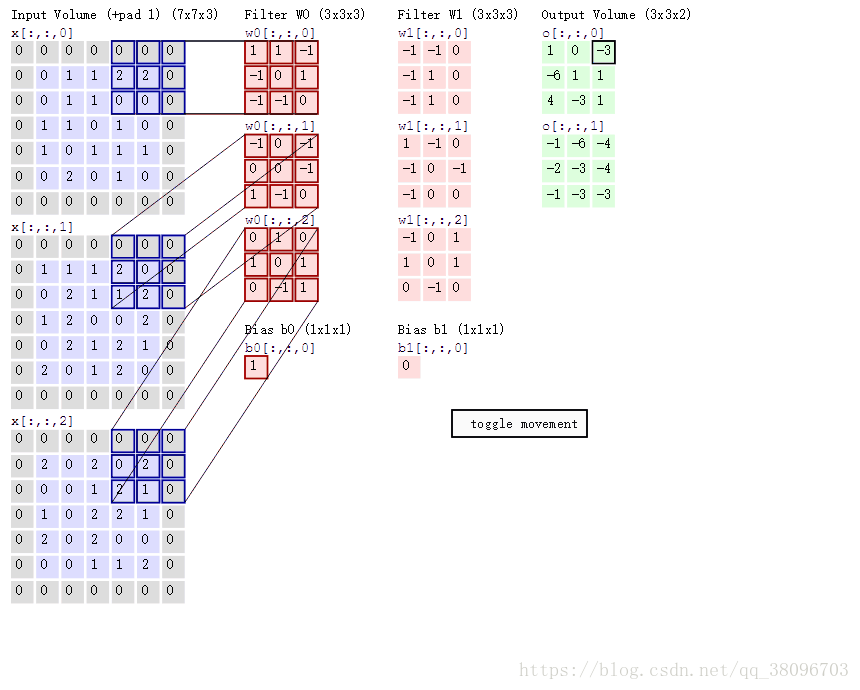
回到上面那个图,第一个滤波器的不同深度的分量和输入数据相应深度的分量分别做卷积操作。
具体来说就是:
对于x[:,:,0] 的那一小块和w0[:,:,0]做卷积:即 (0*1)+(0*0)+(0*0)+(0*1)+(1*0)+(2*0)+(0*-1)+(2*0)+(0*1)=0
对于x[:,:,1] 的那一小块和w0[:,:,1]做卷积:即 (0*1)+(0*-1)+(0*1)+(0*-1)+(1*-1)+(1*0)+(0*-1)+(2*0)+(1*1)=0
对于x[:,:,2] 的那一小块和w0[:,:,2]做卷积:即 (0*1)+(0*-1)+(0*-1)+(0*1)+(0*1)+(1*1)+(0*0)+(1*-1)+(1*0)=0
最后结果为0+0+0+1=1
池化层:
池化层的作用就是减少feature map的空间尺寸,达到减少参数进一步达到控制过拟合的作用。
具体作用:
1. 特征不变性,也就是我们在图像处理中经常提到的特征的尺度不变性,池化操作就是图像的resize,平时一张狗的图像被缩小了一倍我们还能认出这是一张狗的照片,这说明这张图像中仍保留着狗最重要的特征,我们一看就能判断图像中画的是一只狗,图像压缩时去掉的信息只是一些无关紧要的信息,而留下的信息则是具有尺度不变性的特征,是最能表达图像的特征。
2. 特征降维,我们知道一幅图像含有的信息是很大的,特征也很多,但是有些信息对于我们做图像任务时没有太多用途或者有重复,我们可以把这类冗余信息去除,把最重要的特征抽取出来,这也是池化操作的一大作用。
3. 在一定程度上防止过拟合,更方便优化。
这里再展开叙述池化层的具体作用。
1. 特征不变性,也就是我们在图像处理中经常提到的特征的尺度不变性,池化操作就是图像的resize,平时一张狗的图像被缩小了一倍我们还能认出这是一张狗的照片,这说明这张图像中仍保留着狗最重要的特征,我们一看就能判断图像中画的是一只狗,图像压缩时去掉的信息只是一些无关紧要的信息,而留下的信息则是具有尺度不变性的特征,是最能表达图像的特征。
2. 特征降维,我们知道一幅图像含有的信息是很大的,特征也很多,但是有些信息对于我们做图像任务时没有太多用途或者有重复,我们可以把这类冗余信息去除,把最重要的特征抽取出来,这也是池化操作的一大作用。
3. 在一定程度上防止过拟合,更方便优化。
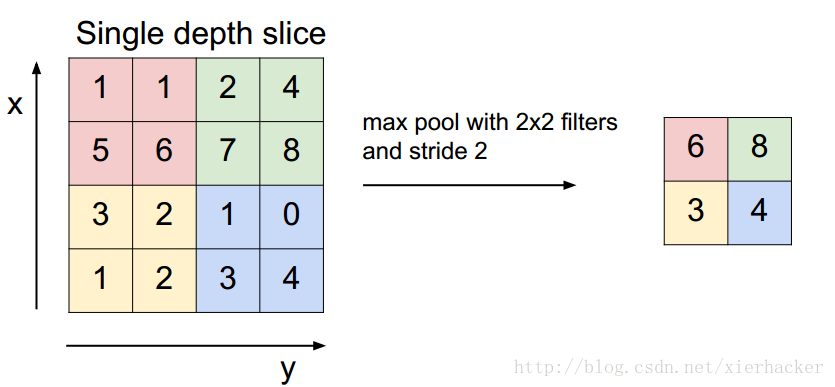
现在常用的pooling 操作有max pooling(最大值pooling)或者average pooling(平均值pooling)等等,以max pooling为例
全连接层
两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部。也就是跟传统的神经网络神经元的连接方式是一样的:

Softmax层:
Softmax层主要用于分类问题,通过Softmax层,可以得到当前样例属于不同种类的概率分布情况。
一般CNN结构依次为
1. INPUT
2. [[CONV -> RELU]*N -> POOL?]*M
3. [FC -> RELU]*K
4. FC
卷积神经网络之训练算法
1. 同一般机器学习算法,先定义Loss function,衡量和实际结果之间差距。
2. 找到最小化损失函数的W和b, CNN中用的算法是SGD(随机梯度下降)。
卷积神经网络之优缺点
优点
• 共享卷积核,对高维数据处理无压力
• 无需手动选取特征,训练好权重,即得特征分类效果好
缺点
• 需要调参,需要大样本量,训练最好要GPU
• 物理含义不明确(也就说,我们并不知道没个卷积层到底提取到的是什么特征,而且神经网络本身就是一种难以解释的“黑箱模型”)
卷积神经网络之典型CNN
• LeNet,这是最早用于数字识别的CNN
• AlexNet, 2012 ILSVRC比赛远超第2名的CNN,比
• LeNet更深,用多层小卷积层叠加替换单大卷积层。
• ZF Net, 2013 ILSVRC比赛冠军
• GoogLeNet, 2014 ILSVRC比赛冠军
• VGGNet, 2014 ILSVRC比赛中的模型,图像识别略差于GoogLeNet,但是在很多图像转化学习问题(比如object detection)上效果奇好
卷积神经网络之 fine-tuning
何谓fine-tuning?
fine-tuning就是使用已用于其他目标、预训练好模型的权重或者部分权重,作为初始值开始训练。
那为什么我们不用随机选取选几个数作为权重初始值?原因很简单,第一,自己从头训练卷积神经网络容易出现问题;第二,fine-tuning能很快收敛到一个较理想的状态,省时又省心。
那fine-tuning的具体做法是?
• 复用相同层的权重,新定义层取随机权重初始值
• 调大新定义层的的学习率,调小复用层学习率