1.什么是多线程?
多线程(英语:multithreading),是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提升整体处理性能。多线程是为了同步完成多项任务,不是为了提高运行效率,而是为了提高资源使用效率来提高系统的效率。
1)单进程单线程:一个人在一个桌子上吃菜。
2)单进程多线程:多个人在同一个桌子上一起吃菜。
3)多进程单线程:多个人每个人在自己的桌子上吃菜。
多线程的问题是多个人同时吃一道菜的时候容易发生争抢,例如两个人同时夹一个菜,一个人刚伸出筷子,结果伸到的时候已经被夹走菜了。。。此时就必须等一个人夹一口之后,在还给另外一个人夹菜,也就是说资源共享就会发生冲突争抢。
2.OpenMP并行程序
一个最为简单的OpenMP代码如下所示:(OpenMP运行时需要在“配置属性”--“C/C++”--"语言"中选择支持OpenMP即可,头文件加上#include<omp.h>)
#include <iostream>
#include <time.h>
using namespace std;
int main()
{
clock_t t1, t2;
t1 = clock();
#pragma omp parallel for
for (int i = 0; i < 10; i++)
{
cout << "i = " << i << endl;
}
t2 = clock();
cout << "花费时间为" << double(t2 - t1) / CLOCKS_PER_SEC << "s" << endl;
system("pause");
}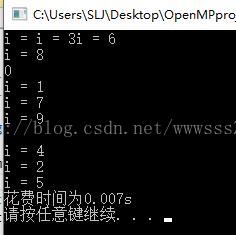

很显然左图是并行运算的结果,右图是没有并行运算的结果,但是为什么并行运算反而花费时间多,
原因是把时间花在开启线程上了。才10个打印序列,本身打印所花费的时间并不多。
还需要说明的一个问题是:#pragma omp parallel for 这条语句是用来指定后面的for循环语句变成并行执行的。当然for循环里的内容必须满足可以并行执行,即每次互不相干,后一次循环不依赖于前面的循环。
3.OpenMP程序设计
下面来举几个竞态(race condition)的问题,这是所有多线程编程中比较棘手的问题。当多个线程并行执行时候,有可能多个线程同时对某个变量进行读写操作,从而导致不可预知的结果。摘自如下博客http://www.cnblogs.com/liangliangdetianxia/p/4032659.html。如下面的一个例程:
#pragma omp parallel for
for (int i = 0; i < 100000; i++)
{
sum = sum + a[i % 10];
}
cout << "sum= " << sum << endl; int a[10] = {1,2,3,4,5,6,7,8,9,10};
int sum = 0;
#pragma omp parallel for reduction(+:sum)
for (int i = 0; i < 100000; i++)
{
sum = sum + a[i % 10];
} int max = 0;
int a[10] = { 11,2,33,4,113,20,321,250,689,16 };
#pragma omp parallel for
for (int i = 0; i < 10; i++)
{
int temp = a[i];
#pragma omp critical
{
if (temp > max)
max = temp;
}
}
cout << "max: " << max << endl;
故之前的代码也可以等价为:
int sum = 0;
int a[10] = { 1,2,3,4,5,6,7,8,9,10 };
#pragma omp parallel for
for (int i = 0; i < 10; i++)
{
#pragma omp critical
{
sum = sum + a[i];
}
}
cout << "sum = " << sum << endl;